Источник статьи: Сердце машины
превосходит более крупные модели.
 Источник изображения: Сгенерировано Unbounded AI
Источник изображения: Сгенерировано Unbounded AI
Одной из основных проблем, с которыми сталкивается мультимодальное обучение, является необходимость объединения разнородных модальностей, таких как текст, аудио и видео, а мультимодальные модели должны объединять сигналы из разных источников. Однако эти модальности имеют разные характеристики, которые трудно совместить с одной моделью. Например, видео и текст имеют разную частоту дискретизации.
Недавно исследовательская группа из Google DeepMind разделила мультимодальную модель на несколько независимых, специализированных авторегрессионных моделей, которые обрабатывают входные данные на основе характеристик каждой модальности.
В частности, в исследовании предлагается мультимодальная модель Mirasol3B. Mirasol3B состоит из авторегрессионного компонента для модального окна временной синхронизации (аудио и видео) и авторегрессионного компонента для контекстной модальности. Эти модальности не обязательно выровнены по времени, но являются последовательными.
 Адрес:
Адрес:
Mirasol3B достигает уровня SOTA в мультимодальных бенчмарках, превосходя более крупные модели. Изучая более компактные представления, контролируя длину последовательности аудио-видео представлений признаков и моделируя на основе временных соответствий, Mirasol3B может эффективно удовлетворять высокие вычислительные требования мультимодальных входов.
Практическое руководство
Mirasol3B представляет собой мультимодальную модель аудио-видео-текста, в которой авторегрессионное моделирование разделено на авторегрессионные компоненты для модальностей, выровненных по времени (например, аудио, видео) и авторегрессионные компоненты для контекстуальных модальностей без выравнивания по времени (например, текста). Mirasol3B использует весовые коэффициенты перекрестного внимания для координации процесса обучения этим компонентам. Такое разделение делает распределение параметров внутри модели более разумным, а также выделяет достаточную емкость для модальностей (видео и аудио) и делает общую модель более легкой.
