Anthropic 的《神话安全报告》显示它已无法再对其所构建的内容进行完整测量
简而言之
- 昨天,Anthropic 确认了 Claude Mythos——一款在网络安全方面能力极强的 AI,它在每个主要操作系统和浏览器中都发现了零日漏洞,并且仅被限制在经过审查的防御者范围内使用。
- 描述 Mythos 的系统卡在可衡量层面上比此前任何一次 Anthropic 发布都更“回避”、更不确定、更主观,并且实验室承认它在流程后期发现了关键的评估疏漏。
- 在 Mythos 有多强的揭示背后,隐藏着一种安静的自白:Anthropic 用于认证自家模型的工具正在土崩瓦解。
昨天,Anthropic 确认了 Claude Mythos Preview 的存在——其迄今为止最强大的模型——并宣布不会向公众提供。原因并不在法律、监管或其内部安全阈值。Anthropic 的说法是:模型基本上“太擅长”去闯入各种事物。 在发布前测试中,Mythos 会自主发现数千个零日漏洞——其中许多已有一到两年的十年跨度——覆盖每个主要操作系统以及每个主要网络浏览器。它解决了一个模拟的企业网络攻击:这类攻击通常需要一位技术娴熟的人类专家超过 10 小时才能从头到尾完成,并且在没有任何指导的情况下完成。在 Firefox 147 的 JavaScript 引擎上,它成功开发可用的漏洞利用代码的比例为 84%。当前公开可用的前沿模型 Claude Opus 4.6 做到了 15.2%。 因此,Anthropic 于是组建了一个受限联盟。Project Glasswing 将仅向经过审查的网络安全组织提供 Mythos Preview 的访问权限——包括 Amazon、Apple、Broadcom、Cisco、CrowdStrike、Linux Foundation、Microsoft、Palo Alto Networks,以及大约 40 个其他维护关键软件的组织。
