Article source: Heart of the Machine
outperforms larger models.
 Image source: Generated by Unbounded AI
Image source: Generated by Unbounded AI
One of the main challenges faced by multimodal learning is the need to fuse heterogeneous modalities such as text, audio, and video, and multimodal models need to combine signals from different sources. However, these modalities have different characteristics that are difficult to combine with a single model. For example, video and text have different sample rates.
Recently, a research team from Google DeepMind decoupled the multimodal model into multiple independent, specialized autoregressive models that process inputs based on the characteristics of each modality.
Specifically, the study proposes a multimodal model, Mirasol3B. Mirasol3B consists of an autoregressive component for the temporal synchronization modal (audio and video), and an autoregressive component for the context modality. These modalities are not necessarily time-aligned, but are sequential.
 Address:
Address:
Mirasol3B achieves SOTA levels in multimodal benchmarks, outperforming larger models. By learning more compact representations, controlling the sequence length of audio-video feature representations, and modeling based on temporal correspondence, Mirasol3B is able to effectively meet the high computational requirements of multimodal inputs.
How-to Introduction
Mirasol3B is an audio-video-text multimodal model in which autoregressive modeling is decoupled into autoregressive components for time-aligned modalities (e.g., audio, video) and autoregressive components for non-time-aligned contextual modalities (e.g., text). Mirasol3B uses cross-attention weights to coordinate the learning process of these components. This decoupling makes the distribution of parameters within the model more reasonable, also allocates sufficient capacity to the modalities (video and audio), and makes the overall model more lightweight.
