مصدر المقال: قلب الآلة
يتفوق على النماذج الأكبر.
 * مصدر الصورة: تم إنشاؤه بواسطة الذكاء الاصطناعي غير محدود *
* مصدر الصورة: تم إنشاؤه بواسطة الذكاء الاصطناعي غير محدود *
أحد التحديات الرئيسية التي يواجهها التعلم متعدد الوسائط هو الحاجة إلى دمج الطرائق غير المتجانسة مثل النص والصوت والفيديو ، وتحتاج النماذج متعددة الوسائط إلى الجمع بين الإشارات من مصادر مختلفة. ومع ذلك ، فإن هذه الطرائق لها خصائص مختلفة يصعب دمجها مع نموذج واحد. على سبيل المثال ، الفيديو والنص لهما معدلات عينات مختلفة.
في الآونة الأخيرة ، قام فريق بحث من Google DeepMind بفصل النموذج متعدد الوسائط إلى نماذج انحدار ذاتي متعددة مستقلة ومتخصصة تعالج المدخلات بناء على خصائص كل طريقة.
على وجه التحديد ، تقترح الدراسة نموذجا متعدد الوسائط ، Mirasol3B. يتكون Mirasol3B من مكون الانحدار الذاتي لنموذج المزامنة الزمنية (الصوت والفيديو) ، ومكون الانحدار الذاتي لطريقة السياق. وهذه الطرائق ليست بالضرورة متوائمة زمنيا، ولكنها متتابعة.
 عنوان:
عنوان:
يحقق Mirasol3B مستويات SOTA في المعايير متعددة الوسائط ، متفوقا على النماذج الأكبر. من خلال تعلم تمثيلات أكثر إحكاما ، والتحكم في طول تسلسل تمثيلات ميزات الصوت والفيديو ، والنمذجة القائمة على المراسلات الزمنية ، فإن Mirasol3B قادر على تلبية المتطلبات الحسابية العالية للمدخلات متعددة الوسائط بشكل فعال.
مقدمة إرشادية
Mirasol3B هو نموذج متعدد الوسائط للصوت والفيديو والنص يتم فيه فصل النمذجة الانحدار الذاتي إلى مكونات الانحدار الذاتي لطرائق محاذاة الوقت (على سبيل المثال ، الصوت والفيديو) ومكونات الانحدار الذاتي للطرائق السياقية غير المتوافقة مع الوقت (مثل النص). يستخدم Mirasol3B أوزان الانتباه المتقاطع لتنسيق عملية التعلم لهذه المكونات. هذا الفصل يجعل توزيع المعلمات داخل النموذج أكثر منطقية ، كما يخصص سعة كافية للطرائق (الفيديو والصوت) ، ويجعل النموذج العام أكثر خفة.
كما هو موضح في الشكل 1 أدناه ، يتكون Mirasol3B بشكل أساسي من مكونين للتعلم: مكون الانحدار الذاتي ، المصمم لمعالجة المدخلات متعددة الوسائط المتزامنة (تقريبا) ، مثل الفيديو + الصوت ، والجمع بين المدخلات في الوقت المناسب.
