0x99DaDa
用户暂无简介
0x99DaDa
老美真的要开始回归门罗主义吗?
为啥对委内瑞拉这么上心?
为啥对委内瑞拉这么上心?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
憋了这么久,感觉春节期间应该有一波小行情。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
2026年,我的杞人忧天
2026 年将近,我越来越频繁地冒出一些可能并不成熟、甚至有点多余的想法。
它们谈不上结论,也算不上判断,更不是要去证明什么,只是一种在这个时间点反复出现的不安。
也许是我想多了,也许只是杞人忧天。
但既然这些念头总是挥之不去,我还是想把它们写下来。
有兴趣的,就交流;
没兴趣的,就拉倒。
一、人之所以重要,曾经只是因为“有用”
在人类历史的大多数阶段,一个人无论多么有钱、多么有权,都无法脱离他人独立存在。
财富需要人去创造,
权力需要人去执行,
社会的运转本身,离不开大量普通而具体的人。
所以才会有那句俗话:“皇帝死了,也要人抬棺材。”
这句话说的并不是尊严,而是一种朴素却坚固的现实——
人总归是有用的。
但这种“有用”,并不是天赋的,而是结构性的。
它建立在一个前提之上:世界离不开人。
二、AI 和自动化,第一次在动摇这个前提
随着 AI 和自动化技术的发展,我越来越强烈地感受到一个变化:
不是某些岗位会被替代,
而是 “人是否仍然不可替代” 这个前提,正在被动摇。
纵观世界,几乎没有哪个行业能拍着胸脯说自己一定安全。
生产、管理、分析、创作、决策……
替代的边界在不断外扩。
过去,人们常说人类还有“情绪价值”和“生理需求”这两张底牌。
但如果我们暂时放下“必须是一个活生生的人”这种执念,会发现一个不太舒服的事实:
在很多场景里,
AI 反而可能是更稳
2026 年将近,我越来越频繁地冒出一些可能并不成熟、甚至有点多余的想法。
它们谈不上结论,也算不上判断,更不是要去证明什么,只是一种在这个时间点反复出现的不安。
也许是我想多了,也许只是杞人忧天。
但既然这些念头总是挥之不去,我还是想把它们写下来。
有兴趣的,就交流;
没兴趣的,就拉倒。
一、人之所以重要,曾经只是因为“有用”
在人类历史的大多数阶段,一个人无论多么有钱、多么有权,都无法脱离他人独立存在。
财富需要人去创造,
权力需要人去执行,
社会的运转本身,离不开大量普通而具体的人。
所以才会有那句俗话:“皇帝死了,也要人抬棺材。”
这句话说的并不是尊严,而是一种朴素却坚固的现实——
人总归是有用的。
但这种“有用”,并不是天赋的,而是结构性的。
它建立在一个前提之上:世界离不开人。
二、AI 和自动化,第一次在动摇这个前提
随着 AI 和自动化技术的发展,我越来越强烈地感受到一个变化:
不是某些岗位会被替代,
而是 “人是否仍然不可替代” 这个前提,正在被动摇。
纵观世界,几乎没有哪个行业能拍着胸脯说自己一定安全。
生产、管理、分析、创作、决策……
替代的边界在不断外扩。
过去,人们常说人类还有“情绪价值”和“生理需求”这两张底牌。
但如果我们暂时放下“必须是一个活生生的人”这种执念,会发现一个不太舒服的事实:
在很多场景里,
AI 反而可能是更稳

- 赞赏
- 点赞
- 评论
- 转发
- 分享
感恩这个世界,
感恩 Web3,
感恩生命中遇到的每一个人。
偶尔回望一路走来,虽然没有大富大贵,但大多时候也都算心想事成。那些曾经以为跨不过去的坎,最终都在努力中找到了解法;那些放不下的心结,也慢慢学会了释怀。
人生是一场奇妙的际遇。
不必苛求,也无需焦虑。
“一切都是最好的安排”
如果当下觉得还不够好,那就继续走,继续努力,把它变成最好的样子。
迟到的感恩节,也依然值得感恩。
愿我们都能带着力量和温柔,继续向前。
感恩 Web3,
感恩生命中遇到的每一个人。
