小型で効率的:DeepMindがマルチモーダルソリューション「Mirasol 3B」を発表
記事のソース: Heart of the Machine
は、より大きなモデルよりも優れています。
 画像出典:Unbounded AIによって生成
画像出典:Unbounded AIによって生成
マルチモーダル学習が直面する主な課題の1つは、テキスト、オーディオ、ビデオなどの異種モダリティを融合する必要性であり、マルチモーダルモデルは異なるソースからの信号を組み合わせる必要があります。 ただし、これらのモダリティには異なる特性があり、単一のモデルと組み合わせることは困難です。 たとえば、ビデオとテキストではサンプルレートが異なります。
最近、Google DeepMindの研究チームは、マルチモーダルモデルを、各モダリティの特性に基づいて入力を処理する複数の独立した特殊な自己回帰モデルに分離しました。
具体的には、マルチモーダルモデルであるMirasol3Bを提案しています。 Mirasol3Bは、時間同期モーダル(オーディオとビデオ)の自己回帰コンポーネントと、コンテキストモダリティの自己回帰コンポーネントで構成されています。 これらのモダリティは必ずしも時間的に整列しているわけではなく、順次的です。
 住所:
住所:
Mirasol3Bは、マルチモーダルベンチマークでSOTAレベルを達成し、大規模なモデルを凌駕しています。 Mirasol3Bは、よりコンパクトな表現を学習し、オーディオビデオ特徴表現のシーケンス長を制御し、時間的対応に基づいてモデル化することで、マルチモーダル入力の高い計算要件を効果的に満たすことができます。
