🔥 WCTC S8 全球交易赛正式开赛!
8,000,000 USDT 超级奖池解锁开启
🏆 团队赛:上半场正式开启,预报名阶段 5,500+ 战队现已集结
交易量收益额双重比拼,解锁上半场 1,800,000 USDT 奖池
🏆 个人赛:现货、合约、TradFi、ETF、闪兑、跟单齐上阵
全场交易量比拼,瓜分 2,000,000 USDT 奖池
🏆 王者 PK 赛:零门槛参与,实时匹配享受战斗快感
收益率即时 PK,瓜分 1,600,000 USDT 奖池
活动时间:2026 年 4月 23 日 16:00:00 -2026 年 5 月 20 日 15:59:59 UTC+8
⬇️ 立即参与:https://www.gate.com/competition/wctc-s8
#WCTCS8
OpenAI 发布 GPT-5.5:更快、更智能——而且更贵
简要介绍
OpenAI 于周四推出 GPT-5.5,基本将其定位为面向“智能代理式”计算的模型。它能够编写与调试代码、浏览网页、填写电子表格,并在多步骤任务中持续推进,而无需让人类一直盯着每一步。 OpenAI 表示,该更新已于今天开始向 ChatGPT 与 Codex 的 Plus、Pro、Business 和 Enterprise 订阅用户逐步推送。 OpenAI 在一则公告中表示:“我们正在发布 GPT‑5.5,这是我们迄今最聪明、也最易于使用的模型,以及迈向一种在电脑上完成工作的全新方式的下一步。”“这些提升在智能编码、计算机使用、知识工作以及早期科学研究方面尤其强——在这些领域,进展取决于跨上下文进行推理,并在一段时间内采取行动。”
OpenAI 的核心信息是:GPT-5.5 在可量化层面上比其前代产品 GPT-5.4 更聪明——而且并不更慢。在真实环境服务中实现与 GPT-5.4 相同的“每令牌延迟”,同时在基准测试中取得更高分,这类效率改进通常不会发生。更大的模型在相同硬件条件下运行时往往会更慢。 在 Terminal-Bench 2.0 上,该基准测试模型在处理需要规划与迭代式工具使用的复杂命令行工作流方面表现如何,GPT-5.5 的得分为 82.7%。Claude Opus 4.7 为 69.4%,Gemini 3.1 Pro 则为 68.5%。这不是微弱领先。 在 GDPval 上,这是一项测试知识工作能力的基准,覆盖 44 个真实职业——从金融到法律研究再到产品管理——GPT-5.5 在 84.9% 的对比中与行业专业人士持平或超过他们。
图片:OpenAI