偶尔回望一路走来,虽然没有大富大贵,但大多时候也都算心想事成。那些曾经以为跨不过去的坎,最终都在努力中找到了解法;那些放不下的心结,也慢慢学会了释怀。
人生是一场奇妙的际遇。
不必苛求,也无需焦虑。
“一切都是最好的安排”
如果当下觉得还不够好,那就继续走,继续努力,把它变成最好的样子。
迟到的感恩节,也依然值得感恩。
愿我们都能带着力量和温柔,继续向前。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
【 $JST 通缩背后的信号:#TRON# DeFi 正在完成“价值回归” 】
在经历数年的高速扩张之后,加密世界开始进入一次深度的“价值回归”周期。过去那些依靠通胀激励、空投炒作维系热度的 DeFi 项目正在逐渐式微,而以真实收益支撑代币价值的“可持续模型”正在崛起。JST 的首次大规模回购与销毁,正是这一转变的标志性事件——它不仅是 TRON DeFi 的一次机制革新,更是整个行业走向理性与内生增长的信号。
一、通缩不是噱头,而是真实盈利的证明
10 月 21 日,#JustLend DAO 正式执行 JST 回购与销毁机制,使用 1772 万 USDT 回购并销毁 5.6 亿枚 JST,占总供应量的 5.6%。这不是某种“象征性”动作,而是一场以 真实生态盈利 为支撑的通缩行动。
JustLend DAO 的累计收益已突破 5900 万 USDT,剩余 70% 的存量收益(约 4140 万 USDT)将分四个季度持续销毁。同时,USDD 生态的多链收益在突破 1000 万美元门槛后,也将注入回购池中。
这意味着 JST 的销毁机制并非一次性刺激,而是一个 由利润驱动的通缩周期——每个季度的生态收入都会转化为实质性的销毁行为,从而形成长期、可持续的正反馈结构。
二、TRON 的“金融引擎”:让 DeFi 回到现金流逻辑
过去的 DeFi 世界里,“增长”往往意味着“通胀”——发
在经历数年的高速扩张之后,加密世界开始进入一次深度的“价值回归”周期。过去那些依靠通胀激励、空投炒作维系热度的 DeFi 项目正在逐渐式微,而以真实收益支撑代币价值的“可持续模型”正在崛起。JST 的首次大规模回购与销毁,正是这一转变的标志性事件——它不仅是 TRON DeFi 的一次机制革新,更是整个行业走向理性与内生增长的信号。
一、通缩不是噱头,而是真实盈利的证明
10 月 21 日,#JustLend DAO 正式执行 JST 回购与销毁机制,使用 1772 万 USDT 回购并销毁 5.6 亿枚 JST,占总供应量的 5.6%。这不是某种“象征性”动作,而是一场以 真实生态盈利 为支撑的通缩行动。
JustLend DAO 的累计收益已突破 5900 万 USDT,剩余 70% 的存量收益(约 4140 万 USDT)将分四个季度持续销毁。同时,USDD 生态的多链收益在突破 1000 万美元门槛后,也将注入回购池中。
这意味着 JST 的销毁机制并非一次性刺激,而是一个 由利润驱动的通缩周期——每个季度的生态收入都会转化为实质性的销毁行为,从而形成长期、可持续的正反馈结构。
二、TRON 的“金融引擎”:让 DeFi 回到现金流逻辑
过去的 DeFi 世界里,“增长”往往意味着“通胀”——发

- 赞赏
- 点赞
- 评论
- 转发
- 分享
对于特朗普的再增加 100% 的关税的动作,不知道中国会不会对等反制。
如果对等反制,没准市场还会再跌一波……。就看周一了~~
如果对等反制,没准市场还会再跌一波……。就看周一了~~
- 赞赏
- 点赞
- 评论
- 转发
- 分享
只要一跌,唱空的一窝蜂跳出来,预言满天飞,末日感拉满。
翻翻这些人几天前的发言,一个个还在激情看多,现在全成“暴跌先知”,精神状态属实割裂。
都混这个圈子多少年了?这点波动就破防,配做 Crypto 的老鸟?