ハウツー紹介
Mirasol3Bは、オーディオ-ビデオ-テキストのマルチモーダルモデルであり、自己回帰モデリングは、時間的に整合したモダリティ(オーディオ、ビデオなど)の自己回帰コンポーネントと、時間的に整列していないコンテキストモダリティ(テキストなど)の自己回帰コンポーネントに分離されています。 Mirasol3Bは、クロスアテンションの重み付けを使用して、これらのコンポーネントの学習プロセスを調整します。 この分離により、モデル内のパラメーターの分布がより合理的になり、モダリティ(ビデオとオーディオ)に十分な容量が割り当てられ、モデル全体がより軽量になります。
下の図1に示すように、Mirasol3Bは主に2つの学習コンポーネントで構成されています:ビデオ+オーディオなどの(ほぼ)同期的なマルチモーダル入力を処理し、入力をタイムリーに組み合わせるように設計された自己回帰コンポーネントです。
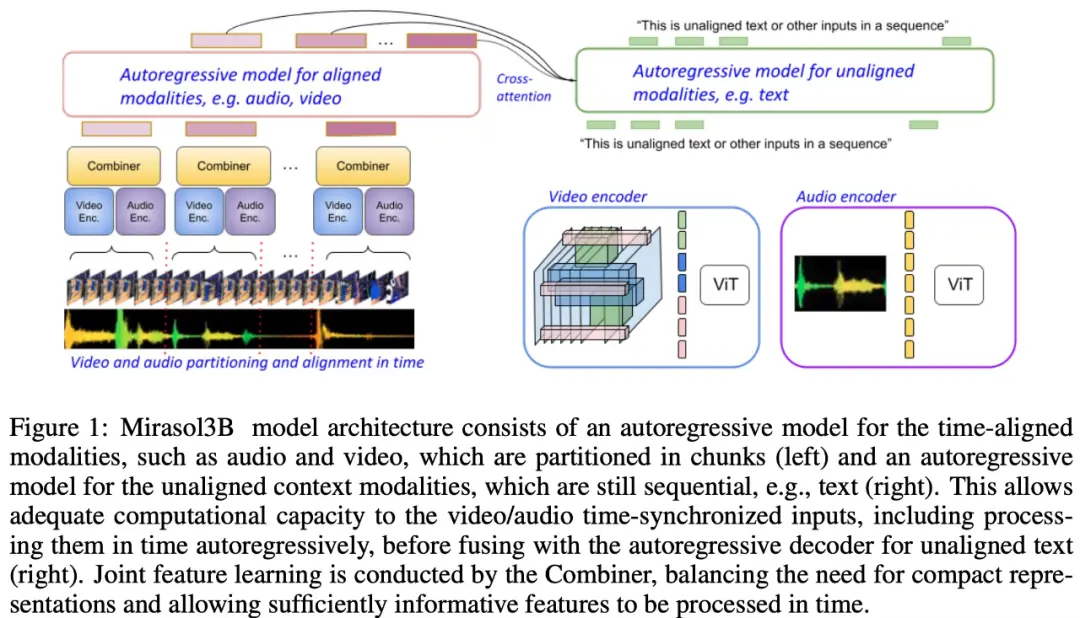
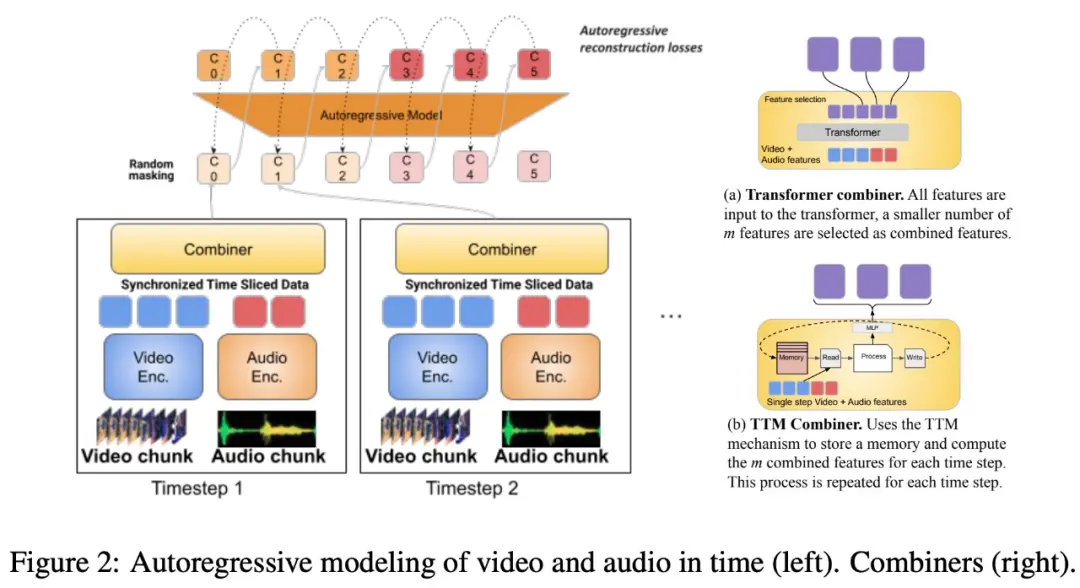 また、この研究では、時間的に整列したモダリティを、オーディオとビデオの結合表現が学習される期間にセグメント化することを提案しています。 具体的には、本研究では「コンバイナー」と呼ばれるモーダル関節特徴学習メカニズムを提案します。 「コンバイナー」は、同じ期間のモーダル特徴を融合し、よりコンパクトな表現を実現します。
