Fonte do artigo: Heart of the Machine
supera modelos maiores.
 Fonte da imagem: Gerada por Unbounded AI
Fonte da imagem: Gerada por Unbounded AI
Um dos principais desafios enfrentados pela aprendizagem multimodal é a necessidade de fundir modalidades heterogéneas como texto, áudio e vídeo, e os modelos multimodais têm de combinar sinais de diferentes fontes. No entanto, estas modalidades têm características diferentes que são difíceis de combinar com um único modelo. Por exemplo, vídeo e texto têm taxas de amostragem diferentes.
Recentemente, uma equipe de pesquisa do Google DeepMind desacoplou o modelo multimodal em vários modelos autorregressivos independentes e especializados que processam entradas com base nas características de cada modalidade.
Especificamente, o estudo propõe um modelo multimodal, Mirasol3B. Mirasol3B consiste em um componente autorregressivo para o modal de sincronização temporal (áudio e vídeo), e um componente autorregressivo para a modalidade de contexto. Estas modalidades não são necessariamente alinhadas no tempo, mas são sequenciais.
 Endereço:
Endereço:
Mirasol3B atinge níveis SOTA em benchmarks multimodais, superando modelos maiores. Ao aprender representações mais compactas, controlar o comprimento da sequência de representações de recursos de áudio e vídeo e modelar com base na correspondência temporal, Mirasol3B é capaz de atender efetivamente aos altos requisitos computacionais de entradas multimodais.
Introdução de instruções
Mirasol3B é um modelo multimodal áudio-vídeo-texto no qual a modelagem autorregressiva é dissociada em componentes autorregressivos para modalidades alinhadas no tempo (por exemplo, áudio, vídeo) e componentes autorregressivos para modalidades contextuais não alinhadas no tempo (por exemplo, texto). Mirasol3B utiliza pesos de atenção cruzada para coordenar o processo de aprendizagem destes componentes. Este desacoplamento torna a distribuição de parâmetros dentro do modelo mais razoável, também aloca capacidade suficiente para as modalidades (vídeo e áudio), e torna o modelo geral mais leve.