翻翻这些人几天前的发言,一个个还在激情看多,现在全成“暴跌先知”,精神状态属实割裂。
都混这个圈子多少年了?这点波动就破防,配做 Crypto 的老鸟?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
我的人生没有失败,因为我要么成功,要么成长;
我的人生没有敌人,全是老师,所以我不是得到,就是学到;
我的人生没有白走的路,对了就庆祝,错了就记住,我就是不会被任何人任何事打倒;
我允许一切发生,一切发生也终将有利于我。
~~~
今天刚听到这段话,挺喜欢……
这算鸡汤吗?
我的人生没有敌人,全是老师,所以我不是得到,就是学到;
我的人生没有白走的路,对了就庆祝,错了就记住,我就是不会被任何人任何事打倒;
我允许一切发生,一切发生也终将有利于我。
~~~
今天刚听到这段话,挺喜欢……
这算鸡汤吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
【SunPerp 与 DEX 2.0:从“低成本”到“生态闭环”的迭代革命】
在过去两年里,去中心化永续合约赛道的竞争已经初步定型:dYdX 代表“专业交易体验”,GMX/Hyperliquid 代表“社区与流动性驱动”。然而,这些头部 DEX 仍然存在三个痛点:
1. Gas 成本居高不下 —— 每次开仓平仓都要计算链上 Gas,用户难以高频交易;
2. 流动性分散 —— 每个平台都要自己解决深度,资金池割裂;
3. 生态闭环不足 —— 很多 DEX 只解决交易问题,却缺乏与借贷、稳定币、跨链的整合。
而 SunPerp 的出现,正是踩中了“DEX 2.0”时代的三大关键词:
1. 低成本:零 Gas + 行业最低费率
SunPerp 采用链下撮合 + 链上结算的混合架构,结合 TRON 最近 60% 的网络费率下调,让用户真正体验到“零 Gas 交易”。
再加上协议费率低至 0.05% 以下,高频交易者和量化资金有了天然的洼地。
2. 高效率:USDT 结算 + 天然流动性
不同于其他 DEX 要先解决“从哪找流动性”的冷启动问题,SunPerp 直接站在了 TRON 的稳定币霸权之上:
(1)827 亿 USDT 流通规模(全球 60% 在 TRON 上)
(2)单日 300 亿美元稳定币交易量
这意味着 SunPerp 一上线,就能获得天然的深度与支付结算优势。
3. 生态
在过去两年里,去中心化永续合约赛道的竞争已经初步定型:dYdX 代表“专业交易体验”,GMX/Hyperliquid 代表“社区与流动性驱动”。然而,这些头部 DEX 仍然存在三个痛点:
1. Gas 成本居高不下 —— 每次开仓平仓都要计算链上 Gas,用户难以高频交易;
2. 流动性分散 —— 每个平台都要自己解决深度,资金池割裂;
3. 生态闭环不足 —— 很多 DEX 只解决交易问题,却缺乏与借贷、稳定币、跨链的整合。
而 SunPerp 的出现,正是踩中了“DEX 2.0”时代的三大关键词:
1. 低成本:零 Gas + 行业最低费率
SunPerp 采用链下撮合 + 链上结算的混合架构,结合 TRON 最近 60% 的网络费率下调,让用户真正体验到“零 Gas 交易”。
再加上协议费率低至 0.05% 以下,高频交易者和量化资金有了天然的洼地。
2. 高效率:USDT 结算 + 天然流动性
不同于其他 DEX 要先解决“从哪找流动性”的冷启动问题,SunPerp 直接站在了 TRON 的稳定币霸权之上:
(1)827 亿 USDT 流通规模(全球 60% 在 TRON 上)
(2)单日 300 亿美元稳定币交易量
这意味着 SunPerp 一上线,就能获得天然的深度与支付结算优势。
3. 生态
- 赞赏
- 点赞
- 评论
- 转发
- 分享
姻缘呢,上天安排的最大嘛?
