0x99DaDa
用戶暫無簡介
0x99DaDa
老美真的要开始回歸門羅主義嗎?
為什麼對委內瑞拉這麼上心?
查看原文為什麼對委內瑞拉這麼上心?
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
憋了這麼久,感覺春節期間應該有一波小行情。
查看原文- 讚賞
- 按讚
- 留言
- 轉發
- 分享
2026年,我的杞人忧天
2026 年將近,我越來越頻繁地冒出一些可能並不成熟、甚至有點多餘的想法。
它們談不上結論,也算不上判斷,更不是要去證明什麼,只是一種在這個時間點反覆出現的不安。
也許是我想多了,也許只是杞人憂天。
但既然這些念頭總是揮之不去,我還是想把它們寫下來。
有興趣的,就交流;
沒興趣的,就拉倒。
一、人之所以重要,曾經只是因為“有用”
在人類歷史的大多數階段,一個人無論多麼有錢、多麼有權,都無法脫離他人獨立存在。
財富需要人去創造,
權力需要人去執行,
社會的運轉本身,離不開大量普通而具體的人。
所以才會有那句俗話:“皇帝死了,也要人抬棺材。”
這句話說的並不是尊嚴,而是一種樸素卻堅固的現實——
人總歸是有用的。
但這種“有用”,並不是天賦的,而是結構性的。
它建立在一個前提之上:世界離不開人。
二、AI 和自動化,第一次在動搖這個前提
隨著 AI 和自動化技術的發展,我越來越強烈地感受到一個變化:
不是某些崗位會被取代,
而是 “人是否仍然不可取代” 這個前提,正在被動搖。
縱觀世界,幾乎沒有哪個行業能拍著胸脯說自己一定安全。
生產、管理、分析、創作、決策……
取代的邊界在不斷外擴。
過去,人們常說人類還有“情緒價值”和“生理需求”這兩張底牌。
但如果我們暫時放下“必須是一個活生生的人”這種執念,會發現一個不太舒服的事實:
在很多場景裡,
AI 反而可能是更穩
查看原文2026 年將近,我越來越頻繁地冒出一些可能並不成熟、甚至有點多餘的想法。
它們談不上結論,也算不上判斷,更不是要去證明什麼,只是一種在這個時間點反覆出現的不安。
也許是我想多了,也許只是杞人憂天。
但既然這些念頭總是揮之不去,我還是想把它們寫下來。
有興趣的,就交流;
沒興趣的,就拉倒。
一、人之所以重要,曾經只是因為“有用”
在人類歷史的大多數階段,一個人無論多麼有錢、多麼有權,都無法脫離他人獨立存在。
財富需要人去創造,
權力需要人去執行,
社會的運轉本身,離不開大量普通而具體的人。
所以才會有那句俗話:“皇帝死了,也要人抬棺材。”
這句話說的並不是尊嚴,而是一種樸素卻堅固的現實——
人總歸是有用的。
但這種“有用”,並不是天賦的,而是結構性的。
它建立在一個前提之上:世界離不開人。
二、AI 和自動化,第一次在動搖這個前提
隨著 AI 和自動化技術的發展,我越來越強烈地感受到一個變化:
不是某些崗位會被取代,
而是 “人是否仍然不可取代” 這個前提,正在被動搖。
縱觀世界,幾乎沒有哪個行業能拍著胸脯說自己一定安全。
生產、管理、分析、創作、決策……
取代的邊界在不斷外擴。
過去,人們常說人類還有“情緒價值”和“生理需求”這兩張底牌。
但如果我們暫時放下“必須是一個活生生的人”這種執念,會發現一個不太舒服的事實:
在很多場景裡,
AI 反而可能是更穩

- 讚賞
- 按讚
- 留言
- 轉發
- 分享
感恩這個世界,
感恩 Web3,
感恩生命中遇到的每一個人。
偶爾回望一路走來,雖然沒有大富大貴,但大多時候也都算心想事成。那些曾經以爲跨不過去的坎,最終都在努力中找到了解法;那些放不下的心結,也慢慢學會了釋懷。
人生是一場奇妙的際遇。
不必苛求,也無需焦慮。
“一切都是最好的安排”
如果當下覺得還不夠好,那就繼續走,繼續努力,把它變成最好的樣子。
遲到的感恩節,也依然值得感恩。
願我們都能帶着力量和溫柔,繼續向前。
查看原文感恩 Web3,
感恩生命中遇到的每一個人。