Como mostrado na Figura 1 abaixo, Mirasol3B consiste principalmente em dois componentes de aprendizagem: um componente autorregressivo, projetado para processar entradas multimodais (quase) síncronas, como vídeo + áudio, e combinar as entradas em tempo hábil.
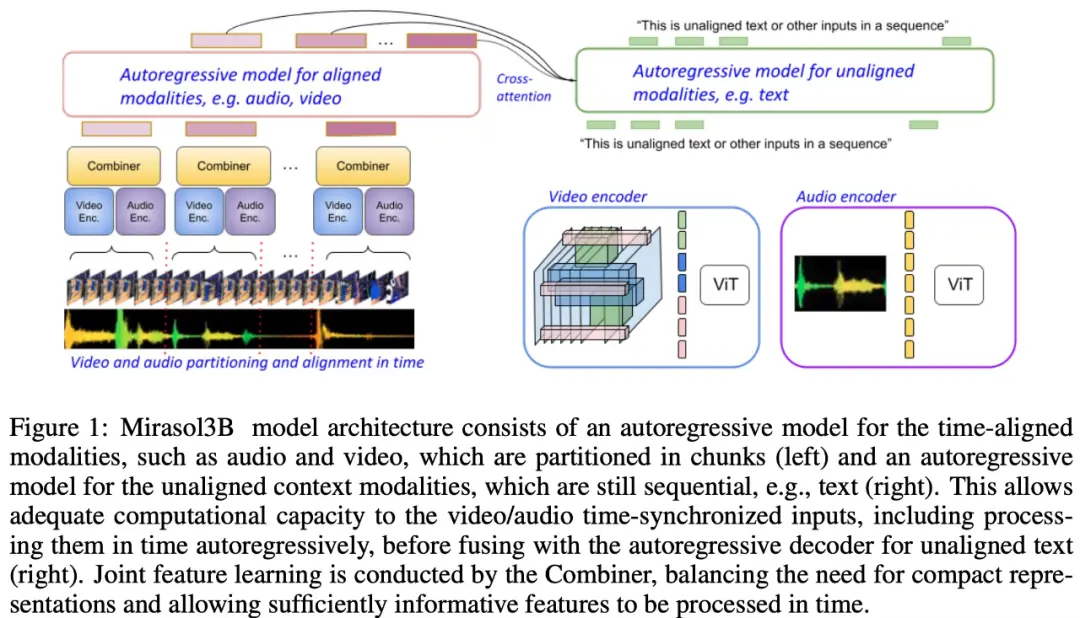
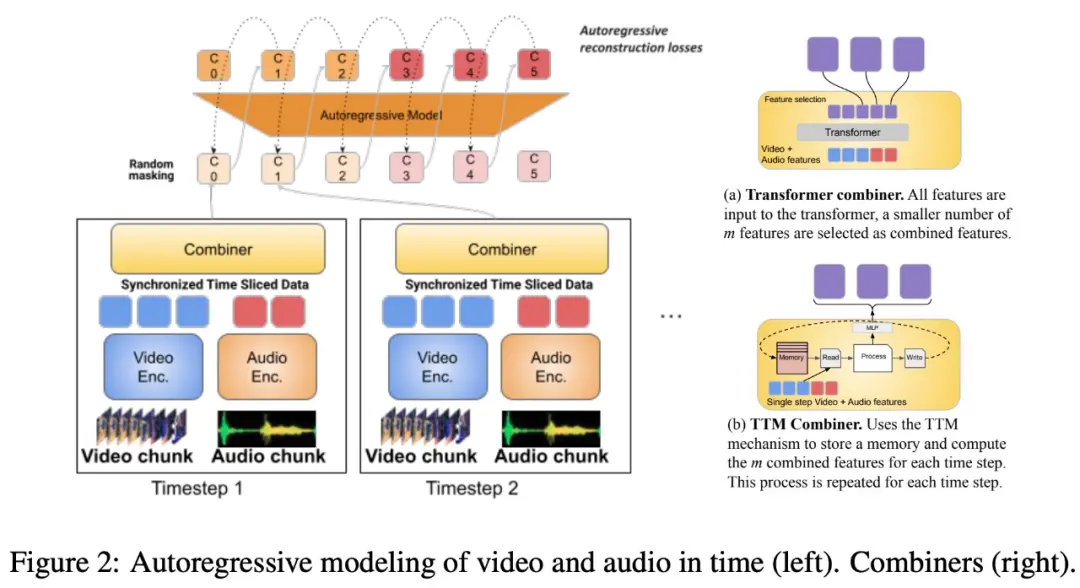 O estudo também propõe segmentar a modalidade alinhada no tempo em períodos de tempo, nos quais são aprendidas representações conjuntas áudio-vídeo. Especificamente, este estudo propõe um mecanismo de aprendizagem de características articulares modais denominado “Combinador”. O “combinador” funde características modais do mesmo período de tempo, resultando numa representação mais compacta.
O estudo também propõe segmentar a modalidade alinhada no tempo em períodos de tempo, nos quais são aprendidas representações conjuntas áudio-vídeo. Especificamente, este estudo propõe um mecanismo de aprendizagem de características articulares modais denominado “Combinador”. O “combinador” funde características modais do mesmo período de tempo, resultando numa representação mais compacta.
“Combiner” extrai a representação espaço-temporal primária da entrada modal original, captura as características dinâmicas do vídeo e combina-a com os recursos de áudio sincrônicos, para que o modelo possa receber entradas multimodais em diferentes taxas e tenha um bom desempenho ao processar vídeos mais longos.
“Combinador” atende efetivamente às necessidades de representação modal que é eficiente e informativa. Ele pode cobrir totalmente os eventos e atividades no vídeo e outras modalidades que ocorrem ao mesmo tempo, e pode ser usado em modelos autorregressivos subsequentes para aprender dependências de longo prazo.