那就立刻开始这段感情吧。
那就立刻开始这段感情吧。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
【TRON DeFi 矩阵:资金效率与价格弹性的双重催化】
一、TRON DeFi 的整体格局
(1)波场 TRON 已经从单一的稳定币结算链,成长为覆盖借贷、DEX、质押、衍生品的 一体化 DeFi 矩阵。
(2)数据背景:TVL 稳居公链前列(约 284 亿美元),其中 JustLend DAO、 Staking 长期位列前三。
(3)核心逻辑:资金在链上循环的通道越多,价格的支撑点和资金效率就越强。
二、资金效率的放大器:JustLend DAO 与 sTRX+USDD 神矿组合
(1)JustLend DAO 提供 存币生息+抵押借贷+稳定币铸造 的多元化路径。
(2)典型玩法:用户质押 TRX → 获得 sTRX → 参与借贷、DEX 做市、甚至作为抵押铸造 USDD → 构成复合收益。
(3)sTRX+USDD 组合的年化收益可超过 15%,成为 TRON DeFi 最具代表性的“资金放大器”。
(4)逻辑延展:这种循环借贷机制提升了资金利用率,也让 TRX 在 DeFi 市场中获得更高需求,进而增强价格弹性。
三、稳定币与 DEX: 的低滑点与交易闭环
(1) 集成 SunSwap、SunCurve、PSM,构建了 稳定币的全链条流动性工具。
(2)PSM 实现 USDD 与 USDT 1:1 零费用兑换,消除了稳定币的兑换摩擦,直接增强了稳定币的交易价值。
(3)稳
一、TRON DeFi 的整体格局
(1)波场 TRON 已经从单一的稳定币结算链,成长为覆盖借贷、DEX、质押、衍生品的 一体化 DeFi 矩阵。
(2)数据背景:TVL 稳居公链前列(约 284 亿美元),其中 JustLend DAO、 Staking 长期位列前三。
(3)核心逻辑:资金在链上循环的通道越多,价格的支撑点和资金效率就越强。
二、资金效率的放大器:JustLend DAO 与 sTRX+USDD 神矿组合
(1)JustLend DAO 提供 存币生息+抵押借贷+稳定币铸造 的多元化路径。
(2)典型玩法:用户质押 TRX → 获得 sTRX → 参与借贷、DEX 做市、甚至作为抵押铸造 USDD → 构成复合收益。
(3)sTRX+USDD 组合的年化收益可超过 15%,成为 TRON DeFi 最具代表性的“资金放大器”。
(4)逻辑延展:这种循环借贷机制提升了资金利用率,也让 TRX 在 DeFi 市场中获得更高需求,进而增强价格弹性。
三、稳定币与 DEX: 的低滑点与交易闭环
(1) 集成 SunSwap、SunCurve、PSM,构建了 稳定币的全链条流动性工具。
(2)PSM 实现 USDD 与 USDT 1:1 零费用兑换,消除了稳定币的兑换摩擦,直接增强了稳定币的交易价值。
(3)稳

- 赞赏
- 1
- 评论
- 转发
- 分享
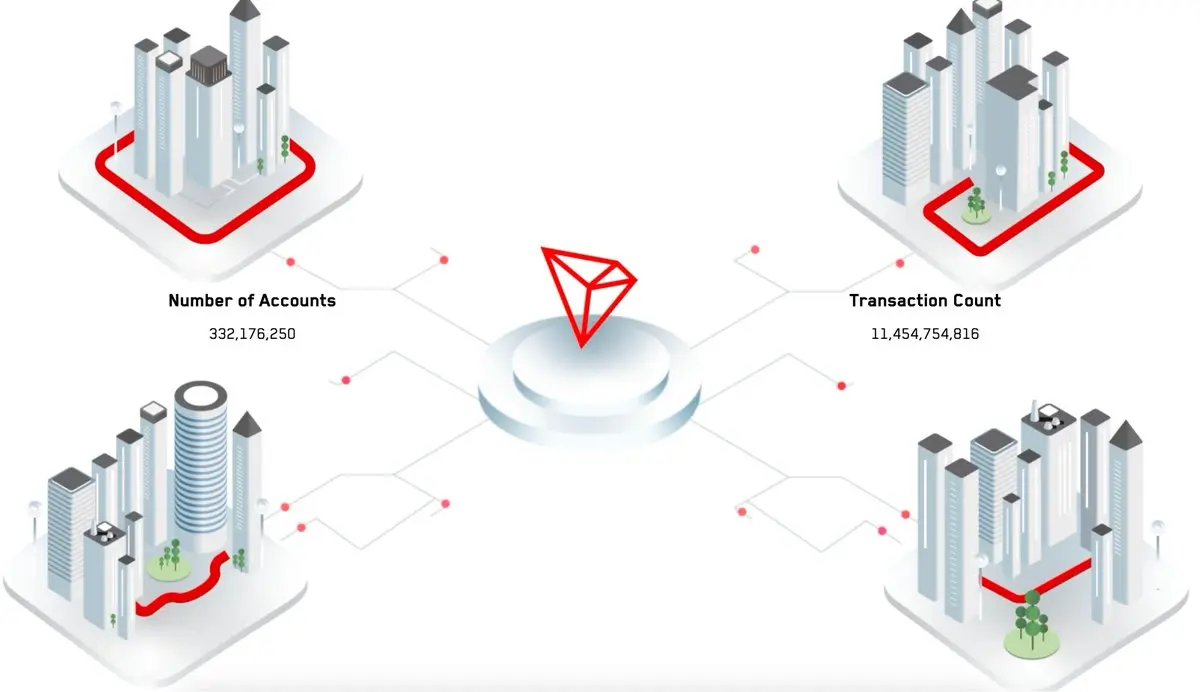
【稳定币霸主 TRON:TVL 与支付网络的双重驱动】
