Sumber artikel: Heart of the Machine
mengungguli model yang lebih besar.
 Sumber gambar: Dihasilkan oleh Unbounded AI
Sumber gambar: Dihasilkan oleh Unbounded AI
Salah satu tantangan utama yang dihadapi oleh pembelajaran multimodal adalah kebutuhan untuk memadukan modalitas heterogen seperti teks, audio, dan video, dan model multimodal perlu menggabungkan sinyal dari sumber yang berbeda. Namun, modalitas ini memiliki karakteristik berbeda yang sulit digabungkan dengan model tunggal. Misalnya, video dan teks memiliki laju sampel yang berbeda.
Baru-baru ini, tim peneliti dari Google DeepMind memisahkan model multimodal menjadi beberapa model autoregresif independen dan khusus yang memproses input berdasarkan karakteristik masing-masing modalitas.
Secara khusus, penelitian ini mengusulkan model multimodal, Mirasol3B. Mirasol3B terdiri dari komponen autoregresif untuk modal sinkronisasi temporal (audio dan video), dan komponen autoregresif untuk modalitas konteks. Modalitas ini tidak selalu selaras dengan waktu, tetapi berurutan.
 Alamat:
Alamat:
Mirasol3B mencapai tingkat SOTA dalam tolok ukur multimodal, mengungguli model yang lebih besar. Dengan mempelajari representasi yang lebih ringkas, mengendalikan panjang urutan representasi fitur audio-video, dan pemodelan berdasarkan korespondensi temporal, Mirasol3B mampu secara efektif memenuhi persyaratan komputasi input multimodal yang tinggi.
Cara Pendahuluan
Mirasol3B adalah model multimodal audio-video-teks di mana pemodelan autoregresif dipisahkan menjadi komponen autoregresif untuk modalitas yang selaras dengan waktu (misalnya, audio, video) dan komponen autoregresif untuk modalitas kontekstual yang tidak selaras dengan waktu (misalnya, teks). Mirasol3B menggunakan bobot perhatian silang untuk mengoordinasikan proses pembelajaran komponen-komponen ini. Pemisahan ini membuat distribusi parameter dalam model lebih masuk akal, juga mengalokasikan kapasitas yang cukup untuk modalitas (video dan audio), dan membuat model keseluruhan lebih ringan.