As shown in Figure 1 below, Mirasol3B consists primarily of two learning components: an autoregressive component, designed to process (almost) synchronous multimodal inputs, such as video + audio, and combine the inputs in a timely manner.
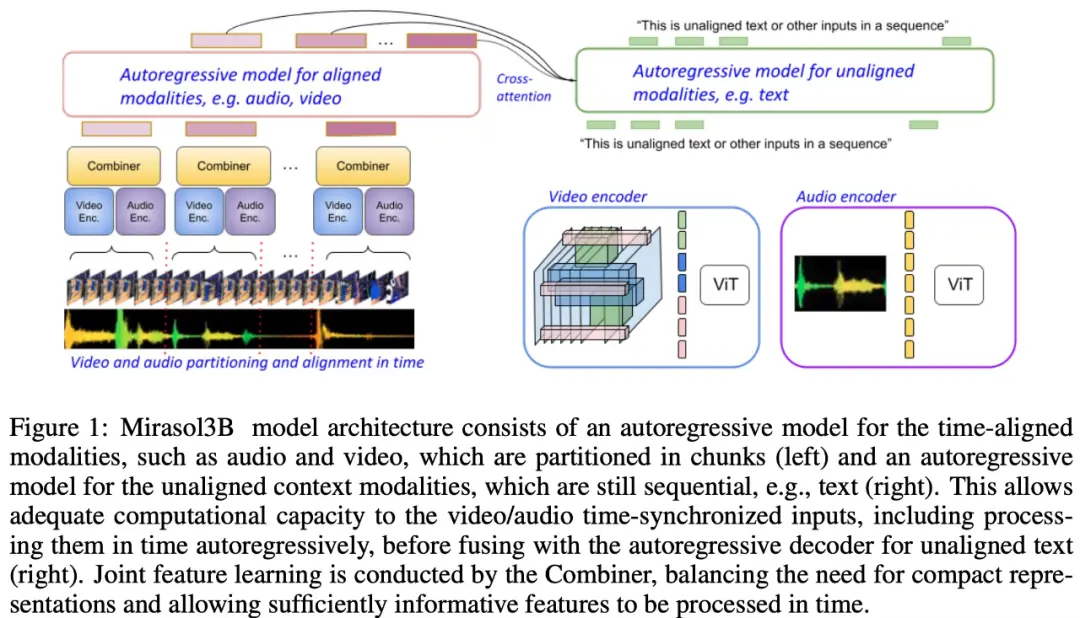
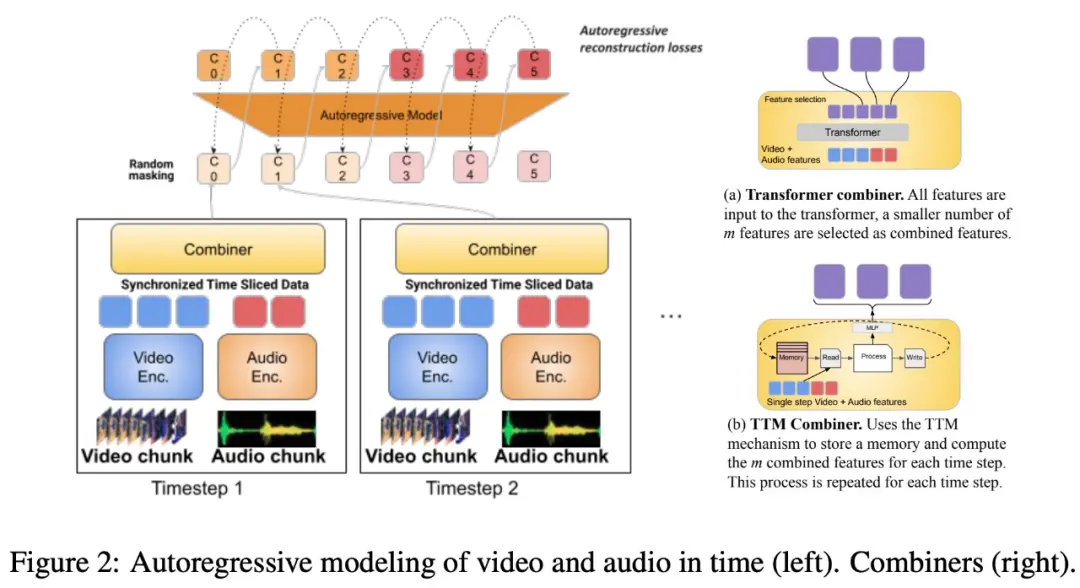 The study also proposes to segment the time-aligned modality into time periods, in which audio-video joint representations are learned. Specifically, this study proposes a modal joint feature learning mechanism called “Combiner”. “Combiner” fuses modal features from the same time period, resulting in a more compact representation.
The study also proposes to segment the time-aligned modality into time periods, in which audio-video joint representations are learned. Specifically, this study proposes a modal joint feature learning mechanism called “Combiner”. “Combiner” fuses modal features from the same time period, resulting in a more compact representation.
“Combiner” extracts the primary spatiotemporal representation from the original modal input, captures the dynamic characteristics of the video, and combines it with the synchronic audio features, so that the model can receive multimodal inputs at different rates, and performs well when processing longer videos.
“Combiner” effectively meets the needs of modal representation that is both efficient and informative. It can fully cover the events and activities in the video and other modalities that occur at the same time, and can be used in subsequent autoregressive models to learn long-term dependencies.