偶爾回望一路走來,雖然沒有大富大貴,但大多時候也都算心想事成。那些曾經以爲跨不過去的坎,最終都在努力中找到了解法;那些放不下的心結,也慢慢學會了釋懷。
人生是一場奇妙的際遇。
不必苛求,也無需焦慮。
“一切都是最好的安排”
如果當下覺得還不夠好,那就繼續走,繼續努力,把它變成最好的樣子。
遲到的感恩節,也依然值得感恩。
願我們都能帶着力量和溫柔,繼續向前。
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
【 $JST 通縮背後的信號:#TRON# DeFi 正在完成“價值回歸” 】
在經歷數年的高速擴張之後,加密世界開始進入一次深度的“價值回歸”週期。過去那些依靠通脹激勵、空投炒作維繫熱度的 DeFi 項目正在逐漸式微,而以真實效益支撐代幣價值的“可持續模型”正在崛起。JST 的首次大規模回購與銷毀,正是這一轉變的標誌性事件——它不僅是 TRON DeFi 的一次機制革新,更是整個行業走向理性與內生增長的信號。
一、通縮不是噱頭,而是真實盈餘的證明
10 月 21 日,#JustLend DAO 正式執行 JST 回購與銷毀機制,使用 1772 萬 USDT 回購並銷毀 5.6 億枚 JST,佔總供應量的 5.6%。這不是某種“象徵性”動作,而是一場以 真實體系盈餘 為支撐的通縮行動。
JustLend DAO 的累計效益已突破 5900 萬 USDT,剩餘 70% 的存量效益(約 4140 萬 USDT)將分四個季度持續銷毀。同時,USDD 體系的多鏈效益在突破 1000 萬美元門檻後,也將注入回購池中。
這意味著 JST 的銷毀機制並非一次性刺激,而是一個 由利潤驅動的通縮週期——每個季度的體系收入都會轉化為實質性的銷毀行為,從而形成長期、可持續的正向反饋結構。
二、TRON 的“金融引擎”:讓 DeFi 回到現金流邏輯
過去的 DeFi 世界裡,“增長”往往意味著“通脹”——
在經歷數年的高速擴張之後,加密世界開始進入一次深度的“價值回歸”週期。過去那些依靠通脹激勵、空投炒作維繫熱度的 DeFi 項目正在逐漸式微,而以真實效益支撐代幣價值的“可持續模型”正在崛起。JST 的首次大規模回購與銷毀,正是這一轉變的標誌性事件——它不僅是 TRON DeFi 的一次機制革新,更是整個行業走向理性與內生增長的信號。
一、通縮不是噱頭,而是真實盈餘的證明
10 月 21 日,#JustLend DAO 正式執行 JST 回購與銷毀機制,使用 1772 萬 USDT 回購並銷毀 5.6 億枚 JST,佔總供應量的 5.6%。這不是某種“象徵性”動作,而是一場以 真實體系盈餘 為支撐的通縮行動。
JustLend DAO 的累計效益已突破 5900 萬 USDT,剩餘 70% 的存量效益(約 4140 萬 USDT)將分四個季度持續銷毀。同時,USDD 體系的多鏈效益在突破 1000 萬美元門檻後,也將注入回購池中。
這意味著 JST 的銷毀機制並非一次性刺激,而是一個 由利潤驅動的通縮週期——每個季度的體系收入都會轉化為實質性的銷毀行為,從而形成長期、可持續的正向反饋結構。
二、TRON 的“金融引擎”:讓 DeFi 回到現金流邏輯
過去的 DeFi 世界裡,“增長”往往意味著“通脹”——
TRX-1.15%

- 讚賞
- 按讚
- 留言
- 轉發
- 分享
對於川普的再增加 100% 的關稅的動作,不知道中國會不會對等反制。
如果對等反制,沒準市場還會再跌一波……。就看周一了~~
查看原文如果對等反制,沒準市場還會再跌一波……。就看周一了~~
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
只要一跌,唱空的一窩蜂跳出來,預言滿天飛,末日感拉滿。
翻翻這些人幾天前的發言,一個個還在激情看多,現在全成“暴跌先知”,精神狀態屬實割裂。
都混這個圈子多少年了?這點波動就破防,配做 Crypto 的老鳥?