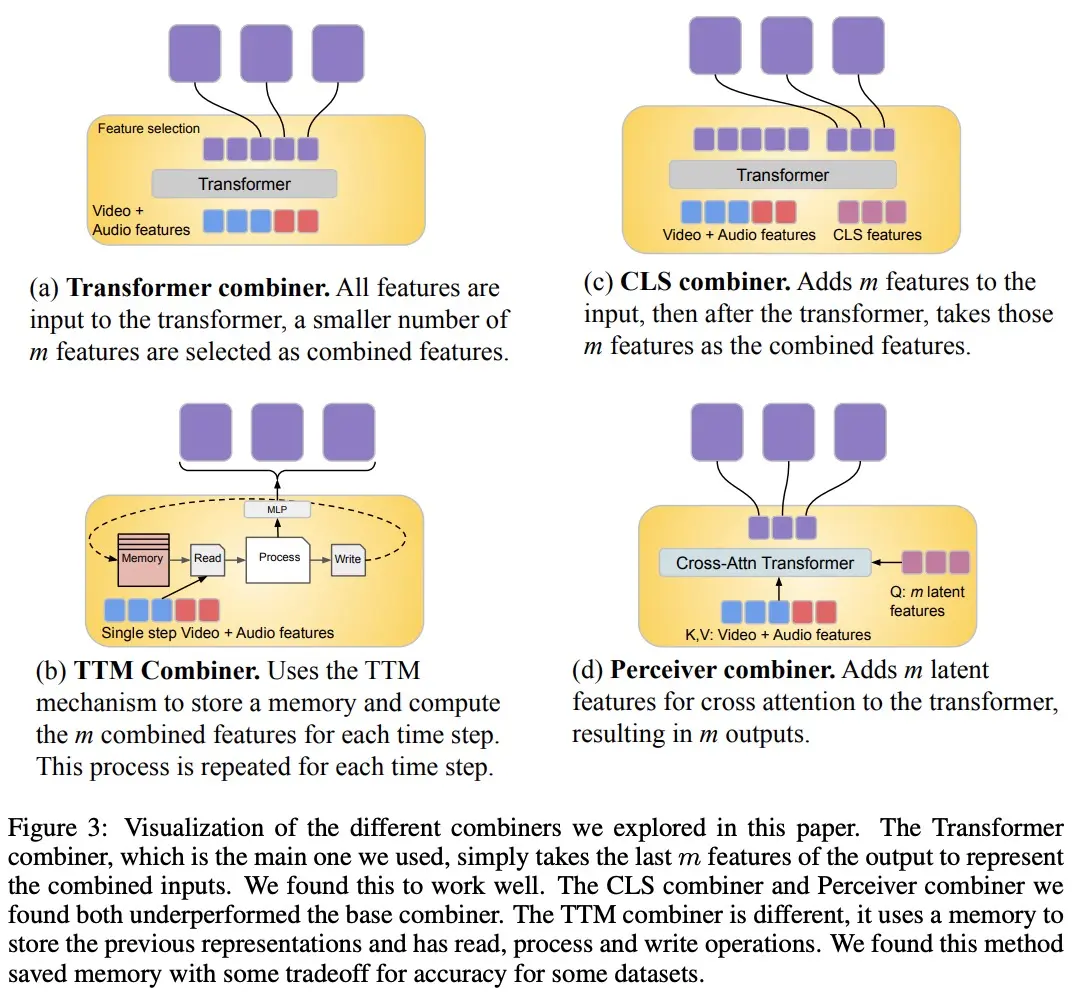 A fim de processar sinais de vídeo e áudio, e para acomodar entradas de vídeo / áudio mais longas, eles são divididos em partes (aproximadamente sincronizadas no tempo), que são então aprendidas a sintetizar representações audiovisuais através do “Combinador”. O segundo componente lida com sinais contextuais ou temporalmente desalinhados, como informações de texto global, que geralmente ainda são contínuas. Também é autorregressivo e usa o espaço latente combinado como uma entrada de atenção cruzada.
A fim de processar sinais de vídeo e áudio, e para acomodar entradas de vídeo / áudio mais longas, eles são divididos em partes (aproximadamente sincronizadas no tempo), que são então aprendidas a sintetizar representações audiovisuais através do “Combinador”. O segundo componente lida com sinais contextuais ou temporalmente desalinhados, como informações de texto global, que geralmente ainda são contínuas. Também é autorregressivo e usa o espaço latente combinado como uma entrada de atenção cruzada.