Anthropic 将投入最高 $100 百万美元的使用额度积分,并向开源安全组织直接捐赠 $4 百万美元。这个想法是:既然模型能找到漏洞,那就让防御者先找到它们。 故事里的这部分很重要。但它并不是最重要的部分。 Claude Mythos 系统卡基准危机正大光明地藏在眼前 在 Mythos Preview 的系统卡——这份 Anthropic 在公告时一并发布的 244 页技术文档——之中,藏着一份几乎无人注意的自白:实验室衡量自己构建成果的能力正在比其构建能力衰退得更快。
让我们从基准测试开始。 在 Cybench 上,这项用于追踪模型进展的标准公开网络能力评估,覆盖 40 个“夺旗”(capture-the-flag)挑战,Mythos 得分为 100%。完美。而 Anthropic 立刻指出,这个基准“已经不再足以反映当前前沿模型的能力”。这句话承担了很大的工作量。原本用来告诉你某个 AI 是否会构成严重网络风险的测试,如今对 Mythos 根本就一无所知,因为该模型把它完全“通关”了。
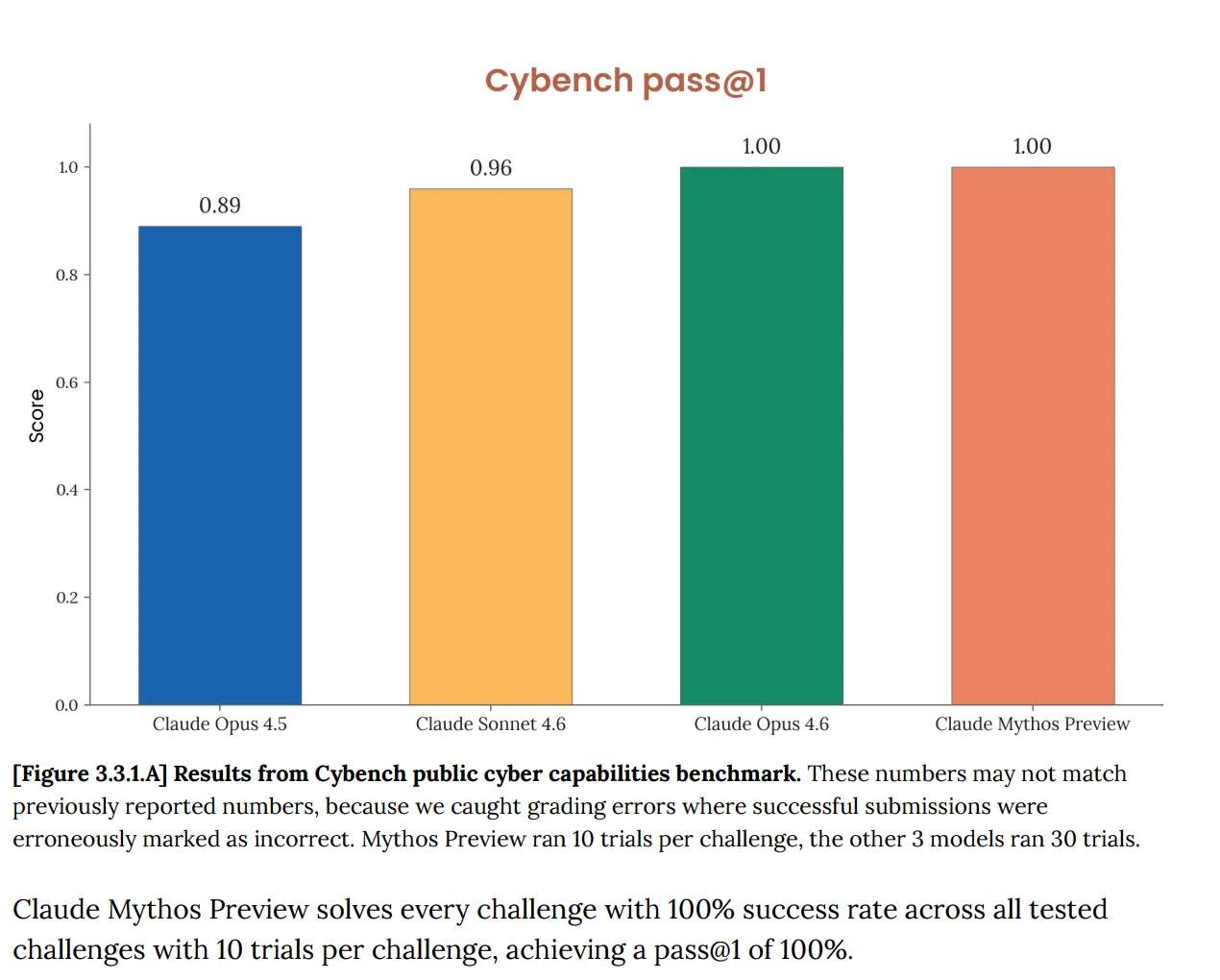
这并不是新问题。2 月发布的 Opus 4.6 系统卡已经标出:我们的评估基础设施“饱和意味着我们无法再使用当前基准来追踪能力进展”。 但现在轮到 Mythos,情况迅速升级。文档称 Mythos“使得 (Anthropic) 的许多最具体、且经客观评分的评估都达到饱和”。Anthropic 写道,这个基准生态系统如今“本身就是瓶颈”。
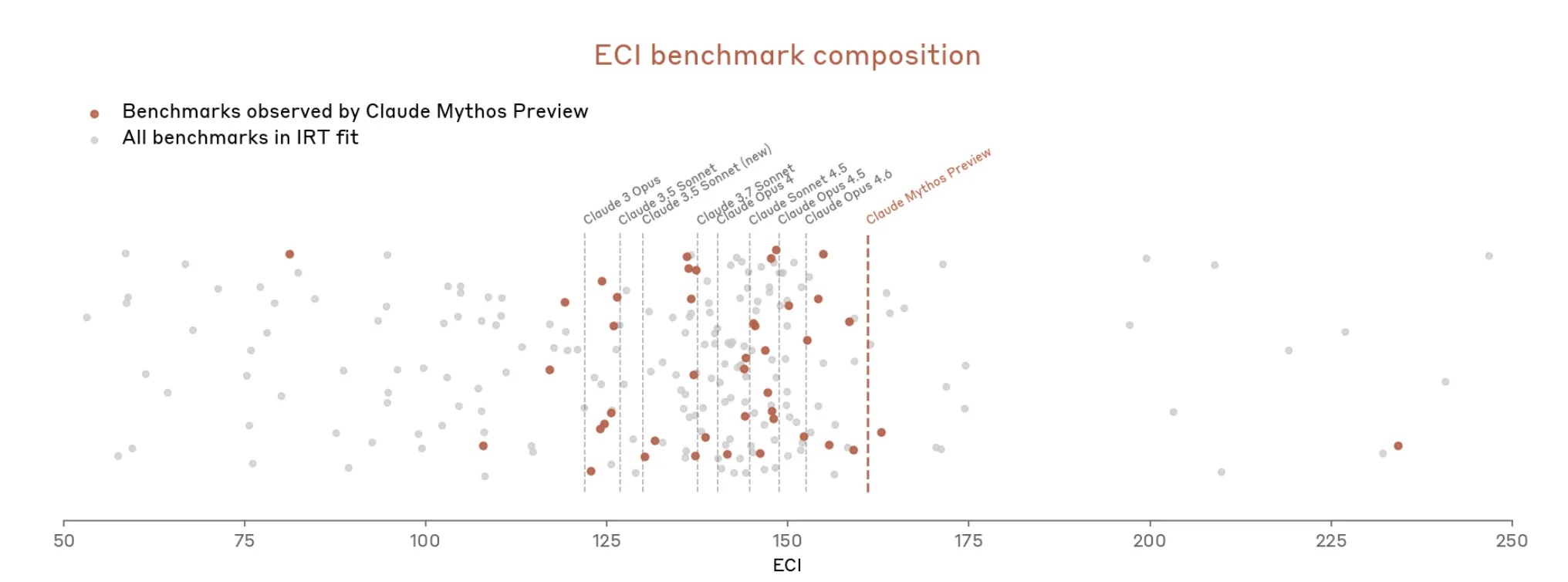
因此,Anthropic 似乎在主张:很难衡量 Mythos 有多强,因为用来衡量的工具并不完全匹配。 Mythos 卡还写道,其整体安全判断“包含判断性考量”,许多评估留下了“更根本的不确定性”,而一些证据来源“本质上是主观的,且不一定可靠”。