Seperti yang ditunjukkan pada Gambar 1 di bawah ini, Mirasol3B terutama terdiri dari dua komponen pembelajaran: komponen autoregresif, yang dirancang untuk memproses (hampir) input multimodal sinkron, seperti video + audio, dan menggabungkan input secara tepat waktu.
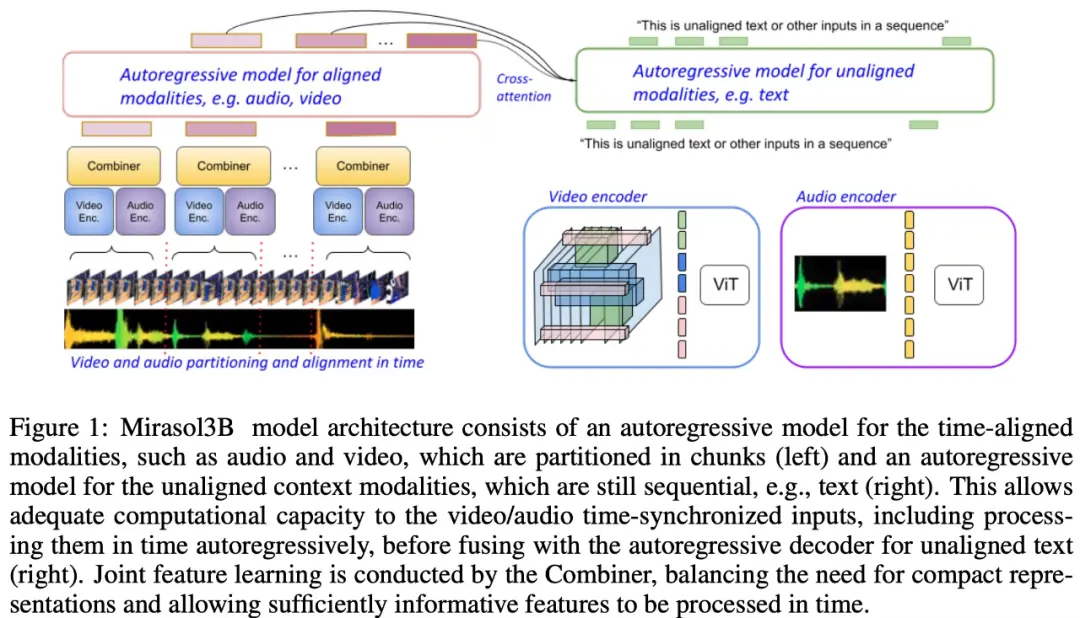
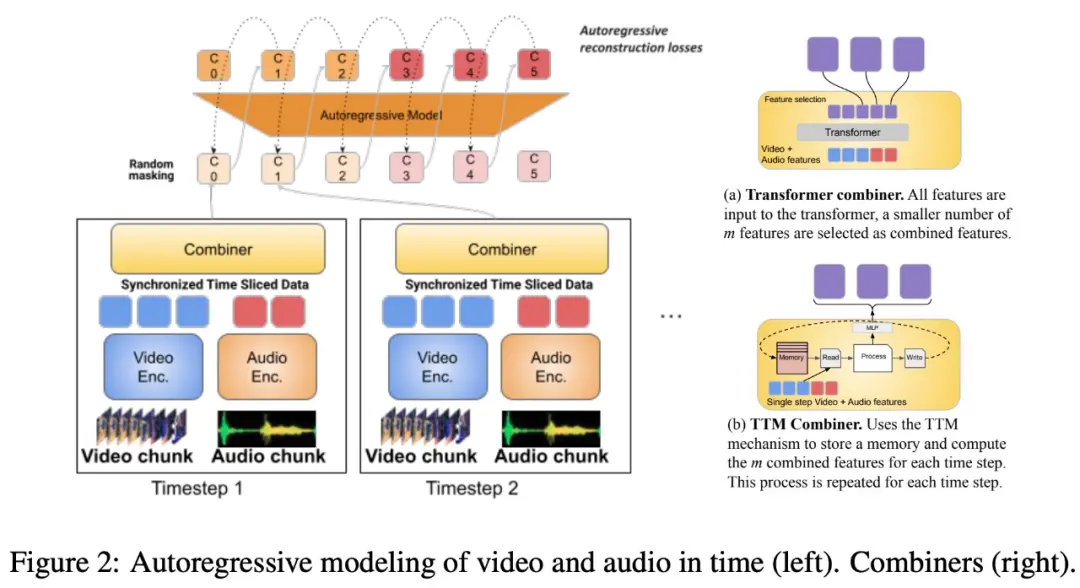 Studi ini juga mengusulkan untuk mengelompokkan modalitas selaras waktu ke dalam periode waktu, di mana representasi bersama audio-video dipelajari. Secara khusus, penelitian ini mengusulkan mekanisme pembelajaran fitur gabungan modal yang disebut “Combiner”. “Combiner” memadukan fitur modal dari periode waktu yang sama, menghasilkan representasi yang lebih ringkas.
Studi ini juga mengusulkan untuk mengelompokkan modalitas selaras waktu ke dalam periode waktu, di mana representasi bersama audio-video dipelajari. Secara khusus, penelitian ini mengusulkan mekanisme pembelajaran fitur gabungan modal yang disebut “Combiner”. “Combiner” memadukan fitur modal dari periode waktu yang sama, menghasilkan representasi yang lebih ringkas.
“Combiner” mengekstrak representasi spatiotemporal utama dari input modal asli, menangkap karakteristik dinamis video, dan menggabungkannya dengan fitur audio sinkronik, sehingga model dapat menerima input multimodal pada tingkat yang berbeda, dan berkinerja baik saat memproses video yang lebih panjang.
“Combiner” secara efektif memenuhi kebutuhan representasi modal yang efisien dan informatif. Ini dapat sepenuhnya mencakup peristiwa dan aktivitas dalam video dan modalitas lain yang terjadi pada saat yang sama, dan dapat digunakan dalam model autoregresif berikutnya untuk mempelajari dependensi jangka panjang.