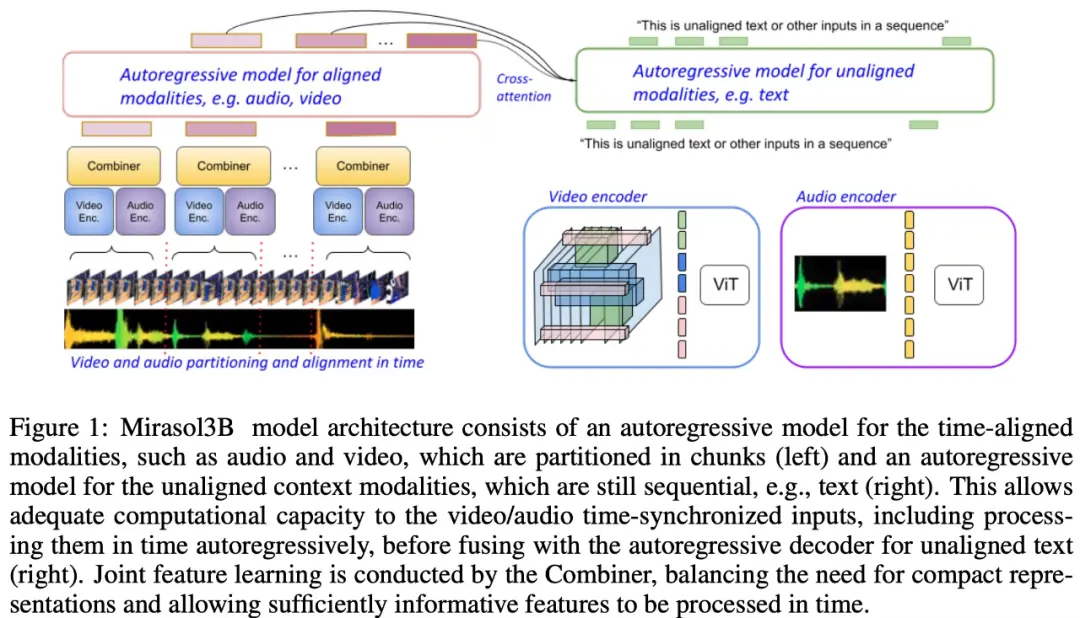
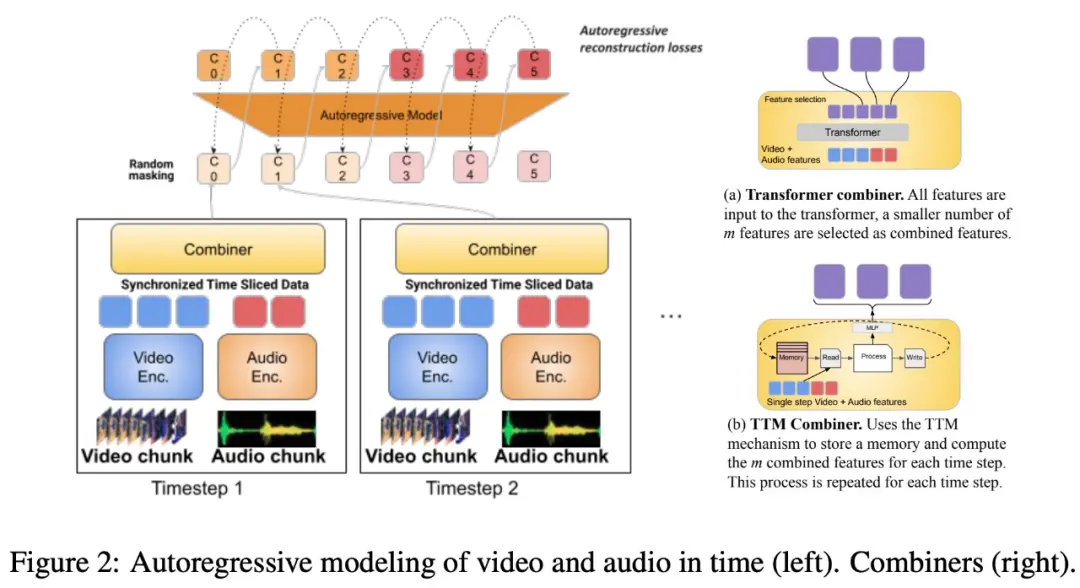 وتقترح الدراسة أيضا تقسيم طريقة المواءمة الزمنية إلى فترات زمنية، يتم فيها تعلم التمثيلات المشتركة السمعية والبصرية. على وجه التحديد ، تقترح هذه الدراسة آلية تعلم ميزة مشتركة مشروطة تسمى “Combiner”. يدمج “Combiner” الميزات المشروطة من نفس الفترة الزمنية ، مما يؤدي إلى تمثيل أكثر إحكاما.
وتقترح الدراسة أيضا تقسيم طريقة المواءمة الزمنية إلى فترات زمنية، يتم فيها تعلم التمثيلات المشتركة السمعية والبصرية. على وجه التحديد ، تقترح هذه الدراسة آلية تعلم ميزة مشتركة مشروطة تسمى “Combiner”. يدمج “Combiner” الميزات المشروطة من نفس الفترة الزمنية ، مما يؤدي إلى تمثيل أكثر إحكاما.
يستخرج “Combiner” التمثيل الزماني المكاني الأساسي من الإدخال المشروط الأصلي ، ويلتقط الخصائص الديناميكية للفيديو ، ويجمعها مع ميزات الصوت المتزامن ، بحيث يمكن للنموذج تلقي مدخلات متعددة الوسائط بمعدلات مختلفة ، ويعمل بشكل جيد عند معالجة مقاطع الفيديو الأطول.