在加密世界,稳定币是最接近“真实货币”的存在,而 TRON(波场)正在成为这一赛道无可争议的霸主。随着稳定币立法在全球逐渐落地,以及 PayPal、RedotPay 等支付平台扩展对 TRON 的支持,TRON 不仅是链上资金流转的核心枢纽,更逐步演变为跨境支付与 DeFi 基础设施的双重引擎。
一、稳定币规模:827 亿 USDT 的“护城河”
截至 9 月中旬,TRON 网络上流通的 USDT 已突破 827 亿美元,占据全球稳定币总量的 60% 以上,稳居行业第一。
与之相伴的,是长期稳定在 300 亿美元左右的日均交易量,以及超过 3.3 亿的链上用户规模。
在这样庞大的体量下,TRON 已经成为资金的天然聚集地,为其代币 TRX 提供了坚实的底层价值支撑。
二、TVL 与 DeFi:稳定币的价值增值器
仅仅是支付转账还不够,TRON 还通过 DeFi 基础设施进一步放大了稳定币的价值。
(1)JustLend DAO:作为生态核心借贷协议,锁仓资产(TVL)位居前三,支持 USDT、USDD、USD1 等稳定币存借,形成资金循环。
(2)stUSDT / RWA:稳定币持有者可将资产转化为链上债券收益工具,当前年化收益率超过 5%,为稳定币引入现实世界资产的回报。
(3)sUSDD:即将上线的去中心化储蓄工具,帮助
在加密世界,稳定币是最接近“真实货币”的存在,而 TRON(波场)正在成为这一赛道无可争议的霸主。随着稳定币立法在全球逐渐落地,以及 PayPal、RedotPay 等支付平台扩展对 TRON 的支持,TRON 不仅是链上资金流转的核心枢纽,更逐步演变为跨境支付与 DeFi 基础设施的双重引擎。
一、稳定币规模:827 亿 USDT 的“护城河”
截至 9 月中旬,TRON 网络上流通的 USDT 已突破 827 亿美元,占据全球稳定币总量的 60% 以上,稳居行业第一。
与之相伴的,是长期稳定在 300 亿美元左右的日均交易量,以及超过 3.3 亿的链上用户规模。
在这样庞大的体量下,TRON 已经成为资金的天然聚集地,为其代币 TRX 提供了坚实的底层价值支撑。
二、TVL 与 DeFi:稳定币的价值增值器
仅仅是支付转账还不够,TRON 还通过 DeFi 基础设施进一步放大了稳定币的价值。
(1)JustLend DAO:作为生态核心借贷协议,锁仓资产(TVL)位居前三,支持 USDT、USDD、USD1 等稳定币存借,形成资金循环。
(2)stUSDT / RWA:稳定币持有者可将资产转化为链上债券收益工具,当前年化收益率超过 5%,为稳定币引入现实世界资产的回报。
(3)sUSDD:即将上线的去中心化储蓄工具,帮助

- 赞赏
- 点赞
- 评论
- 转发
- 分享
【从政府背书到 DeFi 创新,TRON 生态全面加速】
进入 2025 年 9 月,#TRON (波场)再次成为加密社区的核心话题。从美国政府的正式认可,到链上费用优化、跨链扩展,再到稳定币与 DeFi 的全面爆发,TRON 的一系列动作频频登上热搜。以下内容将带你快速把握 TRON 的最新脉动。