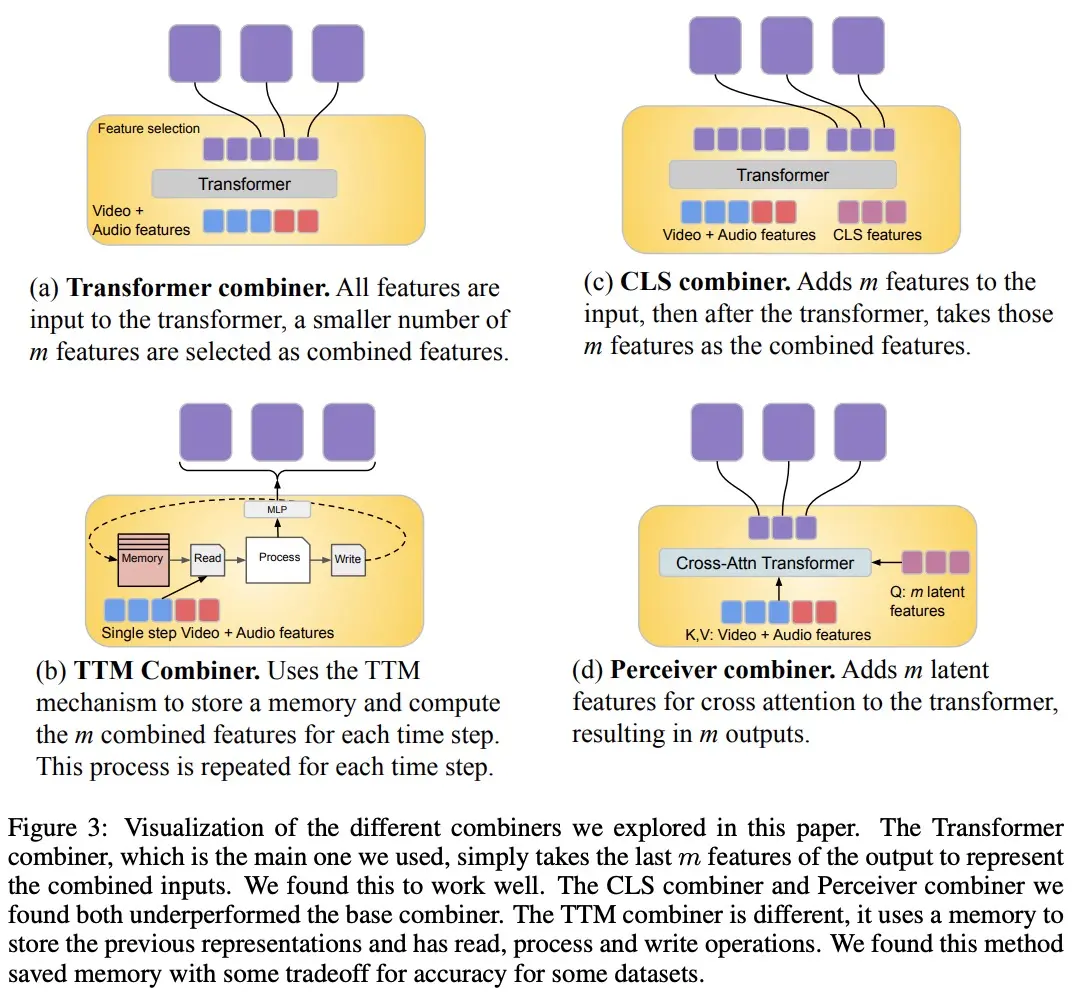 Untuk memproses sinyal video dan audio, dan untuk mengakomodasi input video / audio yang lebih panjang, mereka dibagi menjadi potongan-potongan (kira-kira disinkronkan dalam waktu), yang kemudian dipelajari untuk mensintesis representasi audiovisual melalui “Combiner”. Komponen kedua berkaitan dengan sinyal kontekstual, atau temporal yang tidak selaras, seperti informasi teks global, yang biasanya masih kontinu. Ini juga autoregresif dan menggunakan ruang laten gabungan sebagai input perhatian silang.
Untuk memproses sinyal video dan audio, dan untuk mengakomodasi input video / audio yang lebih panjang, mereka dibagi menjadi potongan-potongan (kira-kira disinkronkan dalam waktu), yang kemudian dipelajari untuk mensintesis representasi audiovisual melalui “Combiner”. Komponen kedua berkaitan dengan sinyal kontekstual, atau temporal yang tidak selaras, seperti informasi teks global, yang biasanya masih kontinu. Ini juga autoregresif dan menggunakan ruang laten gabungan sebagai input perhatian silang.