O componente de aprendizagem de vídeo + áudio tem parâmetros 3B, enquanto o componente sem áudio é 2.9B. A maioria dos semi-parâmetros são usados para o modelo autorregressivo de áudio + vídeo. Mirasol3B normalmente lida com vídeos em 128 quadros, mas também pode lidar com vídeos mais longos (por exemplo, 512 quadros).
Devido ao design da partição e arquitetura do modelo “Combiner”, adicionar mais quadros, ou aumentar o tamanho e o número de blocos só aumentará ligeiramente os parâmetros, o que resolve o problema de que vídeos mais longos exigem mais parâmetros e maior memória.
Experiências e Resultados
O estudo testou e avaliou o Mirasol3B no benchmark VideoQA padrão, no benchmark VideoQA de vídeo de forma longa e no benchmark Audio+Video.
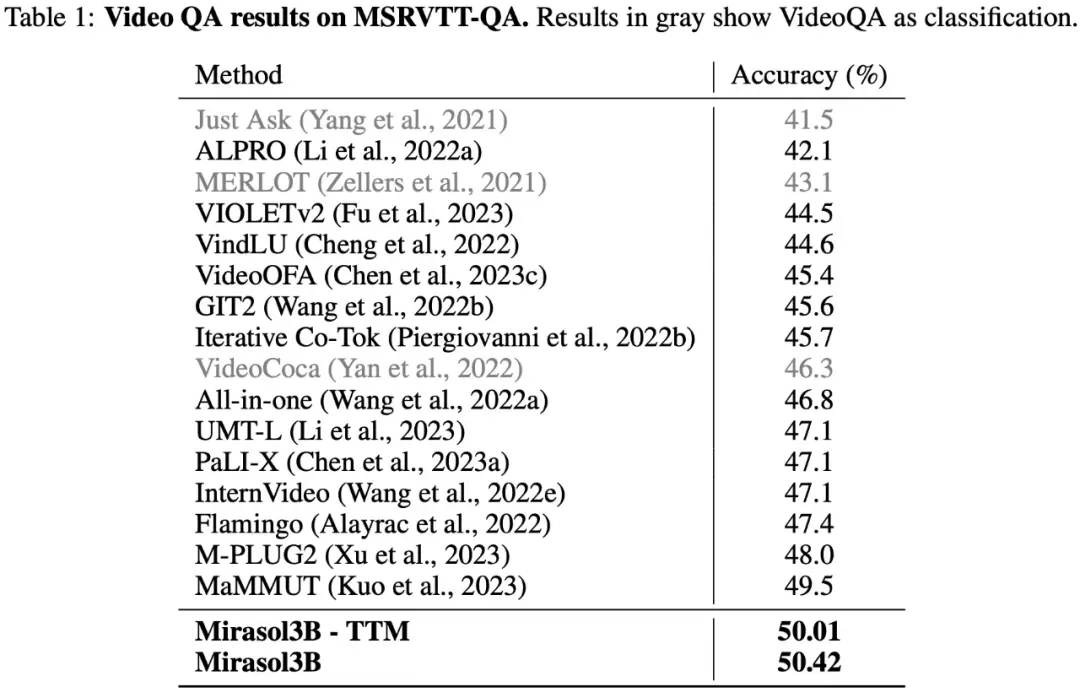
Como mostrado na Tabela 1 abaixo, os resultados dos testes no conjunto de dados VideoQA MSRVTTQA mostram que Mirasol3B supera o modelo SOTA atual, bem como modelos maiores como PaLI-X e Flamingo.