一、历史性里程碑:美国商务部选 TRON 记录 GDP 数据
9 月初,美国商务部宣布,将 GDP 数据正式发布到区块链网络,并选定 TRON 为其中之一。Q2 GDP 增长 3.3% 的官方数据,已通过 TRON 区块链哈希加密存证。这是区块链首次参与美国宏观经济数据的透明化进程。
这一举措不仅是象征性认可,更意味着 TRON 的安全性和可扩展性获得了官方肯定。对开发者而言,真实世界经济数据上链,也为 DeFi 预测市场和 RWA 资产创新提供了全新机会。
二、基础设施升级:费用下降与跨链互联
8 月底到 9 月初,TRON 社区全票通过提案,将网络能量费率下调约 60%,并引入季度动态调整机制。这使得开发者和用户的交互成本显着下降,进一步提升了 TRON 在高频支付和 DeFi 场景中的吸引力。
与此同时,TRON 与 deBridge 集成,实现了与 25+ 公链的互操作,包括 Solana,稳定币的跨链流动更加高效。BTTC 推出验证者合作伙伴机制,WINkLink 预言机完成
查看原文进入 2025 年 9 月,#TRON (波场)再次成为加密社区的核心话题。从美国政府的正式认可,到链上费用优化、跨链扩展,再到稳定币与 DeFi 的全面爆发,TRON 的一系列动作频频登上热搜。以下内容将带你快速把握 TRON 的最新脉动。
一、历史性里程碑:美国商务部选 TRON 记录 GDP 数据
9 月初,美国商务部宣布,将 GDP 数据正式发布到区块链网络,并选定 TRON 为其中之一。Q2 GDP 增长 3.3% 的官方数据,已通过 TRON 区块链哈希加密存证。这是区块链首次参与美国宏观经济数据的透明化进程。
这一举措不仅是象征性认可,更意味着 TRON 的安全性和可扩展性获得了官方肯定。对开发者而言,真实世界经济数据上链,也为 DeFi 预测市场和 RWA 资产创新提供了全新机会。
二、基础设施升级:费用下降与跨链互联
8 月底到 9 月初,TRON 社区全票通过提案,将网络能量费率下调约 60%,并引入季度动态调整机制。这使得开发者和用户的交互成本显着下降,进一步提升了 TRON 在高频支付和 DeFi 场景中的吸引力。
与此同时,TRON 与 deBridge 集成,实现了与 25+ 公链的互操作,包括 Solana,稳定币的跨链流动更加高效。BTTC 推出验证者合作伙伴机制,WINkLink 预言机完成
- 赞赏
- 点赞
- 评论
- 转发
- 分享
热门话题
查看更多984.64万 热度
35.39万 热度
15.75万 热度
18.91万 热度
157.93万 热度
热门 Gate Fun
查看更多- 市值:$2455.21持有人数:20.00%
- 市值:$2451.72持有人数:10.00%
- 市值:$0.1持有人数:10.00%
- 市值:$0.1持有人数:10.00%
- 市值:$2522.17持有人数:20.13%
置顶
Gate 广场|3/5 今日话题: #比特币创下近一月新高
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