Komponen pembelajaran Video + Audio memiliki parameter 3B, sedangkan komponen tanpa audio adalah 2.9B. Sebagian besar semi-parameter digunakan untuk model autoregresif audio + video. Mirasol3B biasanya menangani video pada 128 frame, tetapi juga dapat menangani video yang lebih panjang (misalnya, 512 frame).
Karena desain partisi dan arsitektur model “Combiner”, menambahkan lebih banyak bingkai, atau meningkatkan ukuran dan jumlah blok hanya akan sedikit meningkatkan parameter, yang memecahkan masalah bahwa video yang lebih panjang memerlukan lebih banyak parameter dan memori yang lebih besar.
Eksperimen dan Hasil
Studi ini menguji dan mengevaluasi Mirasol3B pada tolok ukur VideoQA standar, tolok ukur VideoQA video bentuk panjang, dan tolok ukur Audio + Video.
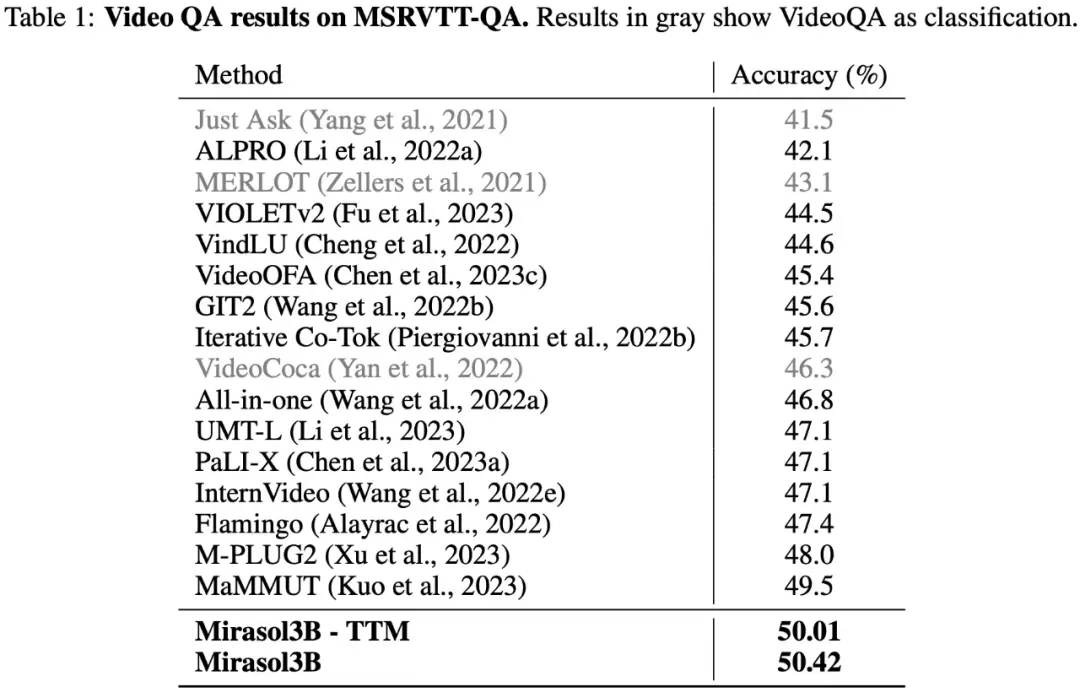
Seperti yang ditunjukkan pada Tabel 1 di bawah ini, hasil tes pada dataset VideoQA MSRVTTQA menunjukkan bahwa Mirasol3B melampaui model SOTA saat ini, serta model yang lebih besar seperti PaLI-X dan Flamingo.