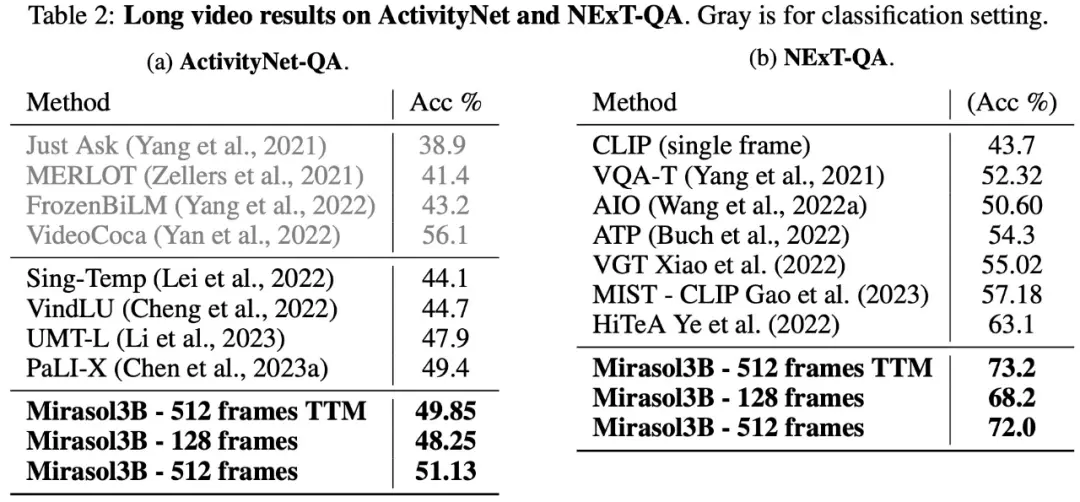
 Em termos de Q&&A de vídeo de forma longa, Mirasol3B foi testado e avaliado nos conjuntos de dados ActivityNet-QA, NExTQA, e os resultados são mostrados na Tabela 2 abaixo:
Em termos de Q&&A de vídeo de forma longa, Mirasol3B foi testado e avaliado nos conjuntos de dados ActivityNet-QA, NExTQA, e os resultados são mostrados na Tabela 2 abaixo:
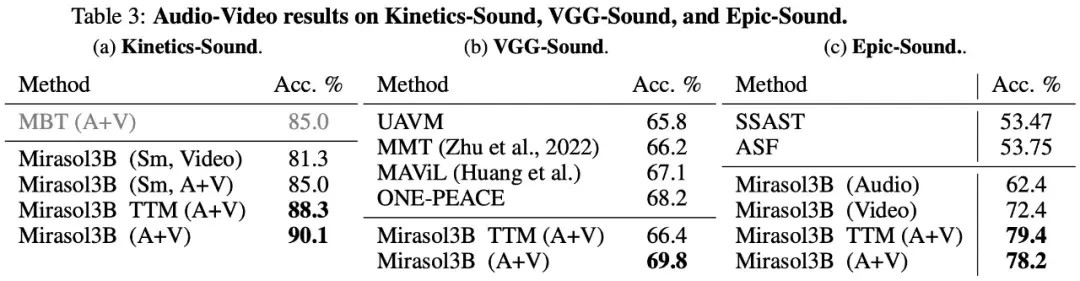
 Finalmente, o estudo optou por usar KineticsSound, VGG-Sound e Epic-Sound para benchmarks de áudio para vídeo com avaliações generativas abertas, como mostra a Tabela 3 abaixo:
Finalmente, o estudo optou por usar KineticsSound, VGG-Sound e Epic-Sound para benchmarks de áudio para vídeo com avaliações generativas abertas, como mostra a Tabela 3 abaixo:
 Os leitores interessados podem ler o artigo original para saber mais sobre a pesquisa.
Os leitores interessados podem ler o artigo original para saber mais sobre a pesquisa.
Isenção de responsabilidade: As informações contidas nesta página podem ser provenientes de terceiros e não representam os pontos de vista ou opiniões da Gate. O conteúdo apresentado nesta página é apenas para referência e não constitui qualquer aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou o carácter exaustivo das informações e não poderá ser responsabilizada por quaisquer perdas resultantes da utilização destas informações. Os investimentos em ativos virtuais implicam riscos elevados e estão sujeitos a uma volatilidade de preços significativa. Pode perder todo o seu capital investido. Compreenda plenamente os riscos relevantes e tome decisões prudentes com base na sua própria situação financeira e tolerância ao risco. Para mais informações, consulte a
Isenção de responsabilidade.