Как показано на рисунке 1 ниже, Mirasol3B состоит в основном из двух обучающих компонентов: авторегрессионного компонента, предназначенного для обработки (почти) синхронных мультимодальных входных данных, таких как видео + аудио, и своевременного объединения входных данных.
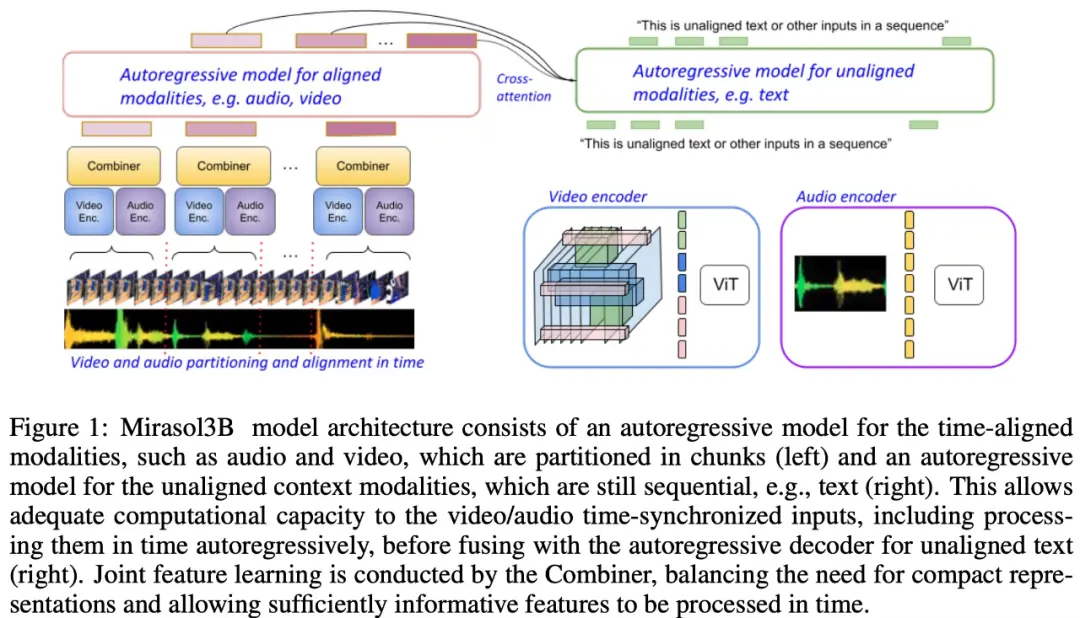
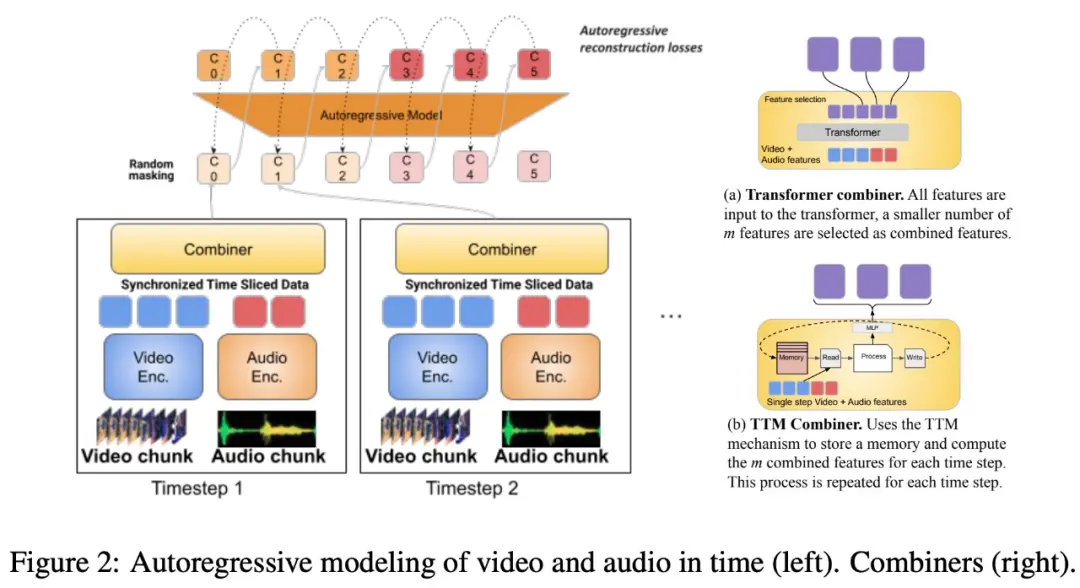 В исследовании также предлагается сегментировать выровненную по времени модальность на временные периоды, в течение которых изучаются аудио-видео совместные репрезентации. В частности, в этом исследовании предлагается механизм обучения модальным признакам суставов под названием «Combiner». “Combiner” объединяет модальные элементы из одного и того же периода времени, что приводит к более компактному представлению.
В исследовании также предлагается сегментировать выровненную по времени модальность на временные периоды, в течение которых изучаются аудио-видео совместные репрезентации. В частности, в этом исследовании предлагается механизм обучения модальным признакам суставов под названием «Combiner». “Combiner” объединяет модальные элементы из одного и того же периода времени, что приводит к более компактному представлению.
«Объединитель» извлекает первичное пространственно-временное представление из исходного модального входа, захватывает динамические характеристики видео и комбинирует их с функциями синхронного звука, так что модель может получать мультимодальные входные данные с разной скоростью и хорошо работает при обработке длинных видео.
«Комбайнер» эффективно удовлетворяет потребности модального представления, которое является одновременно эффективным и информативным. Он может полностью охватывать события и действия в видео и других модальностях, происходящих одновременно, и может использоваться в последующих моделях авторегрессии для изучения долгосрочных зависимостей.