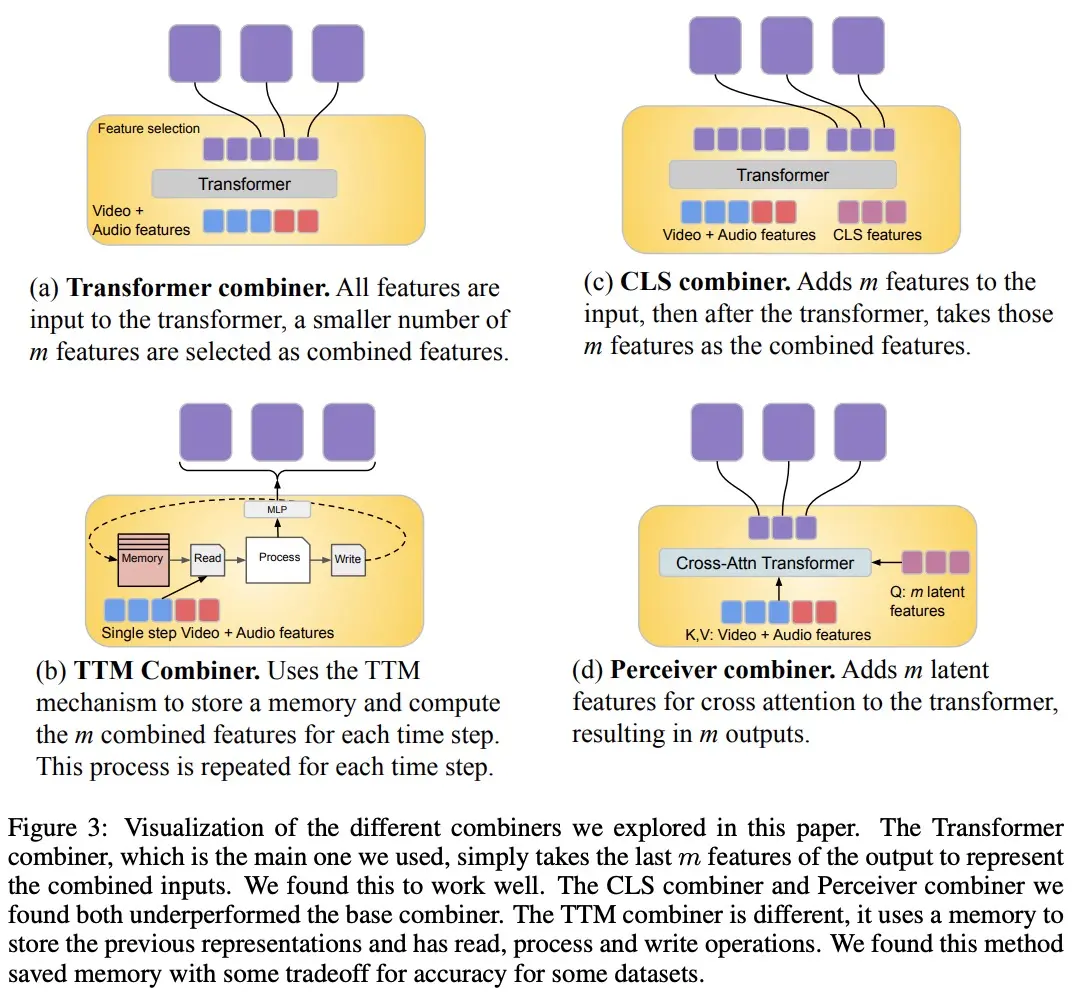 In order to process video and audio signals, and to accommodate longer video/audio inputs, they are split into (roughly synchronized in time) chunks, which are then learned to synthesize audiovisual representations through “Combiner”. The second component deals with contextual, or temporally misaligned signals, such as global text information, which is usually still continuous. It is also autoregressive and uses the combined latent space as a cross-attention input.
In order to process video and audio signals, and to accommodate longer video/audio inputs, they are split into (roughly synchronized in time) chunks, which are then learned to synthesize audiovisual representations through “Combiner”. The second component deals with contextual, or temporally misaligned signals, such as global text information, which is usually still continuous. It is also autoregressive and uses the combined latent space as a cross-attention input.
The Video + Audio learning component has 3B parameters, while the component without audio is 2.9B. Most of the semi-parameters are used for the audio + video autoregressive model. Mirasol3B typically handles videos at 128 frames, but it can also handle longer (e.g., 512 frames) videos.
Due to the design of the partition and “Combiner” model architecture, adding more frames, or increasing the size and number of blocks will only increase the parameters slightly, which solves the problem that longer videos require more parameters and larger memory.
Experiments and Results
The study tested and evaluated Mirasol3B on the standard VideoQA benchmark, the long-form video VideoQA benchmark, and the Audio+Video benchmark.
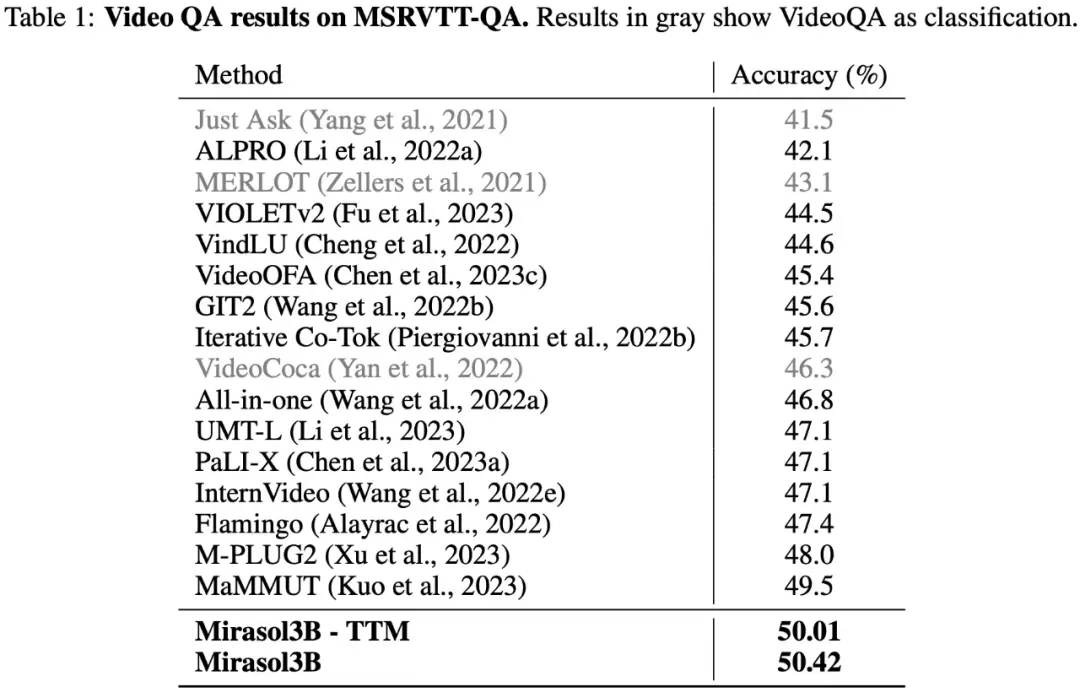
As shown in Table 1 below, the results of the tests on the VideoQA dataset MSRVTTQA show that Mirasol3B surpasses the current SOTA model, as well as larger models such as PaLI-X and Flamingo.