随着白宫表示已向参议院提交凯文·沃什担任美联储主席的提名,美国参议院未通过叫停特朗普打击伊朗的投票,比特币于今日凌晨创下 2 月 5 日以来新高,最高触及 74,050 美元,加密货币总市值回升突破 2.538 万亿美元。
💬 本期热议:
1️⃣ 凯文·沃什的提名是否意味着降息预期升温?
2️⃣ 当前关口,你是持币待涨、顺势追多,还是反手布局回调?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/6 15:00 - 3/8 12:00 (UTC+8)Gate 广场内容挖矿奖励继续升级!无论您是创作者还是用户,挖矿新人还是头部作者都能赢取好礼获得大奖。现在就进入广场探索吧!
创作者享受最高60%创作返佣
创作者奖励加码1500USDT:更多新人作者能瓜分奖池!
观众点击交易组件交易赢大礼!最高50GT等新春壕礼等你拿!
详情:https://www.gate.com/announcements/article/49802Gate 广场|3/4 今日话题: #美伊局势影响
🎁 化身广场“战地观察员”,抽 5 位锦鲤送出 $2,500 仓位体验券!
美伊冲突持续升级,霍尔木兹海峡陷入事实性封锁,伊拉克部分原油生产受影响。能源供应再度紧张,通胀预期抬头,股市与大宗商品市场波动加剧。
💬 本期热议:
1️⃣ 你关注到了哪些足以撼动市场的战争新进展?
2️⃣ 能源、航运、国防补给、避险资产(黄金/BTC)都受到了哪些影响?
3️⃣ 当前有哪些值得关注的多空机会?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
布局 Gate TradFi 👉️ https://www.gate.com/tradfi
📅 3/4 15:00 - 3/6 12:00 (UTC+8)🚨 Gate 广场|紧急行情通报 #加密市场上涨
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
行情拉升!比特币涨至71113.6美元,过去24小时内涨6.0%;以太坊涨至2070.22美元,过去24小时内涨5.32%。山寨币集体回暖,市场情绪明显回升。
💬 本期热议:
1️⃣ 这波反弹是否正式开启行情?今晚如何布局?
2️⃣ 明日走势怎么看?结合消息面给出你的策略判断。
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/5 18:00 - 3/6 18:00 (UTC+8)🧧 Gate 广场 $50,000 红包雨狂撒,发帖 100% 中奖!
活动全面加码,奖励上不封顶!
🚀 人人有份: 新老用户发帖即领,单帖最高可得 28U!
📈 多发多得: 参与次数不设限,发帖越多,红包拿得越手软!
立即参与:
1️⃣ 更新 App: 升级至 v8.8.0 版本。
2️⃣ 开启红包: 点击发帖,奖励自动入账!
马上发帖领红包 👉 https://www.gate.com/post
详情: https://www.gate.com/announcements/article/49773