また、この研究では、時間的に整列したモダリティを、オーディオとビデオの結合表現が学習される期間にセグメント化することを提案しています。 具体的には、本研究では「コンバイナー」と呼ばれるモーダル関節特徴学習メカニズムを提案します。 「コンバイナー」は、同じ期間のモーダル特徴を融合し、よりコンパクトな表現を実現します。
「Combiner」は、元のモーダル入力から主要な時空間表現を抽出し、ビデオの動的特性をキャプチャし、それを共時オーディオ機能と組み合わせることで、モデルがさまざまなレートでマルチモーダル入力を受信できるようにし、より長いビデオを処理するときに優れたパフォーマンスを発揮します。
「Combiner」は、効率的で有益なモーダル表現のニーズを効果的に満たします。 これは、ビデオ内のイベントやアクティビティ、および同時に発生する他のモダリティを完全にカバーでき、その後の自己回帰モデルで長期的な依存関係を学習するために使用できます。
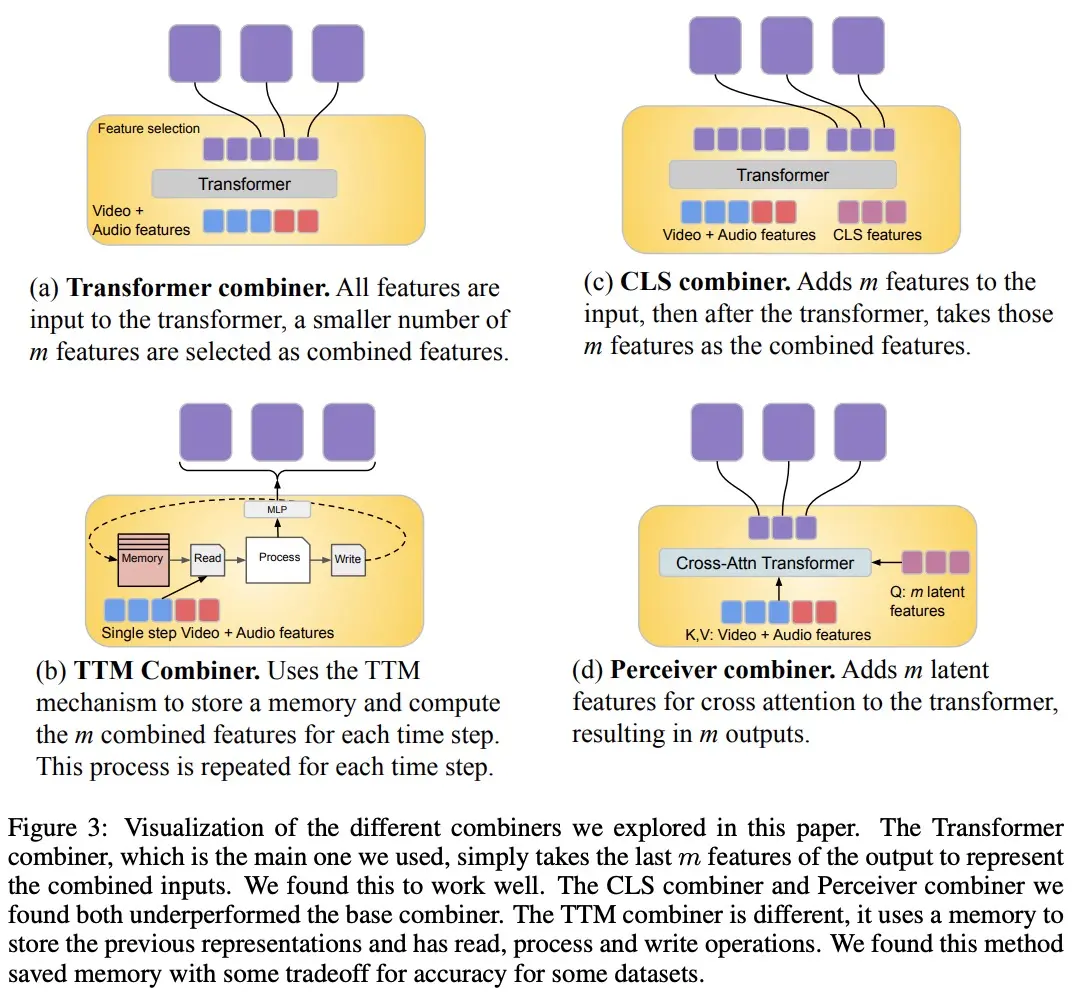 ビデオ信号とオーディオ信号を処理し、より長いビデオ/オーディオ入力に対応するために、それらは(時間的にほぼ同期された)チャンクに分割され、「コンバイナー」を介してオーディオビジュアル表現を合成するために学習されます。 2 番目のコンポーネントは、コンテキスト上の信号、または時間的に位置がずれた信号 (通常は連続しているグローバル テキスト情報など) を扱います。 また、自己回帰的であり、結合された潜在空間をクロスアテンション入力として使用します。