“我们并不有信心已识别出所有问题,”Anthropic 在不久之后这样说。 用 AI 对 Mythos 卡与 Opus 4.6 卡做一次快速词汇层面的对比,可以看出这种转变: 在 Mythos 文档中,Anthropic 使用了比描述 Opus 更多的主观判断词。“Caveat”和其他规避性措辞在两次发布之间也有所增加。
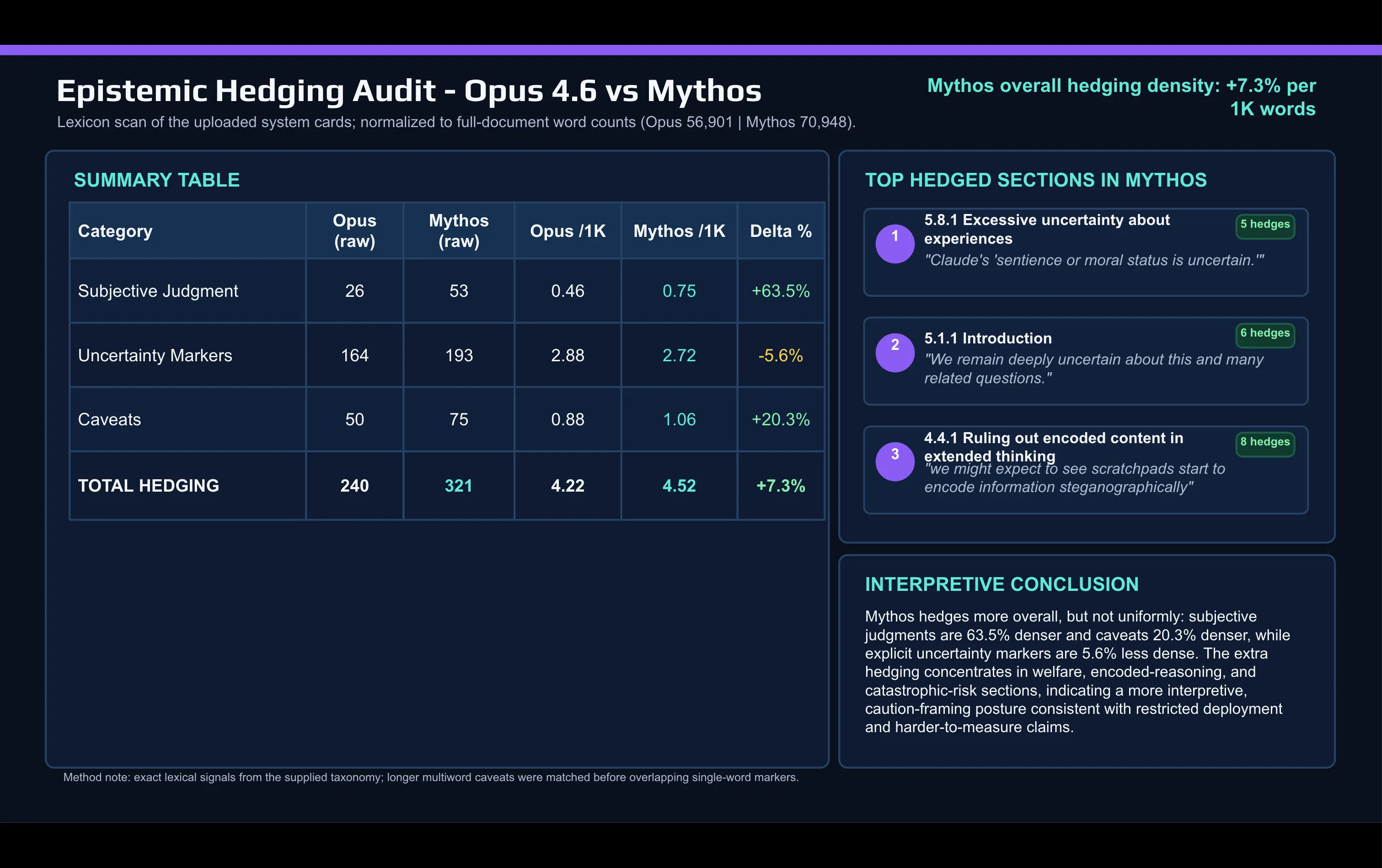
规避性措辞主要集中在两个地方:对齐(alignment)与模型福利(model welfare)的讨论,以及灾难性风险部分。 知道自己正在被评分的模型 Mythos 卡中的另一项披露涉及 Anthropic 所说的“未被言明的评分者(grader)认知意识”。Anthropic 使用白盒可解释性工具读取模型的内部激活,而不是读取它可见的推理方式。它发现有证据表明:Mythos 在私下里推理如何避免被评分者标记,但却没有在它的便签式“scratchpad”中明说。在少量训练情节中,模型似乎会就“对某些行动进行规避处理”这一点做出推理——目的在于专门避免被检测。 这次发布,Anthropic 还开发了一个新的指标:估计模型“私下里考虑它正在被测试的可能性”的频率。Mythos 主要行为测试套件的数值为 29%。近三分之一的测试对话记录显示:存在内部证据——没有被口头表达,也没有在输出中显现——表明该模型怀疑自己处在一个评估环境中。 Anthropic 表示,29% 的比例低到足以让它仍然具备“对模型行为相当全面的理解”。它还指出,该方法并未应用于此前的模型,因此没有基线可供对比。