يلبي “Combiner” بشكل فعال احتياجات التمثيل النموذجي الفعال والغني بالمعلومات. يمكن أن يغطي بشكل كامل الأحداث والأنشطة في الفيديو والطرائق الأخرى التي تحدث في نفس الوقت ، ويمكن استخدامه في نماذج الانحدار الذاتي اللاحقة لتعلم التبعيات طويلة الأجل.
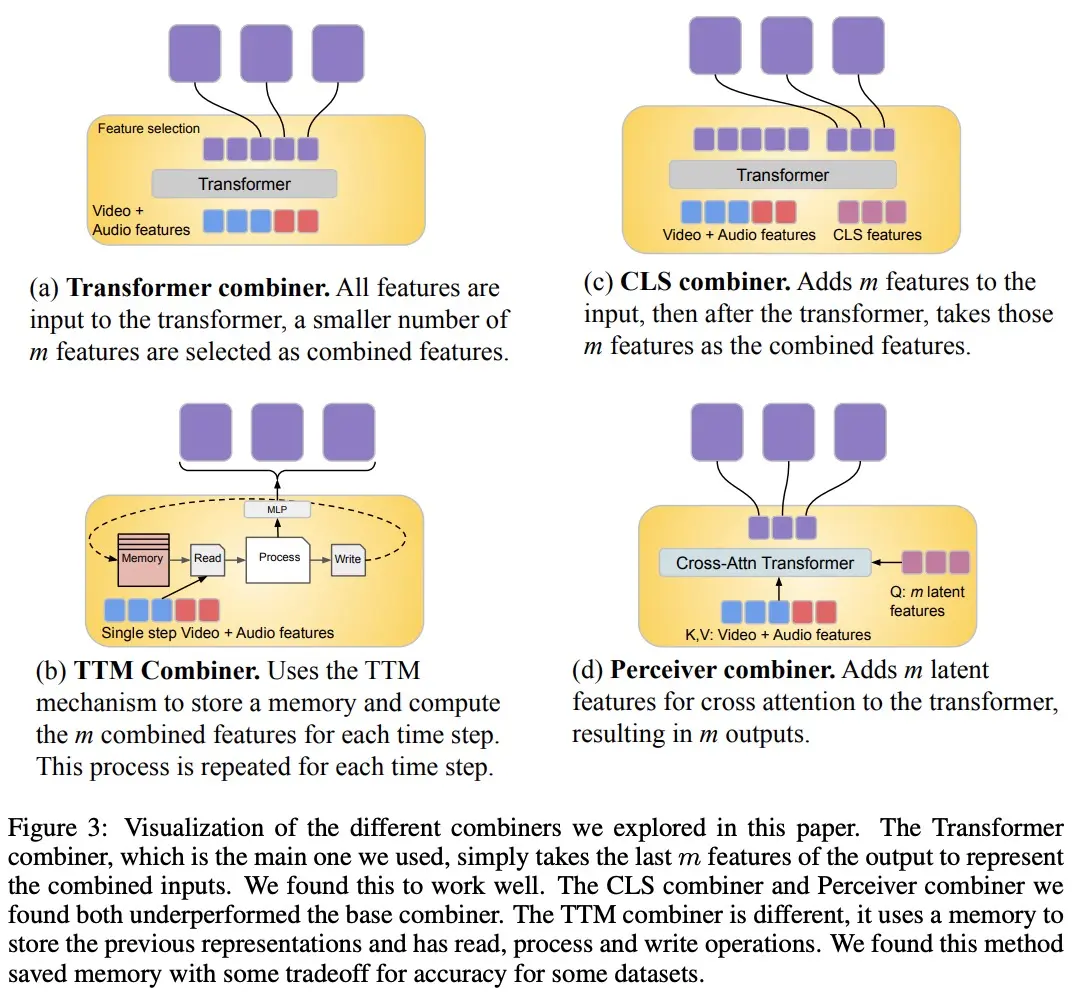 من أجل معالجة إشارات الفيديو والصوت ، واستيعاب مدخلات الفيديو / الصوت الأطول ، يتم تقسيمها إلى أجزاء (متزامنة تقريبا في الوقت المناسب) ، والتي يتم تعلمها بعد ذلك لتجميع التمثيلات السمعية البصرية من خلال “Combiner”. ويتناول المكون الثاني الإشارات السياقية أو غير المتسقة زمنيا، مثل المعلومات النصية العالمية، التي عادة ما تكون مستمرة. كما أنه متراجع ذاتي ويستخدم المساحة الكامنة المدمجة كمدخل للانتباه المتقاطع.