ビデオ信号とオーディオ信号を処理し、より長いビデオ/オーディオ入力に対応するために、それらは(時間的にほぼ同期された)チャンクに分割され、「コンバイナー」を介してオーディオビジュアル表現を合成するために学習されます。 2 番目のコンポーネントは、コンテキスト上の信号、または時間的に位置がずれた信号 (通常は連続しているグローバル テキスト情報など) を扱います。 また、自己回帰的であり、結合された潜在空間をクロスアテンション入力として使用します。
ビデオ + オーディオ学習コンポーネントには 3B のパラメーターがありますが、オーディオなしのコンポーネントには 2.9B のパラメーターがあります。 ほとんどのセミパラメータは、オーディオ+ビデオの自己回帰モデルに使用されます。 Mirasol3Bは通常、128フレームの動画を処理しますが、より長い(512フレームなど)動画も処理できます。
パーティションと「コンバイナー」モデルアーキテクチャの設計により、フレームを追加したり、ブロックのサイズと数を増やしたりしても、パラメータがわずかに増加するだけで、長いビデオにはより多くのパラメータとより大きなメモリが必要になるという問題が解決されます。
実験と結果
この調査では、Mirasol3Bを標準のVideoQAベンチマーク、長編ビデオVideoQAベンチマーク、およびオーディオ+ビデオベンチマークでテストおよび評価しました。