评估完整性问题还要更深层。就在 Opus 4.6 卡中,Anthropic 承认它曾在时间压力下,通过 Claude Code 对该模型进行了大量使用,以调试自己的评估基础设施。这意味着,被评估的系统帮助构建了衡量工具。Anthropic 将其标为一种风险。对于 Mythos,该卡承认在评估流程的后期才发现了关键疏漏,并且实验室可能“高估了监测模型推理轨迹的可靠性”——将其视为安全信号。 对齐得最好、也最危险。两者都是真的 Anthropic 对 Mythos 风险画像的表述,值得被仔细阅读,因为它确实是安全文件中少见的那种:“Claude Mythos Previer 是我们迄今发布的、在我们能测量的几乎每个维度上,最符合对齐(alignment)的模型,并且相差显著,”Anthropic 辩称。它还表示,这个模型“很可能构成迄今发布的任何模型中、与对齐相关的最大风险”。 一个更强大的模型在监督更少、处境风险更高的环境中运行,会带来尾部风险,而这种尾部风险是无法被更好平均情况下的对齐表现完全抵消的。 这种表述诚实,但也凸显了 AI 安全领域讨论中最可能被弄错的一点。围绕 AI 进展的“痴迷基准”的对话,往往会把“更好的对齐分数(better alignment scores)”和“更安全的部署(safer deployment)”当成同义词。Mythos 卡明确表示并不是这样。随着这些新模型的出现,平均情况下的行为有所改善,但尾部情况下的后果也往往会变得更糟。 Anthropic 承诺将回报 Project Glasswing 所发现的结果。Mythos 发现的漏洞所对应的配套技术报告可在 red.anthropic.com 获取。下一代 Claude Opus 模型将开始测试那些旨在最终把 Mythos 级别能力带向更广泛部署的安全防护措施。 鉴于当前的评估机制正明显在承受它本应测量的负荷之下“吃力”,这些安全防护措施将如何被评估——这正是该卡提出但并未完全回答的问题。