正如预期,它也是一名相当不错的程序员。在 Expert-SWE(一个针对长周期编码任务的内部基准测试,估算的人工完成时间中位数为 20 小时)上,GPT-5.5 的表现优于 GPT-5.4。在 SWE-Bench Pro 上,该基准用于评估真实世界的 GitHub 问题修复,它达到了 58.6%。Claude Opus 4.7 的得分更高,为 64.3%,但 OpenAI 声称这可能是因为“Anthropic 在部分问题上报告过存在记忆现象”。 这次发布将进入一个因智能代理式 AI 热潮而迅速演进的市场。GPT-5.4 在 GPT-5.3 发布仅两天后就到来;而小米则从 MiMo-V2-Pro 过渡到 MiMo 2.5 Pro——并且具备完整的多模态能力——大约用了五周。GPT-5.4 到 GPT-5.5 的间隔约为七周。节奏就是这样。 但这个模型会不会对那些并不总是在编写下一个重大新东西的普通用户产生影响?如果你用的是免费层:不会。GPT-5.5 不会提供给免费用户。若你为 Plus 付费(每月 $20),今天就会推出。我们尝试在 Pro 账户下测试,但该模型并未立刻可用。
更大的看点可能是 GPT-5.5 在 Codex(OpenAI 的智能代理式编码环境)内部的能力——在那里它被证明更强。“我真的感觉我在和更高智能一起工作,甚至有一种近乎尊重的感觉,”MagicPath 的 CEO Pietro Schirano 在一段由 OpenAI 分享的引述中说道。 为更艰难、且更高精度的工作而设计的 GPT-5.5 Pro 将单独面向 Pro、Business 与 Enterprise 用户在 ChatGPT 中推出。在 BrowseComp(测试模型在全网中追踪难以找到信息的能力)上,GPT-5.5 Pro 的得分为 90.1%,领先于 Gemini 3.1 Pro 的 85.9%。 从 Artificial Analysis Index(人工分析指数)来看,该模型也是平均意义上最聪明的。GPT 5.5 报告称其令牌使用更高效、更有用,因此总体产出更好。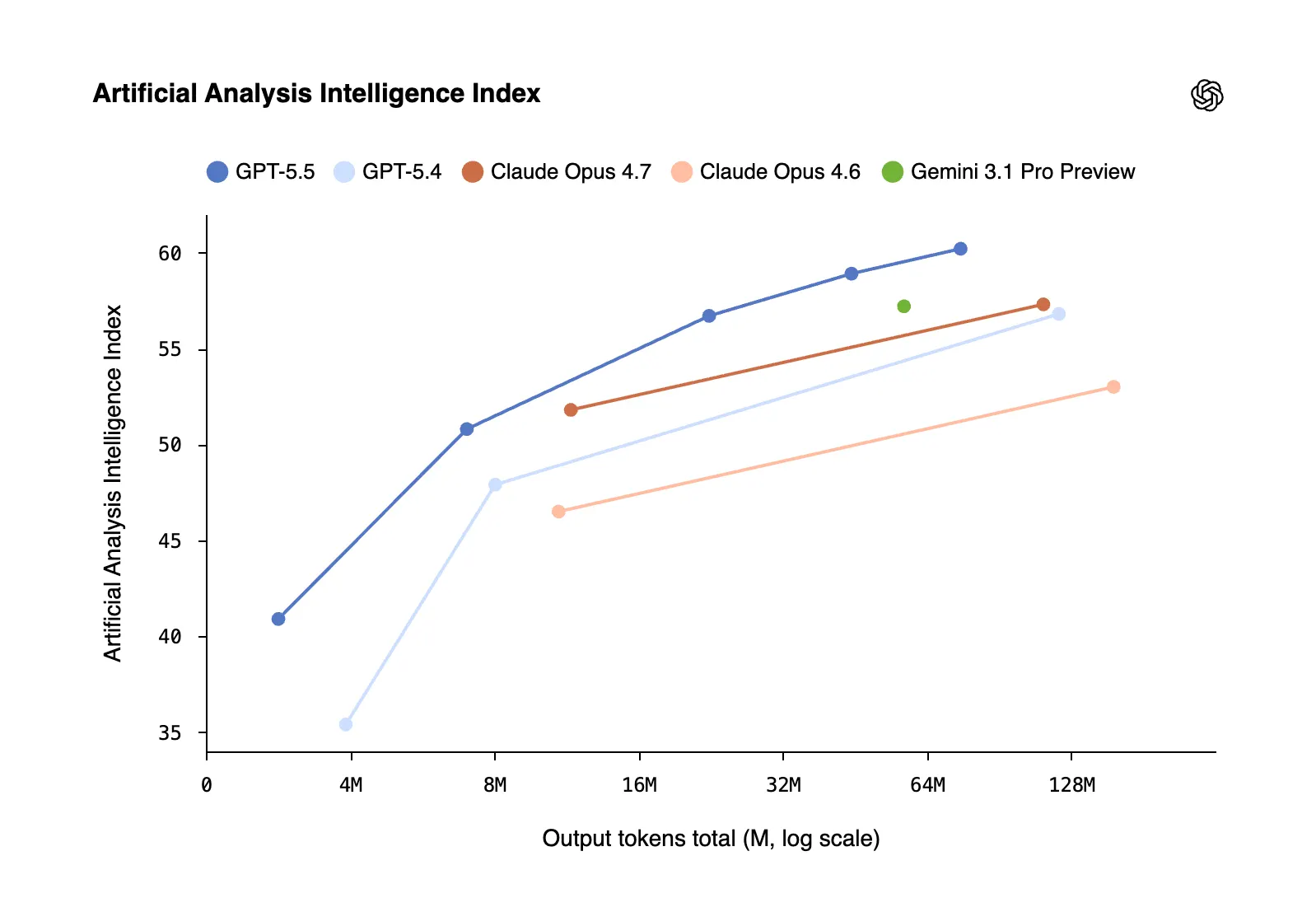
图片:OpenAI
不过,定价可能会让一些用户感到震惊。API 在推出时将对每百万输入令牌收取 $5 ,对每百万输出令牌收取 $30 ;OpenAI 表示“很快”会推出。API 中的 GPT-5.5 Pro 将对每百万输入令牌收取 $30 ,对每百万输出令牌收取 $180 。
这些费用比 GPT-5.4 更高——输入为每百万令牌 $2.50,输出为每百万令牌 $15.00——而 GPT-5.5 Pro 的定价仍与 GPT-5.4 Pro 保持一致。 不过,OpenAI 首席执行官 Sam Altman 在 X 上表示,令牌效率的提升能够抵消成本——GPT-5.5 用更少的令牌完成相同的 Codex 任务,这意味着即使每个令牌的单价更高,整体运行成本也更低。 仅作对比,小米 MiMo v2.5 Pro 对每百万令牌的输入与输出分别收取 $1 与 $3 ;Minimax M2.7 分别为 $0.30 与 $1.20;而 Kimi K2.5 需要每百万令牌分别为 $0.44 与 $2.00。