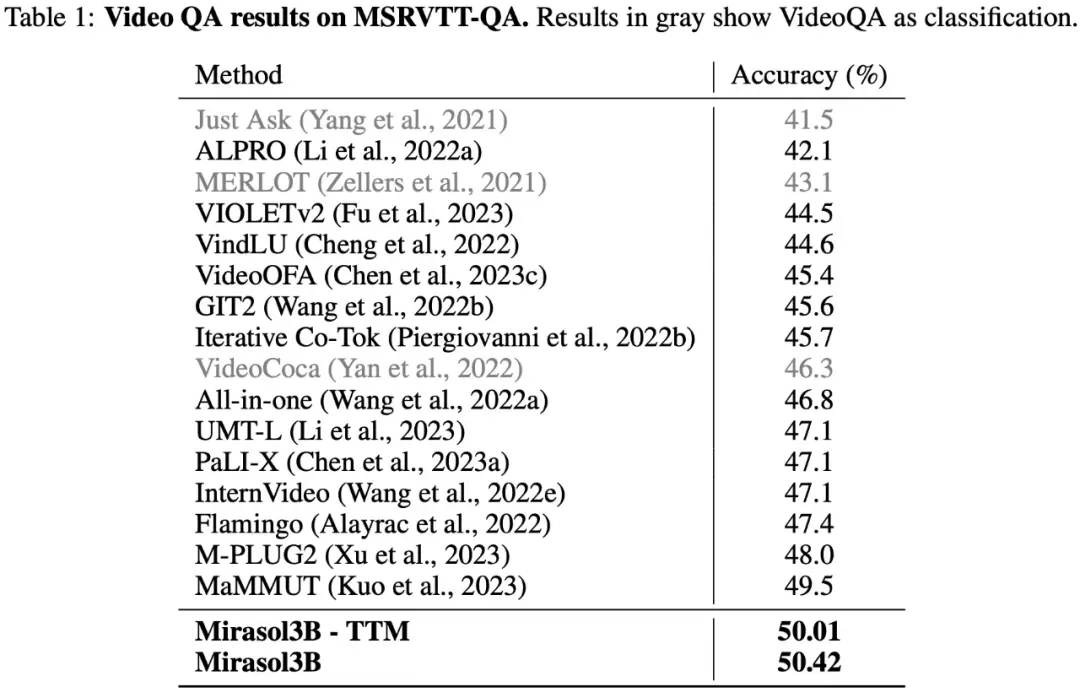
下の表1に示すように、VideoQAデータセットMSRVTTQAでのテスト結果は、Mirasol3Bが現在のSOTAモデルだけでなく、PaLI-XやFlamingoなどのより大きなモデルを上回っていることを示しています。
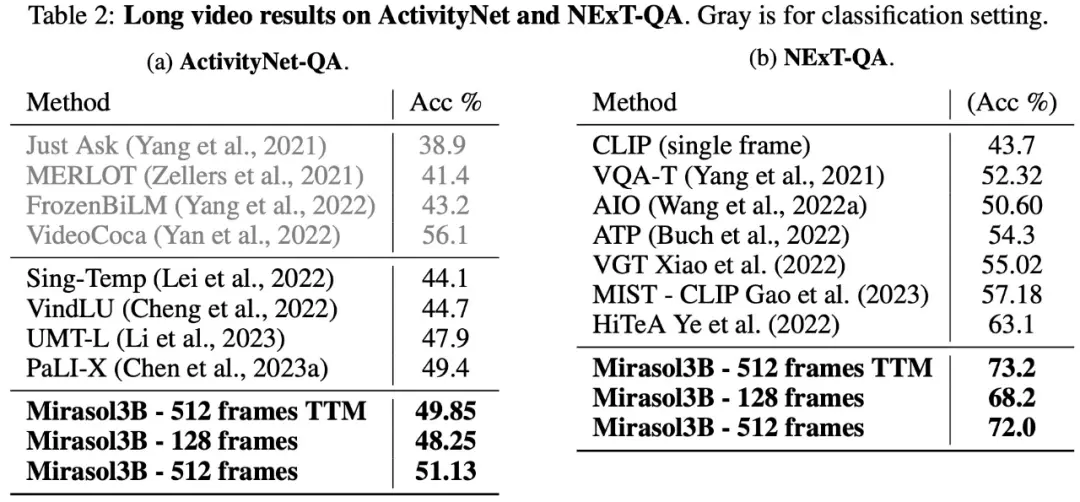
 長編ビデオQ&Aに関しては、Mirasol3BをActivityNet-QA、NExTQAデータセットでテストおよび評価し、その結果を以下の表2に示します。
長編ビデオQ&Aに関しては、Mirasol3BをActivityNet-QA、NExTQAデータセットでテストおよび評価し、その結果を以下の表2に示します。
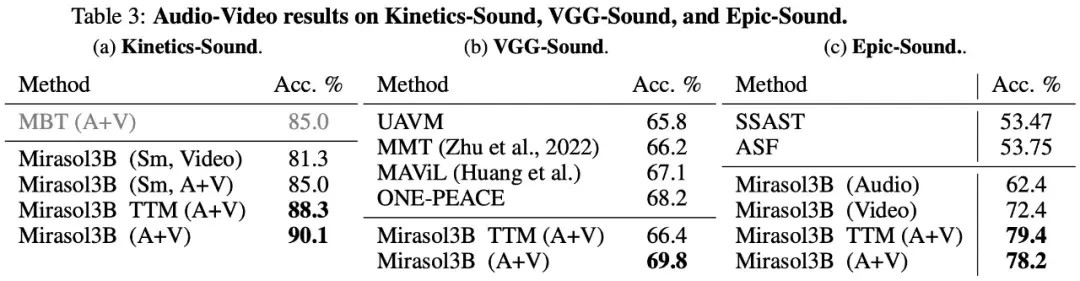
 最後に、この研究では、以下の表3に示すように、オープンジェネレーティブ評価によるオーディオからビデオへのベンチマークにKineticsSound、VGG-Sound、およびEpic-Soundを使用することを選択しました。
最後に、この研究では、以下の表3に示すように、オープンジェネレーティブ評価によるオーディオからビデオへのベンチマークにKineticsSound、VGG-Sound、およびEpic-Soundを使用することを選択しました。
 興味のある読者は、元の論文を読んで、研究の詳細を知ることができます。
興味のある読者は、元の論文を読んで、研究の詳細を知ることができます。