查看原文翻翻這些人幾天前的發言,一個個還在激情看多,現在全成“暴跌先知”,精神狀態屬實割裂。
都混這個圈子多少年了?這點波動就破防,配做 Crypto 的老鳥?
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
我的人生沒有失敗,因爲我要麼成功,要麼成長;
我的人生沒有敵人,全是老師,所以我不是得到,就是學到;
我的人生沒有白走的路,對了就慶祝,錯了就記住,我就是不會被任何人任何事打倒;
我允許一切發生,一切發生也終將有利於我。
~~~
今天剛聽到這段話,挺喜歡……
這算雞湯嗎?
查看原文我的人生沒有敵人,全是老師,所以我不是得到,就是學到;
我的人生沒有白走的路,對了就慶祝,錯了就記住,我就是不會被任何人任何事打倒;
我允許一切發生,一切發生也終將有利於我。
~~~
今天剛聽到這段話,挺喜歡……
這算雞湯嗎?
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
【SunPerp 與 DEX 2.0:從“低成本”到“生態閉環”的迭代革命】
在過去兩年裏,去中心化永續合約賽道的競爭已經初步定型:dYdX 代表“專業交易體驗”,GMX/Hyperliquid 代表“社區與流動性驅動”。然而,這些頭部 DEX 仍然存在三個痛點:
1. Gas 成本居高不下 —— 每次開倉平倉都要計算鏈上 Gas,用戶難以高頻交易;
2. 流動性分散 —— 每個平台都要自己解決深度,資金池割裂;
3. 生態閉環不足 —— 很多 DEX 只解決交易問題,卻缺乏與借貸、穩定幣、跨鏈的整合。
而 SunPerp 的出現,正是踩中了“DEX 2.0”時代的三大關鍵詞:
1. 低成本:零 Gas + 行業最低費率
SunPerp 採用鏈下撮合 + 鏈上結算的混合架構,結合 TRON 最近 60% 的網路費率下調,讓用戶真正體驗到“零 Gas 交易”。
再加上協議費率低至 0.05% 以下,高頻交易者和量化資金有了天然的窪地。
2. 高效率:USDT 結算 + 天然流動性
不同於其他 DEX 要先解決“從哪找流動性”的冷啓動問題,SunPerp 直接站在了 TRON 的穩定幣霸權之上:
(1)827 億 USDT 流通規模(全球 60% 在 TRON 上)
(2)單日 300 億美元穩定幣交易量
這意味着 SunPerp 一上線,就能獲得天然的深度與支付結算優勢。
3. 生態
查看原文在過去兩年裏,去中心化永續合約賽道的競爭已經初步定型:dYdX 代表“專業交易體驗”,GMX/Hyperliquid 代表“社區與流動性驅動”。然而,這些頭部 DEX 仍然存在三個痛點:
1. Gas 成本居高不下 —— 每次開倉平倉都要計算鏈上 Gas,用戶難以高頻交易;
2. 流動性分散 —— 每個平台都要自己解決深度,資金池割裂;
3. 生態閉環不足 —— 很多 DEX 只解決交易問題,卻缺乏與借貸、穩定幣、跨鏈的整合。
而 SunPerp 的出現,正是踩中了“DEX 2.0”時代的三大關鍵詞:
1. 低成本:零 Gas + 行業最低費率
SunPerp 採用鏈下撮合 + 鏈上結算的混合架構,結合 TRON 最近 60% 的網路費率下調,讓用戶真正體驗到“零 Gas 交易”。
再加上協議費率低至 0.05% 以下,高頻交易者和量化資金有了天然的窪地。
2. 高效率:USDT 結算 + 天然流動性
不同於其他 DEX 要先解決“從哪找流動性”的冷啓動問題,SunPerp 直接站在了 TRON 的穩定幣霸權之上:
(1)827 億 USDT 流通規模(全球 60% 在 TRON 上)
(2)單日 300 億美元穩定幣交易量
這意味着 SunPerp 一上線,就能獲得天然的深度與支付結算優勢。
3. 生態
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
姻緣呢,上天安排的最大嘛?