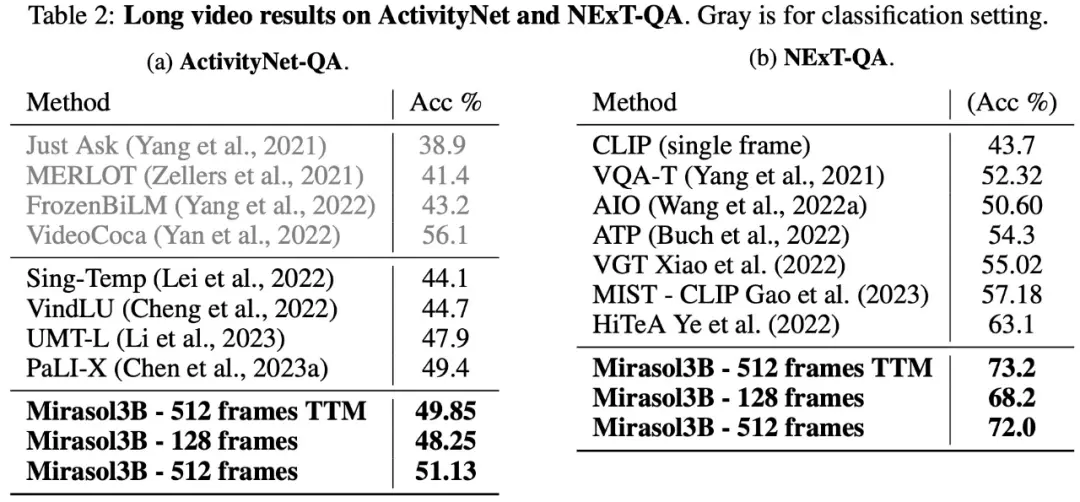
 In terms of long-form video Q&A, Mirasol3B was tested and evaluated on the ActivityNet-QA, NExTQA datasets, and the results are shown in Table 2 below:
In terms of long-form video Q&A, Mirasol3B was tested and evaluated on the ActivityNet-QA, NExTQA datasets, and the results are shown in Table 2 below:
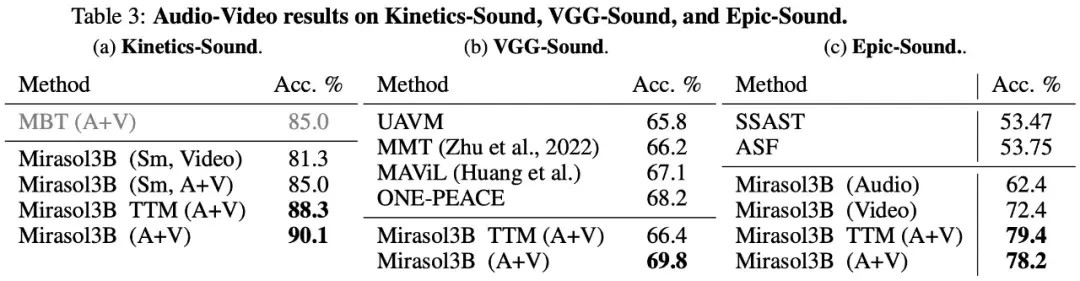
 Finally, the study chose to use KineticsSound, VGG-Sound, and Epic-Sound for audio-to-video benchmarks with open generative evaluations, as shown in Table 3 below:
Finally, the study chose to use KineticsSound, VGG-Sound, and Epic-Sound for audio-to-video benchmarks with open generative evaluations, as shown in Table 3 below:
 Interested readers can read the original paper to learn more about the research.
Interested readers can read the original paper to learn more about the research.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