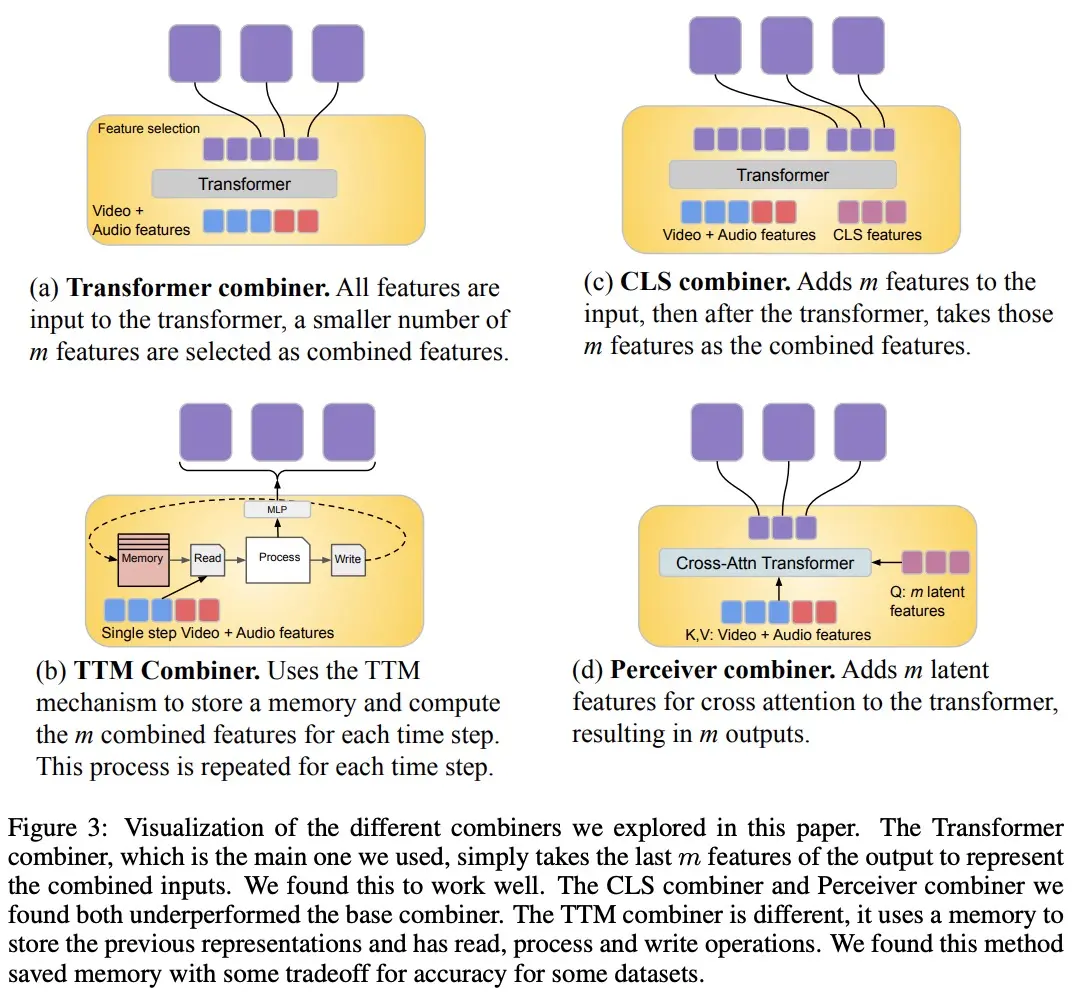 Для обработки видео- и аудиосигналов, а также для размещения более длинных видео/аудио входов, они разбиваются на (примерно синхронизированные по времени) блоки, которые затем обучаются синтезировать аудиовизуальные представления с помощью «Combiner». Второй компонент имеет дело с контекстуальными или несогласованными во времени сигналами, такими как глобальная текстовая информация, которая обычно по-прежнему непрерывна. Он также является авторегрессионным и использует объединенное латентное пространство в качестве входных данных перекрестного внимания.