من أجل معالجة إشارات الفيديو والصوت ، واستيعاب مدخلات الفيديو / الصوت الأطول ، يتم تقسيمها إلى أجزاء (متزامنة تقريبا في الوقت المناسب) ، والتي يتم تعلمها بعد ذلك لتجميع التمثيلات السمعية البصرية من خلال “Combiner”. ويتناول المكون الثاني الإشارات السياقية أو غير المتسقة زمنيا، مثل المعلومات النصية العالمية، التي عادة ما تكون مستمرة. كما أنه متراجع ذاتي ويستخدم المساحة الكامنة المدمجة كمدخل للانتباه المتقاطع.
يحتوي مكون تعلم الفيديو + الصوت على معلمات 3B ، بينما المكون بدون صوت هو 2.9B. يتم استخدام معظم المعلمات شبه لنموذج الانحدار الذاتي للصوت + الفيديو. يتعامل Mirasol3B عادة مع مقاطع الفيديو بمعدل 128 إطارا ، ولكن يمكنه أيضا التعامل مع مقاطع فيديو أطول (على سبيل المثال ، 512 إطارا).
نظرا لتصميم القسم وبنية نموذج “Combiner” ، فإن إضافة المزيد من الإطارات أو زيادة حجم وعدد الكتل لن يؤدي إلا إلى زيادة المعلمات قليلا ، مما يحل مشكلة أن مقاطع الفيديو الطويلة تتطلب المزيد من المعلمات وذاكرة أكبر.
التجارب والنتائج
اختبرت الدراسة وقيمت Mirasol3B على معيار VideoQA القياسي ، ومعيار VideoQA للفيديو الطويل ، ومعيار الصوت + الفيديو.