那就立刻開始這段感情吧。
查看原文那就立刻開始這段感情吧。
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
【TRON DeFi 矩陣:資金效率與價格彈性的雙重催化】
一、TRON DeFi 的整體格局
(1)波場 TRON 已經從單一的穩定幣結算鏈,成長爲覆蓋借貸、DEX、質押、衍生品的 一體化 DeFi 矩陣。
(2)數據背景:TVL 穩居公鏈前列(約 284 億美元),其中 JustLend DAO、 Staking 長期位列前三。
(3)核心邏輯:資金在鏈上循環的通道越多,價格的支撐點和資金效率就越強。
二、資金效率的放大器:JustLend DAO 與 sTRX+USDD 神礦組合
(1)JustLend DAO 提供 存幣生息+抵押借貸+穩定幣鑄造 的多元化路徑。
(2)典型玩法:用戶質押 TRX → 獲得 sTRX → 參與借貸、DEX 做市、甚至作爲抵押鑄造 USDD → 構成復合收益。
(3)sTRX+USDD 組合的年化收益可超過 15%,成爲 TRON DeFi 最具代表性的“資金放大器”。
(4)邏輯延展:這種循環借貸機制提升了資金利用率,也讓 TRX 在 DeFi 市場中獲得更高需求,進而增強價格彈性。
三、穩定幣與 DEX: 的低滑點與交易閉環
(1) 集成 SunSwap、SunCurve、PSM,構建了 穩定幣的全鏈條流動性工具。
(2)PSM 實現 USDD 與 USDT 1:1 零費用兌換,消除了穩定幣的兌換摩擦,直接增強了穩定幣的交易價值。
(3)穩
一、TRON DeFi 的整體格局
(1)波場 TRON 已經從單一的穩定幣結算鏈,成長爲覆蓋借貸、DEX、質押、衍生品的 一體化 DeFi 矩陣。
(2)數據背景:TVL 穩居公鏈前列(約 284 億美元),其中 JustLend DAO、 Staking 長期位列前三。
(3)核心邏輯:資金在鏈上循環的通道越多,價格的支撐點和資金效率就越強。
二、資金效率的放大器:JustLend DAO 與 sTRX+USDD 神礦組合
(1)JustLend DAO 提供 存幣生息+抵押借貸+穩定幣鑄造 的多元化路徑。
(2)典型玩法:用戶質押 TRX → 獲得 sTRX → 參與借貸、DEX 做市、甚至作爲抵押鑄造 USDD → 構成復合收益。
(3)sTRX+USDD 組合的年化收益可超過 15%,成爲 TRON DeFi 最具代表性的“資金放大器”。
(4)邏輯延展:這種循環借貸機制提升了資金利用率,也讓 TRX 在 DeFi 市場中獲得更高需求,進而增強價格彈性。
三、穩定幣與 DEX: 的低滑點與交易閉環
(1) 集成 SunSwap、SunCurve、PSM,構建了 穩定幣的全鏈條流動性工具。
(2)PSM 實現 USDD 與 USDT 1:1 零費用兌換,消除了穩定幣的兌換摩擦,直接增強了穩定幣的交易價值。
(3)穩
TRX-1.15%

- 讚賞
- 1
- 留言
- 轉發
- 分享
【穩定幣霸主 TRON:TVL 與支付網絡的雙重驅動】
