Nguồn bài viết: Heart of the Machine
vượt trội hơn các mô hình lớn hơn.
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Một trong những thách thức chính mà học tập đa phương thức phải đối mặt là nhu cầu hợp nhất các phương thức không đồng nhất như văn bản, âm thanh và video và các mô hình đa phương thức cần kết hợp tín hiệu từ các nguồn khác nhau. Tuy nhiên, các phương thức này có những đặc điểm khác nhau khó kết hợp với một mô hình duy nhất. Ví dụ: video và văn bản có tỷ lệ mẫu khác nhau.
Gần đây, một nhóm nghiên cứu từ Google DeepMind đã tách mô hình đa phương thức thành nhiều mô hình tự hồi quy độc lập, chuyên biệt xử lý đầu vào dựa trên đặc điểm của từng phương thức.
Cụ thể, nghiên cứu đề xuất một mô hình đa phương thức, Mirasol3B. Mirasol3B bao gồm một thành phần tự hồi quy cho phương thức đồng bộ hóa tạm thời (âm thanh và video) và một thành phần tự hồi quy cho phương thức ngữ cảnh. Các phương thức này không nhất thiết phải được căn chỉnh theo thời gian, nhưng là tuần tự.
 Địa chỉ:
Địa chỉ:
Mirasol3B đạt được mức SOTA trong các tiêu chuẩn đa phương thức, vượt trội so với các mô hình lớn hơn. Bằng cách học các biểu diễn nhỏ gọn hơn, kiểm soát độ dài trình tự của các biểu diễn tính năng âm thanh-video và mô hình hóa dựa trên sự tương ứng thời gian, Mirasol3B có thể đáp ứng hiệu quả các yêu cầu tính toán cao của đầu vào đa phương thức.
Giới thiệu cách thực hiện
Mirasol3B là một mô hình đa phương thức âm thanh-video-văn bản trong đó mô hình tự hồi quy được tách ra thành các thành phần tự hồi quy cho các phương thức được căn chỉnh theo thời gian (ví dụ: âm thanh, video) và các thành phần tự hồi quy cho các phương thức ngữ cảnh không phù hợp với thời gian (ví dụ: văn bản). Mirasol3B sử dụng trọng số chú ý chéo để phối hợp quá trình học tập của các thành phần này. Việc tách rời này làm cho việc phân phối các tham số trong mô hình hợp lý hơn, cũng phân bổ đủ dung lượng cho các phương thức (video và âm thanh) và làm cho mô hình tổng thể nhẹ hơn.