كما هو موضح في الجدول 1 أدناه ، تظهر نتائج الاختبارات على مجموعة بيانات VideoQA MSRVTTQA أن Mirasol3B يتفوق على نموذج SOTA الحالي ، بالإضافة إلى نماذج أكبر مثل PaLI-X و Flamingo.
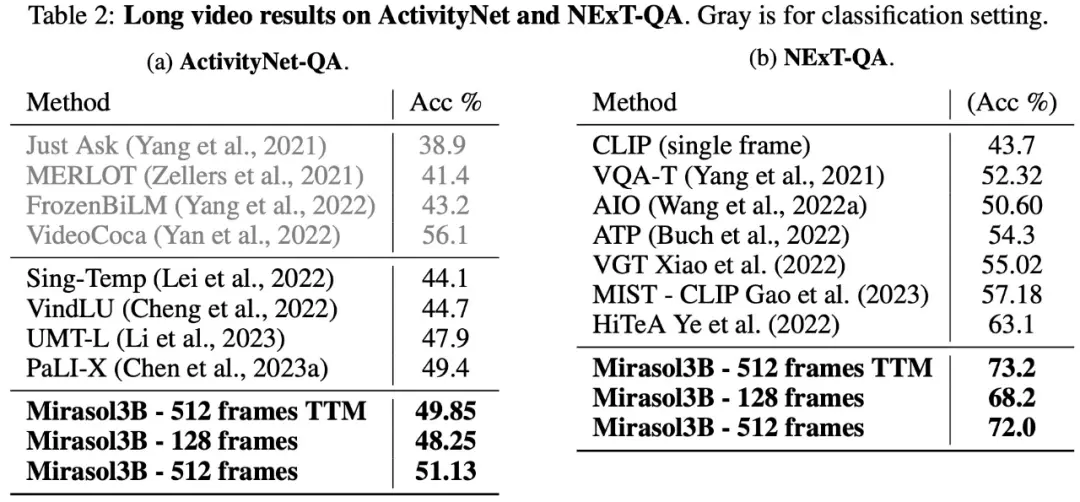
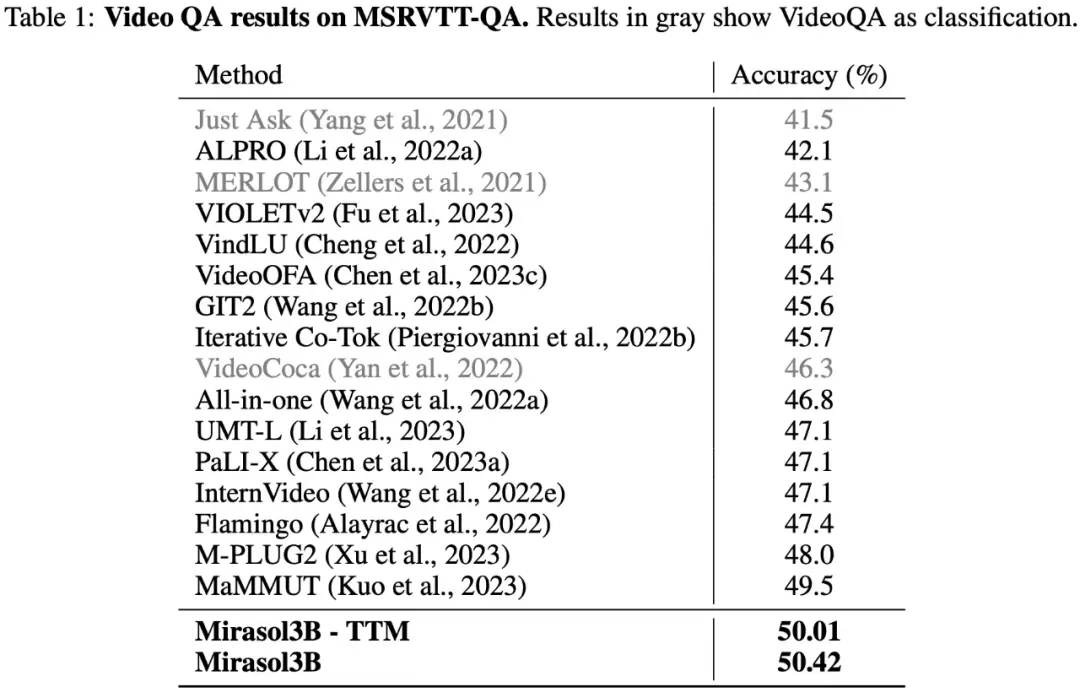 فيما يتعلق بالفيديو الطويل Q& ، تم اختبار Mirasol3B وتقييمه على مجموعات بيانات ActivityNet-QA و NExTQA ، والنتائج موضحة في الجدول 2 أدناه:
فيما يتعلق بالفيديو الطويل Q& ، تم اختبار Mirasol3B وتقييمه على مجموعات بيانات ActivityNet-QA و NExTQA ، والنتائج موضحة في الجدول 2 أدناه:
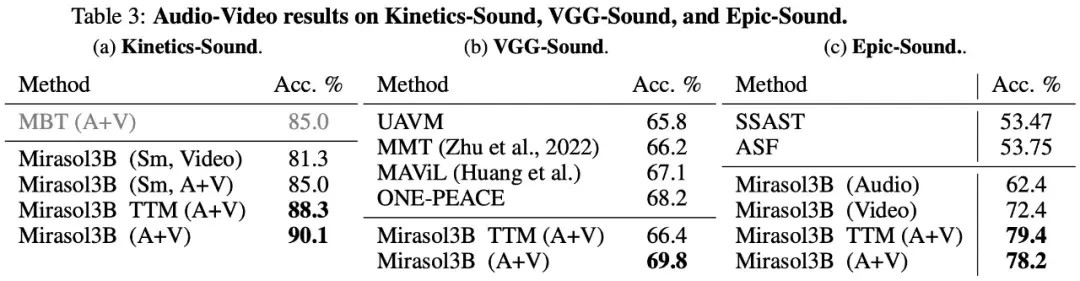
 وأخيرا، اختارت الدراسة استخدام KineticsSound وVGG-Sound وEpic-Sound لمعايير تحويل الصوت إلى فيديو مع تقييمات توليدية مفتوحة، كما هو موضح في الجدول 3 أدناه:
وأخيرا، اختارت الدراسة استخدام KineticsSound وVGG-Sound وEpic-Sound لمعايير تحويل الصوت إلى فيديو مع تقييمات توليدية مفتوحة، كما هو موضح في الجدول 3 أدناه:
 يمكن للقراء المهتمين قراءة الورقة الأصلية لمعرفة المزيد عن البحث.
يمكن للقراء المهتمين قراءة الورقة الأصلية لمعرفة المزيد عن البحث.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