Для обработки видео- и аудиосигналов, а также для размещения более длинных видео/аудио входов, они разбиваются на (примерно синхронизированные по времени) блоки, которые затем обучаются синтезировать аудиовизуальные представления с помощью «Combiner». Второй компонент имеет дело с контекстуальными или несогласованными во времени сигналами, такими как глобальная текстовая информация, которая обычно по-прежнему непрерывна. Он также является авторегрессионным и использует объединенное латентное пространство в качестве входных данных перекрестного внимания.
Компонент обучения Видео + Аудио имеет параметры 3B, в то время как компонент без звука - 2,9B. Большинство полупараметров используются для авторегрессионной модели аудио + видео. Mirasol3B обычно обрабатывает видео с частотой 128 кадров, но он также может обрабатывать более длинные видео (например, 512 кадров).
Из-за конструкции раздела и архитектуры модели “Combiner”, добавление большего количества кадров или увеличение размера и количества блоков лишь немного увеличит параметры, что решает проблему, что более длинные видео требуют большего количества параметров и большего объема памяти.
Эксперименты и результаты
В ходе исследования Mirasol3B был протестирован и оценен в стандартном бенчмарке VideoQA, бенчмарке длинного видео VideoQA и бенчмарке Audio+Video.
Как показано в таблице 1 ниже, результаты тестов на наборе данных VideoQA MSRVTTQA показывают, что Mirasol3B превосходит текущую модель SOTA, а также более крупные модели, такие как PaLI-X и Flamingo.
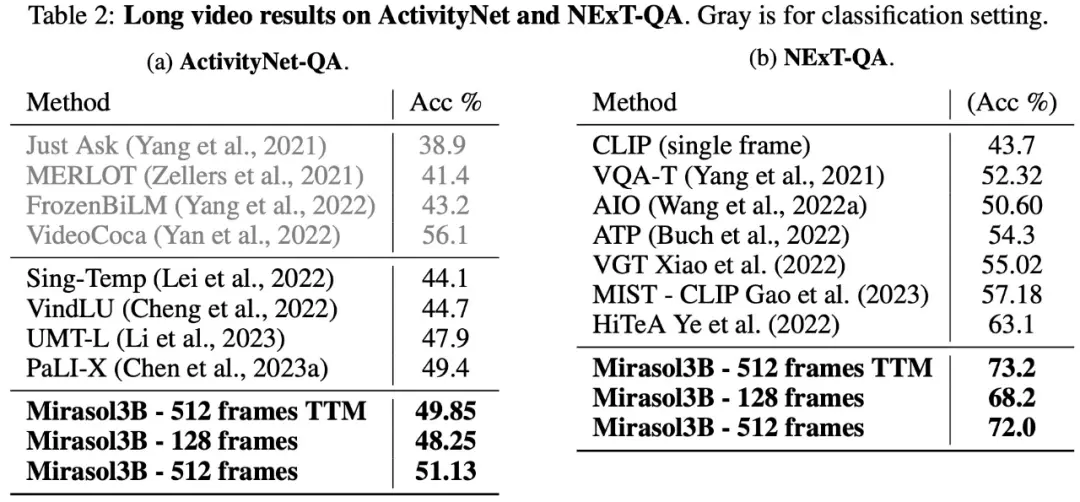
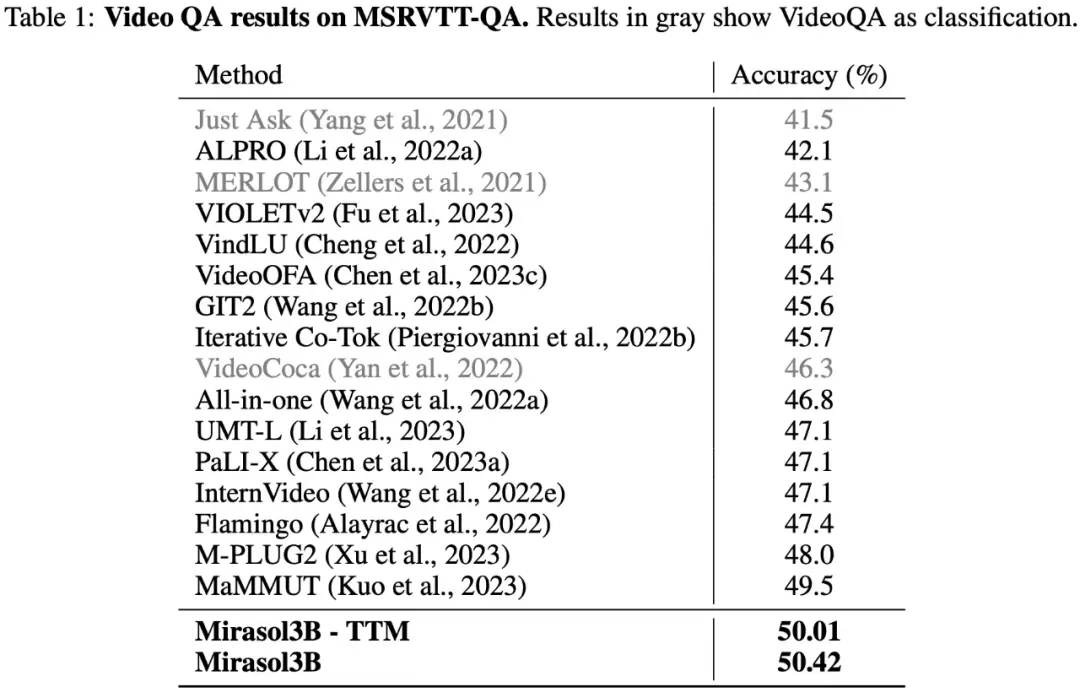 С точки зрения длинных видеовопросов и ответов, Mirasol3B был протестирован и оценен на наборах данных ActivityNet-QA, NExTQA, и результаты показаны в таблице 2 ниже:
С точки зрения длинных видеовопросов и ответов, Mirasol3B был протестирован и оценен на наборах данных ActivityNet-QA, NExTQA, и результаты показаны в таблице 2 ниже:
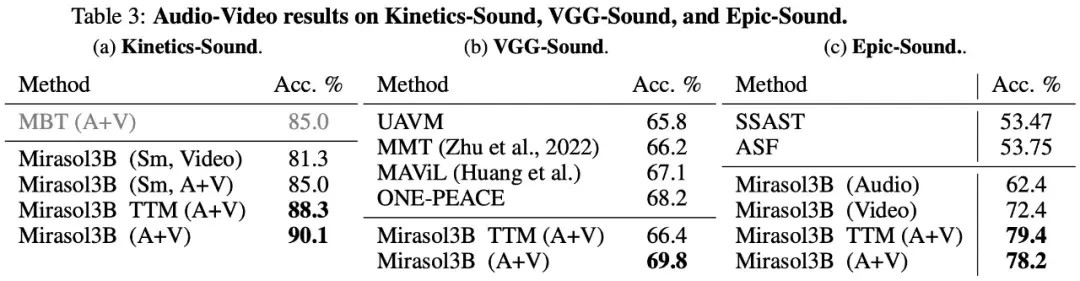
 Наконец, в исследовании было решено использовать KineticsSound, VGG-Sound и Epic-Sound для аудио-видео тестов с открытыми генеративными оценками, как показано в таблице 3 ниже:
Наконец, в исследовании было решено использовать KineticsSound, VGG-Sound и Epic-Sound для аудио-видео тестов с открытыми генеративными оценками, как показано в таблице 3 ниже:
 Заинтересованные читатели могут прочитать оригинальную статью, чтобы узнать больше об исследовании.
Заинтересованные читатели могут прочитать оригинальную статью, чтобы узнать больше об исследовании.
Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.