Như thể hiện trong Hình 1 dưới đây, Mirasol3B bao gồm chủ yếu là hai thành phần học tập: một thành phần tự hồi quy, được thiết kế để xử lý (gần như) đầu vào đa phương thức đồng bộ, chẳng hạn như video + âm thanh và kết hợp các đầu vào một cách kịp thời.
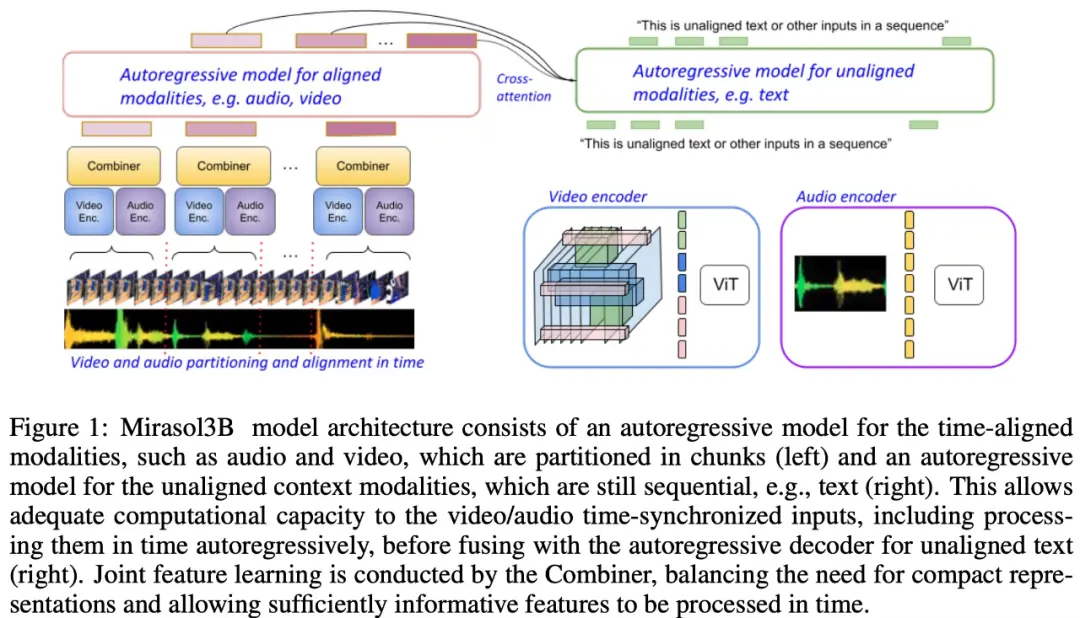
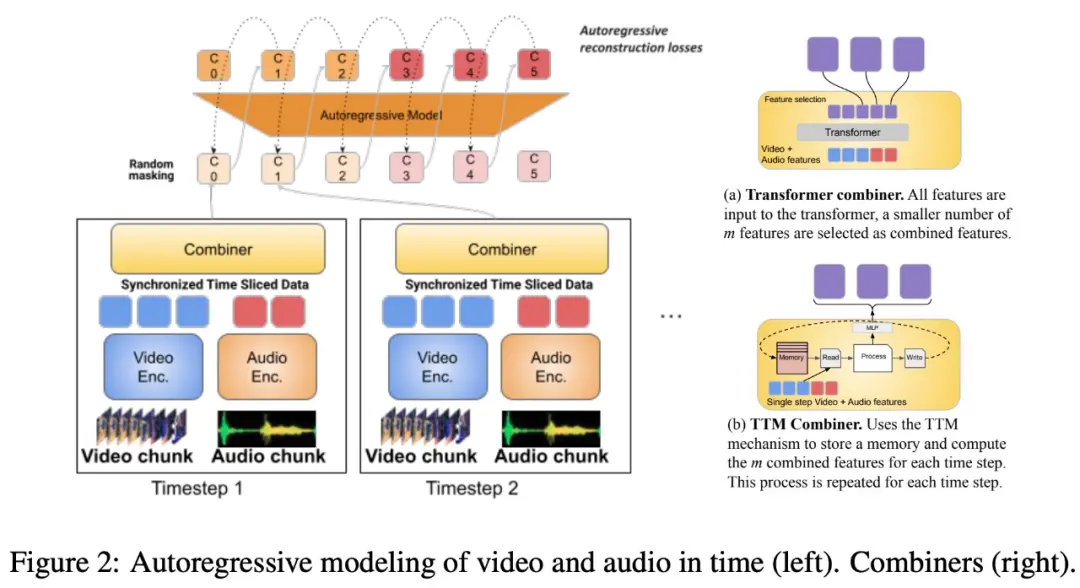 Nghiên cứu cũng đề xuất phân đoạn phương thức căn chỉnh thời gian thành các khoảng thời gian, trong đó các biểu diễn chung âm thanh-video được học. Cụ thể, nghiên cứu này đề xuất một cơ chế học tập tính năng chung phương thức được gọi là “Combiner”. “Combiner” kết hợp các tính năng phương thức từ cùng một khoảng thời gian, dẫn đến một biểu diễn nhỏ gọn hơn.
Nghiên cứu cũng đề xuất phân đoạn phương thức căn chỉnh thời gian thành các khoảng thời gian, trong đó các biểu diễn chung âm thanh-video được học. Cụ thể, nghiên cứu này đề xuất một cơ chế học tập tính năng chung phương thức được gọi là “Combiner”. “Combiner” kết hợp các tính năng phương thức từ cùng một khoảng thời gian, dẫn đến một biểu diễn nhỏ gọn hơn.
“Combiner” trích xuất biểu diễn không gian thời gian chính từ đầu vào phương thức ban đầu, nắm bắt các đặc tính động của video và kết hợp nó với các tính năng âm thanh đồng bộ, để mô hình có thể nhận đầu vào đa phương thức ở các tốc độ khác nhau và hoạt động tốt khi xử lý video dài hơn.
“Combiner” đáp ứng hiệu quả nhu cầu biểu diễn phương thức vừa hiệu quả vừa nhiều thông tin. Nó có thể bao gồm đầy đủ các sự kiện và hoạt động trong video và các phương thức khác xảy ra cùng một lúc và có thể được sử dụng trong các mô hình tự hồi quy tiếp theo để tìm hiểu các phụ thuộc dài hạn.