在加密世界,穩定幣是最接近“真實貨幣”的存在,而 TRON(波場)正在成爲這一賽道無可爭議的霸主。隨着穩定幣立法在全球逐漸落地,以及 PayPal、RedotPay 等支付平台擴展對 TRON 的支持,TRON 不僅是鏈上資金流轉的核心樞紐,更逐步演變爲跨境支付與 DeFi 基礎設施的雙重引擎。
一、穩定幣規模:827 億 USDT 的“護城河”
截至 9 月中旬,TRON 網路上流通的 USDT 已突破 827 億美元,佔據全球穩定幣總量的 60% 以上,穩居行業第一。
與之相伴的,是長期穩定在 300 億美元左右的日均交易量,以及超過 3.3 億的鏈上用戶規模。
在這樣龐大的體量下,TRON 已經成爲資金的天然聚集地,爲其代幣 TRX 提供了堅實的底層價值支撐。
二、TVL 與 DeFi:穩定幣的價值增值器
僅僅是支付轉帳還不夠,TRON 還通過 DeFi 基礎設施進一步放大了穩定幣的價值。
(1)JustLend DAO:作爲生態核心借貸協議,鎖倉資產(TVL)位居前三,支持 USDT、USDD、USD1 等穩定幣存借,形成資金循環。
(2)stUSDT / RWA:穩定幣持有者可將資產轉化爲鏈上債券收益工具,當前年化收益率超過 5%,爲穩定幣引入現實世界資產的回報。
(3)sUSDD:即將上線的去中心化儲蓄工具,幫助
查看原文在加密世界,穩定幣是最接近“真實貨幣”的存在,而 TRON(波場)正在成爲這一賽道無可爭議的霸主。隨着穩定幣立法在全球逐漸落地,以及 PayPal、RedotPay 等支付平台擴展對 TRON 的支持,TRON 不僅是鏈上資金流轉的核心樞紐,更逐步演變爲跨境支付與 DeFi 基礎設施的雙重引擎。
一、穩定幣規模:827 億 USDT 的“護城河”
截至 9 月中旬,TRON 網路上流通的 USDT 已突破 827 億美元,佔據全球穩定幣總量的 60% 以上,穩居行業第一。
與之相伴的,是長期穩定在 300 億美元左右的日均交易量,以及超過 3.3 億的鏈上用戶規模。
在這樣龐大的體量下,TRON 已經成爲資金的天然聚集地,爲其代幣 TRX 提供了堅實的底層價值支撐。
二、TVL 與 DeFi:穩定幣的價值增值器
僅僅是支付轉帳還不夠,TRON 還通過 DeFi 基礎設施進一步放大了穩定幣的價值。
(1)JustLend DAO:作爲生態核心借貸協議,鎖倉資產(TVL)位居前三,支持 USDT、USDD、USD1 等穩定幣存借,形成資金循環。
(2)stUSDT / RWA:穩定幣持有者可將資產轉化爲鏈上債券收益工具,當前年化收益率超過 5%,爲穩定幣引入現實世界資產的回報。
(3)sUSDD:即將上線的去中心化儲蓄工具,幫助

- 讚賞
- 按讚
- 留言
- 轉發
- 分享
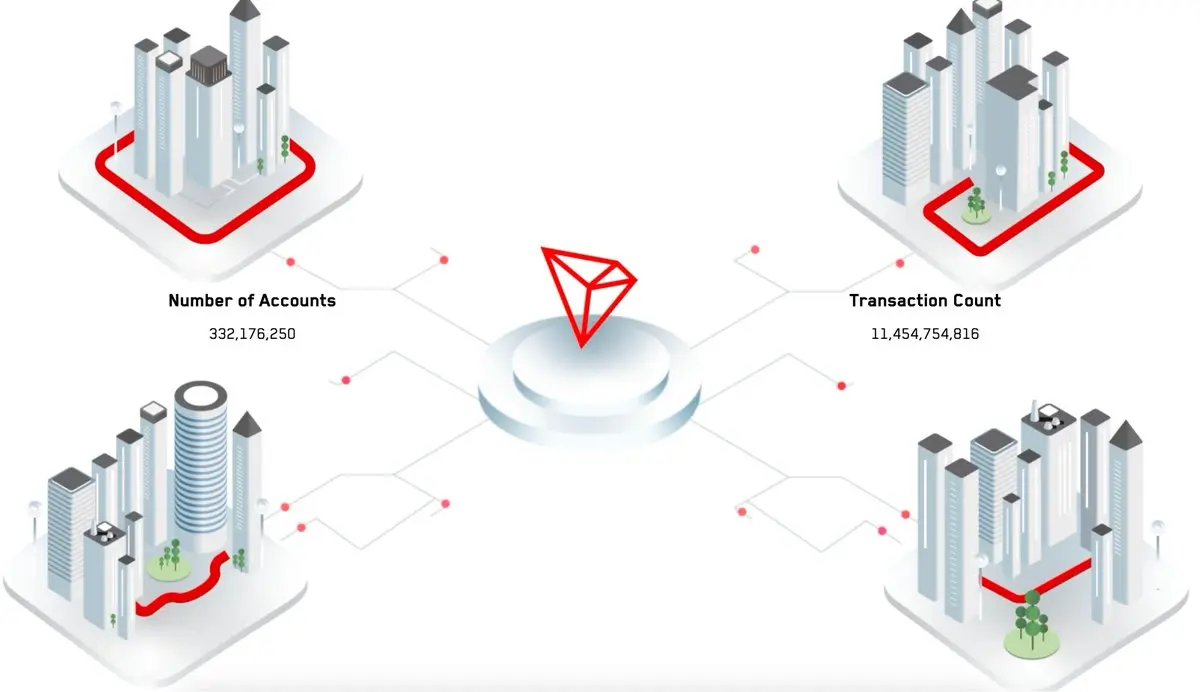
【从政府背书到 DeFi 创新,TRON 生态全面加速】
进入 2025 年 9 月,#TRON (波场)再次成为加密社区的核心话题。从美国政府的正式认可,到链上费用优化、跨链扩展,再到稳定币与 DeFi 的全面爆发,TRON 的一系列动作频频登上热搜。以下内容将带你快速把握 TRON 的最新脉动。