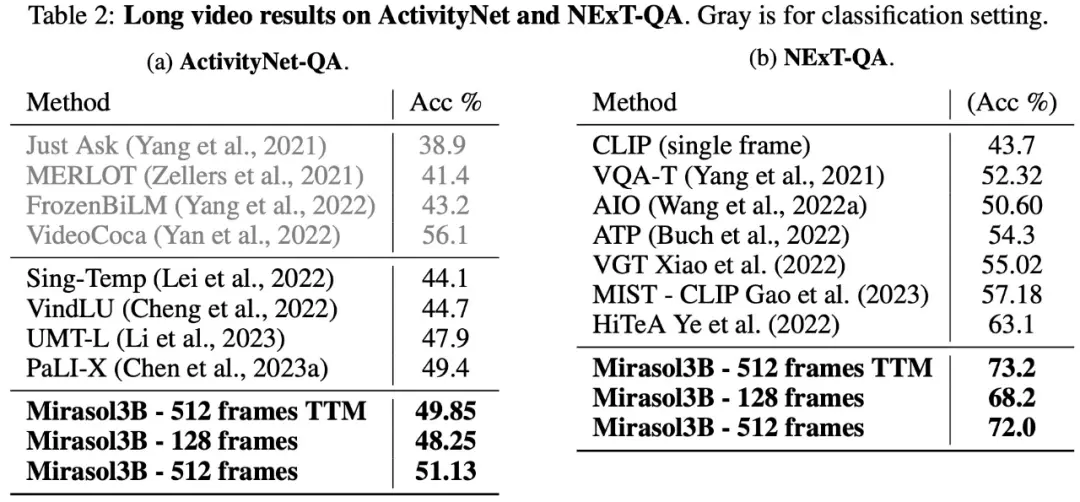
 Dalam hal video Q&A bentuk panjang, Mirasol3B diuji dan dievaluasi pada dataset ActivityNet-QA, NExTQA, dan hasilnya ditunjukkan pada Tabel 2 di bawah ini:
Dalam hal video Q&A bentuk panjang, Mirasol3B diuji dan dievaluasi pada dataset ActivityNet-QA, NExTQA, dan hasilnya ditunjukkan pada Tabel 2 di bawah ini:
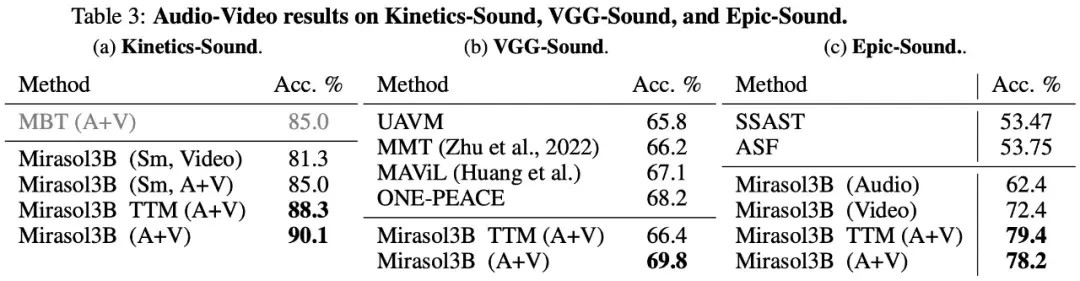
 Akhirnya, penelitian ini memilih untuk menggunakan KineticsSound, VGG-Sound, dan Epic-Sound untuk tolok ukur audio-ke-video dengan evaluasi generatif terbuka, seperti yang ditunjukkan pada Tabel 3 di bawah ini:
Akhirnya, penelitian ini memilih untuk menggunakan KineticsSound, VGG-Sound, dan Epic-Sound untuk tolok ukur audio-ke-video dengan evaluasi generatif terbuka, seperti yang ditunjukkan pada Tabel 3 di bawah ini:
 Pembaca yang tertarik dapat membaca makalah asli untuk mempelajari lebih lanjut tentang penelitian.
Pembaca yang tertarik dapat membaca makalah asli untuk mempelajari lebih lanjut tentang penelitian.
Penafian: Informasi di halaman ini dapat berasal dari pihak ketiga dan tidak mewakili pandangan atau opini Gate. Konten yang ditampilkan hanya untuk tujuan referensi dan bukan merupakan nasihat keuangan, investasi, atau hukum. Gate tidak menjamin keakuratan maupun kelengkapan informasi dan tidak bertanggung jawab atas kerugian apa pun yang timbul akibat penggunaan informasi ini. Investasi aset virtual memiliki risiko tinggi dan rentan terhadap volatilitas harga yang signifikan. Anda dapat kehilangan seluruh modal yang diinvestasikan. Harap pahami sepenuhnya risiko yang terkait dan buat keputusan secara bijak berdasarkan kondisi keuangan serta toleransi risiko Anda sendiri. Untuk detail lebih lanjut, silakan merujuk ke
Penafian.