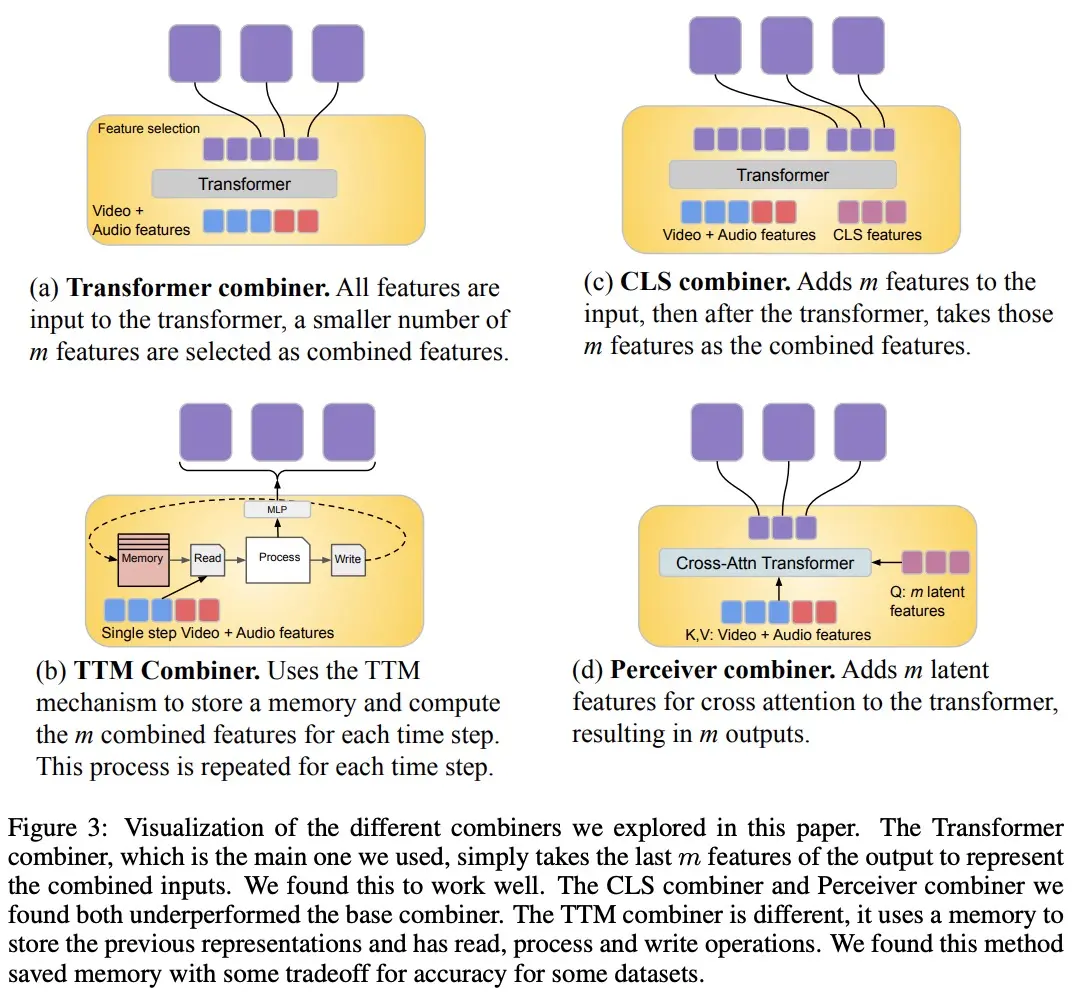 Để xử lý tín hiệu video và âm thanh, và để chứa các đầu vào video / âm thanh dài hơn, chúng được chia thành các phần (gần như đồng bộ hóa theo thời gian), sau đó được học cách tổng hợp các biểu diễn nghe nhìn thông qua “Combiner”. Thành phần thứ hai liên quan đến các tín hiệu theo ngữ cảnh hoặc sai lệch tạm thời, chẳng hạn như thông tin văn bản toàn cầu, thường vẫn liên tục. Nó cũng tự hồi quy và sử dụng không gian tiềm ẩn kết hợp làm đầu vào chú ý chéo.
Để xử lý tín hiệu video và âm thanh, và để chứa các đầu vào video / âm thanh dài hơn, chúng được chia thành các phần (gần như đồng bộ hóa theo thời gian), sau đó được học cách tổng hợp các biểu diễn nghe nhìn thông qua “Combiner”. Thành phần thứ hai liên quan đến các tín hiệu theo ngữ cảnh hoặc sai lệch tạm thời, chẳng hạn như thông tin văn bản toàn cầu, thường vẫn liên tục. Nó cũng tự hồi quy và sử dụng không gian tiềm ẩn kết hợp làm đầu vào chú ý chéo.