一、历史性里程碑:美国商务部选 TRON 记录 GDP 数据
9 月初,美国商务部宣布,将 GDP 数据正式发布到区块链网络,并选定 TRON 为其中之一。Q2 GDP 增长 3.3% 的官方数据,已通过 TRON 区块链哈希加密存证。这是区块链首次参与美国宏观经济数据的透明化进程。
这一举措不仅是象征性认可,更意味着 TRON 的安全性和可扩展性获得了官方肯定。对开发者而言,真实世界经济数据上链,也为 DeFi 预测市场和 RWA 资产创新提供了全新机会。
二、基础设施升级:费用下降与跨链互联
8 月底到 9 月初,TRON 社区全票通过提案,将网络能量费率下调约 60%,并引入季度动态调整机制。这使得开发者和用户的交互成本显著下降,进一步提升了 TRON 在高频支付和 DeFi 场景中的吸引力。
与此同时,TRON 与 deBridge 集成,实现了与 25+ 公链的互操作,包括 Solana,稳定币的跨链流动更加高效。BTTC 推出验证者合作伙伴机制,WINkLink 预言机完成
进入 2025 年 9 月,#TRON (波场)再次成为加密社区的核心话题。从美国政府的正式认可,到链上费用优化、跨链扩展,再到稳定币与 DeFi 的全面爆发,TRON 的一系列动作频频登上热搜。以下内容将带你快速把握 TRON 的最新脉动。
一、历史性里程碑:美国商务部选 TRON 记录 GDP 数据
9 月初,美国商务部宣布,将 GDP 数据正式发布到区块链网络,并选定 TRON 为其中之一。Q2 GDP 增长 3.3% 的官方数据,已通过 TRON 区块链哈希加密存证。这是区块链首次参与美国宏观经济数据的透明化进程。
这一举措不仅是象征性认可,更意味着 TRON 的安全性和可扩展性获得了官方肯定。对开发者而言,真实世界经济数据上链,也为 DeFi 预测市场和 RWA 资产创新提供了全新机会。
二、基础设施升级:费用下降与跨链互联
8 月底到 9 月初,TRON 社区全票通过提案,将网络能量费率下调约 60%,并引入季度动态调整机制。这使得开发者和用户的交互成本显著下降,进一步提升了 TRON 在高频支付和 DeFi 场景中的吸引力。
与此同时,TRON 与 deBridge 集成,实现了与 25+ 公链的互操作,包括 Solana,稳定币的跨链流动更加高效。BTTC 推出验证者合作伙伴机制,WINkLink 预言机完成
- 讚賞
- 按讚
- 留言
- 轉發
- 分享
熱門話題
查看更多984.3萬 熱度
34.16萬 熱度
11.54萬 熱度
15.71萬 熱度
157.69萬 熱度
熱門 Gate Fun
查看更多- 市值:$2516.08持有人數:20.13%
- 市值:$2472.41持有人數:10.00%
- 市值:$2458.62持有人數:10.00%
- 市值:$2500.94持有人數:20.13%
- 市值:$0.1持有人數:10.00%
置頂
Gate 廣場|3/5 今日話題: #比特币创下近一月新高
🎁 解讀行情走勢,抽 5 位錦鯉送出 $2,500 仓位體驗券!
