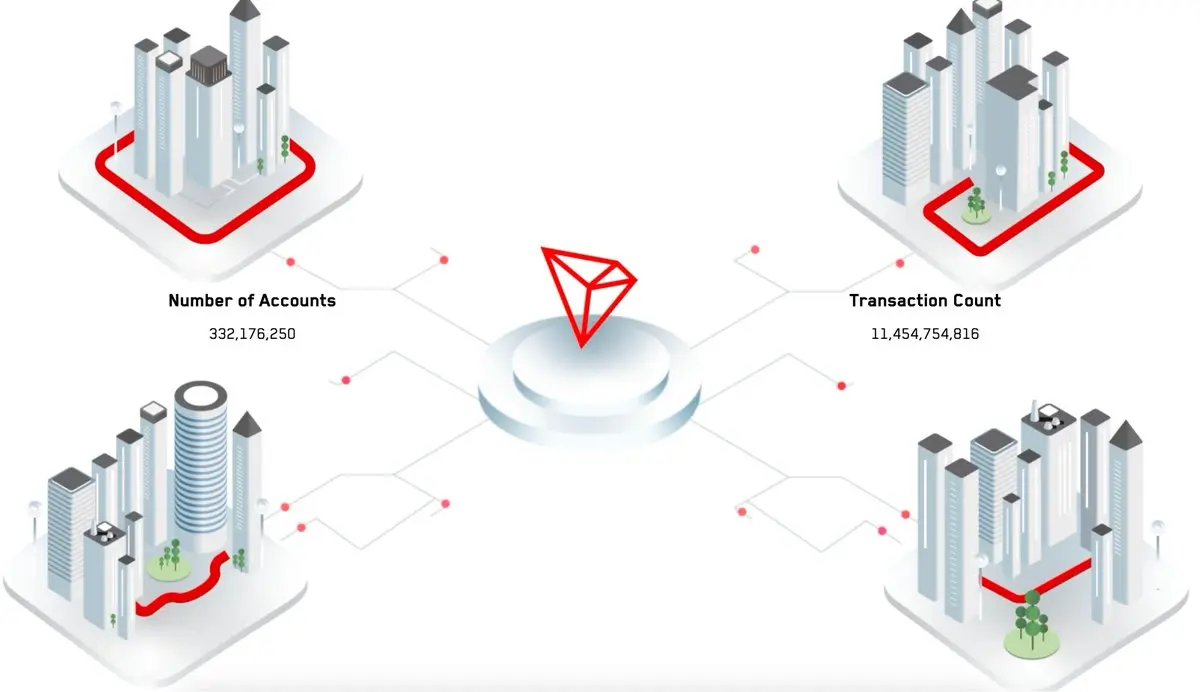
Ультимативное руководство по экономии Gas в TRON:
Используйте «аренду энергии + GasFree», чтобы снизить комиссию до минимума.
Если вы часто переводите $USDT на
#TRON , добываете
#DeFi или чеканите
#NFT , вы, несомненно, заметили: в конце августа цена на энергию (Energy) снизилась с 0.00021 TRX до 0.0001 TRX, что является самым значительным снижением с момента запуска основной сети, и введена квартальная динамическая цена — в зависимости от цены TRX и активности в сети, чтобы гарантировать долгосрочную "удобность и доступность".
Более важно то, что JustLend DAO сделал снижение сборов двухкомпо