Thành phần học Video + Audio có thông số 3B, trong khi thành phần không có âm thanh là 2.9B. Hầu hết các bán tham số được sử dụng cho mô hình tự hồi quy âm thanh + video. Mirasol3B thường xử lý video ở 128 khung hình, nhưng nó cũng có thể xử lý video dài hơn (ví dụ: 512 khung hình).
Do thiết kế của phân vùng và kiến trúc mô hình “Combiner”, việc thêm nhiều khung hình hơn hoặc tăng kích thước và số lượng khối sẽ chỉ làm tăng các tham số một chút, điều này giải quyết được vấn đề video dài hơn đòi hỏi nhiều thông số hơn và bộ nhớ lớn hơn.
Thử nghiệm và kết quả
Nghiên cứu đã thử nghiệm và đánh giá Mirasol3B trên điểm chuẩn VideoQA tiêu chuẩn, điểm chuẩn VideoQA video dạng dài và điểm chuẩn Âm thanh + Video.
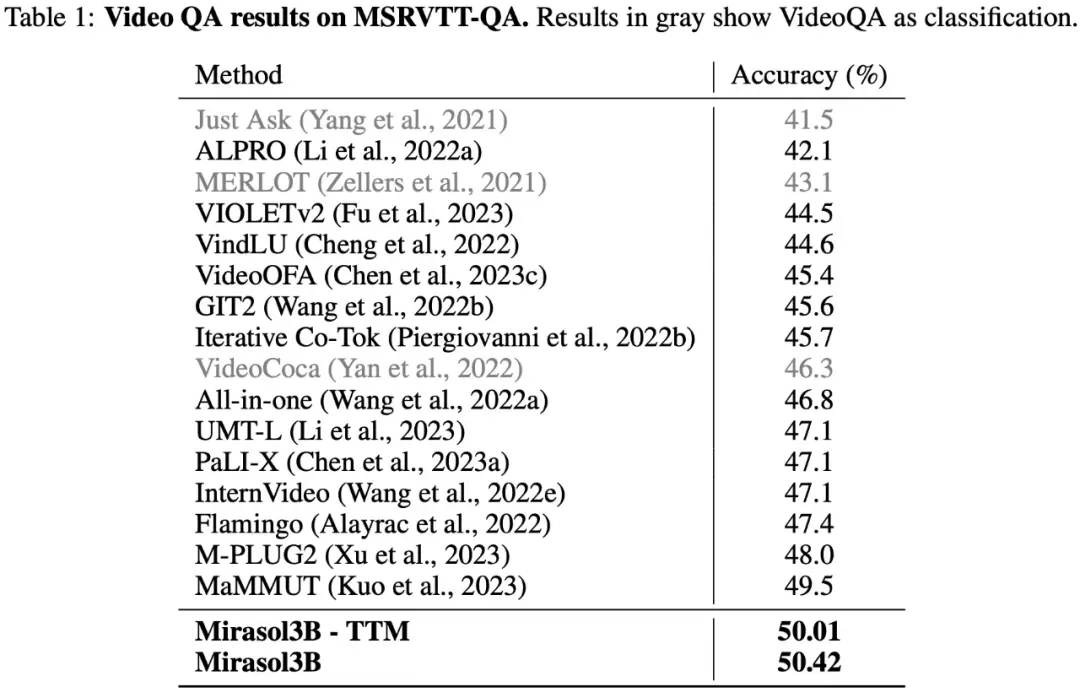
Như thể hiện trong Bảng 1 dưới đây, kết quả của các thử nghiệm trên tập dữ liệu VideoQA MSRVTTQA cho thấy Mirasol3B vượt qua mô hình SOTA hiện tại, cũng như các mô hình lớn hơn như PaLI-X và Flamingo.