隨著白宮表示已向參議院提交凱文·沃什擔任美聯儲主席的提名,美國參議院未通過叫停特朗普打擊伊朗的投票,比特幣於今日凌晨創下 2 月 5 日以來新高,最高觸及 74,050 美元,加密貨幣總市值回升突破 2.538 萬億美元。
💬 本期熱議:
1️⃣ 凱文·沃什的提名是否意味著降息預期升溫?
2️⃣ 當前關口,你是持幣待漲、順勢追多,還是反手布局回調?
分享觀點,瓜分好禮 👉️ https://www.gate.com/post
📅 3/6 15:00 - 3/8 12:00 (UTC+8)Gate 廣場內容挖礦獎勵繼續升級!無論您是創作者還是用戶,挖礦新人還是頭部作者都能贏取好禮獲得大獎。現在就進入廣場探索吧!
創作者享受最高60%創作返佣
創作者獎勵加碼1500USDT:更多新人作者能瓜分獎池!
觀眾點擊交易組件交易贏大禮!最高50GT等新春壕禮等你拿!
詳情:https://www.gate.com/announcements/article/49802Gate 廣場|3/4 今日話題: #美伊局势影响
🎁 化身廣場“戰地觀察員”,抽 5 位幸運兒送出 $2,500 仓位體驗券!
美伊衝突持續升級,霍爾木茲海峽陷入事實性封鎖,伊拉克部分原油生產受影響。能源供應再度緊張,通脹預期抬頭,股市與大宗商品市場波動加劇。
💬 本期熱議:
1️⃣ 你關注到了哪些足以撼動市場的戰爭新進展?
2️⃣ 能源、航運、國防補給、避險資產(黃金/BTC)都受到了哪些影響?
3️⃣ 當前有哪些值得關注的多空機會?
分享觀點,瓜分好禮 👉️ https://www.gate.com/post
布局 Gate TradFi 👉️ https://www.gate.com/tradfi
📅 3/4 15:00 - 3/6 12:00 (UTC+8)🚨 Gate 廣場|緊急行情通報 #加密市场上涨
🎁 解讀行情走勢,抽 5 位幸運兒送出 $2,500 仓位體驗券!
行情拉升!比特幣漲至71113.6美元,過去24小時內漲6.0%;以太坊漲至2070.22美元,過去24小時內漲5.32%。山寨幣集體回暖,市場情緒明顯回升。
💬 本期熱議:
1️⃣ 這波反彈是否正式開啟行情?今晚如何布局?
2️⃣ 明日走勢怎麼看?結合消息面給出你的策略判斷。
分享觀點,瓜分好禮 👉️ https://www.gate.com/post
📅 3/5 18:00 - 3/6 18:00 (UTC+8)🧧 Gate 廣場 $50,000 紅包雨狂撒,發帖 100% 中獎!
活動全面加碼,獎勵上不封頂!
🚀 人人有份: 新老用戶發帖即領,單帖最高可得 28U!
📈 多發多得: 參與次數不設限,發帖越多,紅包拿得越手軟!
立即參與:
1️⃣ 更新 App: 升級至 v8.8.0 版本。
2️⃣ 開啟紅包: 點擊發帖,獎勵自動入賬!
馬上發帖領紅包 👉 https://www.gate.com/post
詳情: https://www.gate.com/announcements/article/49773