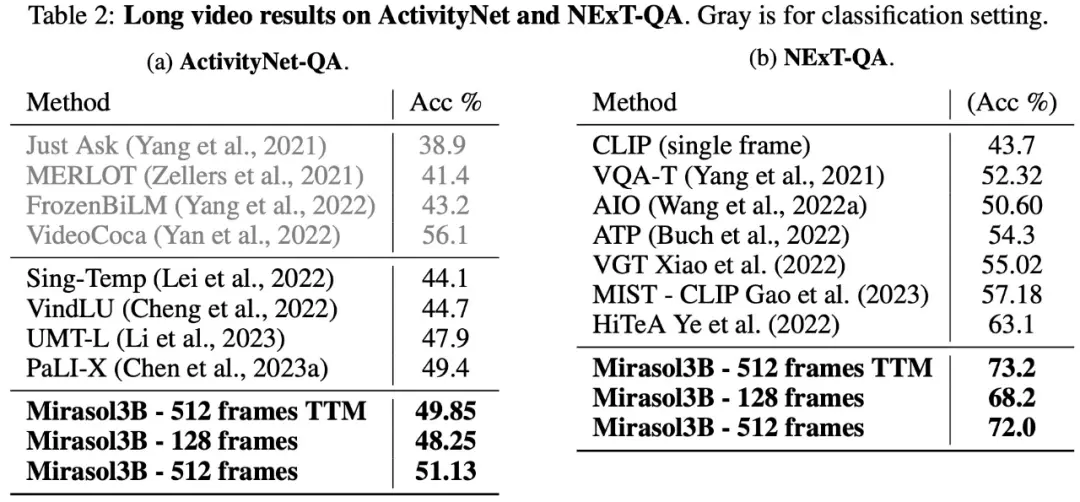
 Về mặt Hỏi && Đáp video dài, Mirasol3B đã được thử nghiệm và đánh giá trên bộ dữ liệu ActivityNet-QA, NExTQA và kết quả được hiển thị trong Bảng 2 dưới đây:
Về mặt Hỏi && Đáp video dài, Mirasol3B đã được thử nghiệm và đánh giá trên bộ dữ liệu ActivityNet-QA, NExTQA và kết quả được hiển thị trong Bảng 2 dưới đây:
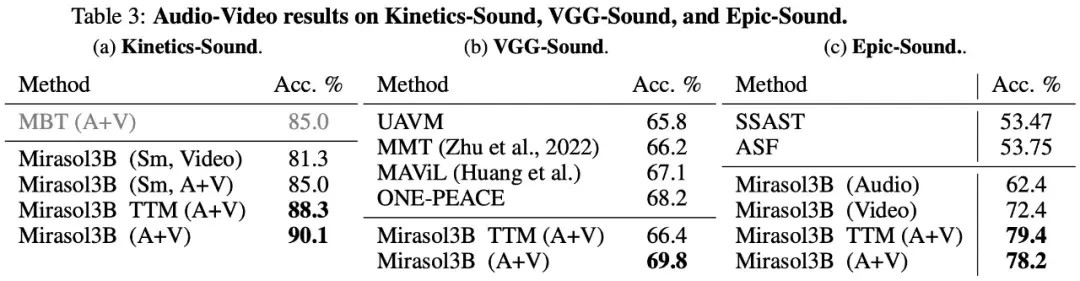
 Cuối cùng, nghiên cứu đã chọn sử dụng KineticsSound, VGG-Sound và Epic-Sound cho các điểm chuẩn âm thanh thành video với các đánh giá tổng quát mở, như thể hiện trong Bảng 3 dưới đây:
Cuối cùng, nghiên cứu đã chọn sử dụng KineticsSound, VGG-Sound và Epic-Sound cho các điểm chuẩn âm thanh thành video với các đánh giá tổng quát mở, như thể hiện trong Bảng 3 dưới đây:
 Độc giả quan tâm có thể đọc bài báo gốc để tìm hiểu thêm về nghiên cứu.
Độc giả quan tâm có thể đọc bài báo gốc để tìm hiểu thêm về nghiên cứu.
Tuyên bố miễn trừ trách nhiệm: Thông tin trên trang này có thể đến từ bên thứ ba và không đại diện cho quan điểm hoặc ý kiến của Gate. Nội dung hiển thị trên trang này chỉ mang tính chất tham khảo và không cấu thành bất kỳ lời khuyên tài chính, đầu tư hoặc pháp lý nào. Gate không đảm bảo tính chính xác hoặc đầy đủ của thông tin và sẽ không chịu trách nhiệm cho bất kỳ tổn thất nào phát sinh từ việc sử dụng thông tin này. Đầu tư vào tài sản ảo tiềm ẩn rủi ro cao và chịu biến động giá đáng kể. Bạn có thể mất toàn bộ vốn đầu tư. Vui lòng hiểu rõ các rủi ro liên quan và đưa ra quyết định thận trọng dựa trên tình hình tài chính và khả năng chấp nhận rủi ro của riêng bạn. Để biết thêm chi tiết, vui lòng tham khảo
Tuyên bố miễn trừ trách nhiệm.