Fuente del artículo: Heart of the Machine
supera a los modelos más grandes.
 Fuente de la imagen: Generada por Unbounded AI
Fuente de la imagen: Generada por Unbounded AI
Uno de los principales retos a los que se enfrenta el aprendizaje multimodal es la necesidad de fusionar modalidades heterogéneas como texto, audio y vídeo, y los modelos multimodales necesitan combinar señales de diferentes fuentes. Sin embargo, estas modalidades tienen características diferentes que son difíciles de combinar con un solo modelo. Por ejemplo, el vídeo y el texto tienen diferentes frecuencias de muestreo.
Recientemente, un equipo de investigación de Google DeepMind desacopló el modelo multimodal en múltiples modelos autorregresivos independientes y especializados que procesan las entradas en función de las características de cada modalidad.
En concreto, el estudio propone un modelo multimodal, Mirasol3B. Mirasol3B consta de un componente autorregresivo para el modal de sincronización temporal (audio y video), y un componente autorregresivo para la modalidad de contexto. Estas modalidades no están necesariamente alineadas en el tiempo, sino que son secuenciales.
 Dirección:
Dirección:
Mirasol3B alcanza los niveles de SOTA en puntos de referencia multimodales, superando a los modelos más grandes. Mediante el aprendizaje de representaciones más compactas, el control de la longitud de la secuencia de las representaciones de características de audio y vídeo y el modelado basado en la correspondencia temporal, Mirasol3B es capaz de cumplir eficazmente con los altos requisitos computacionales de las entradas multimodales.
Introducción práctica
Mirasol3B es un modelo multimodal de audio-video-texto en el que el modelado autorregresivo se desacopla en componentes autorregresivos para modalidades alineadas en el tiempo (por ejemplo, audio, video) y componentes autorregresivos para modalidades contextuales no alineadas en el tiempo (por ejemplo, texto). Mirasol3B utiliza ponderaciones de atención cruzada para coordinar el proceso de aprendizaje de estos componentes. Este desacoplamiento hace que la distribución de los parámetros dentro del modelo sea más razonable, también asigna suficiente capacidad a las modalidades (vídeo y audio) y hace que el modelo general sea más ligero.
Como se muestra en la Figura 1 a continuación, Mirasol3B consta principalmente de dos componentes de aprendizaje: un componente autorregresivo, diseñado para procesar entradas multimodales (casi) sincrónicas, como video + audio, y combinar las entradas de manera oportuna.
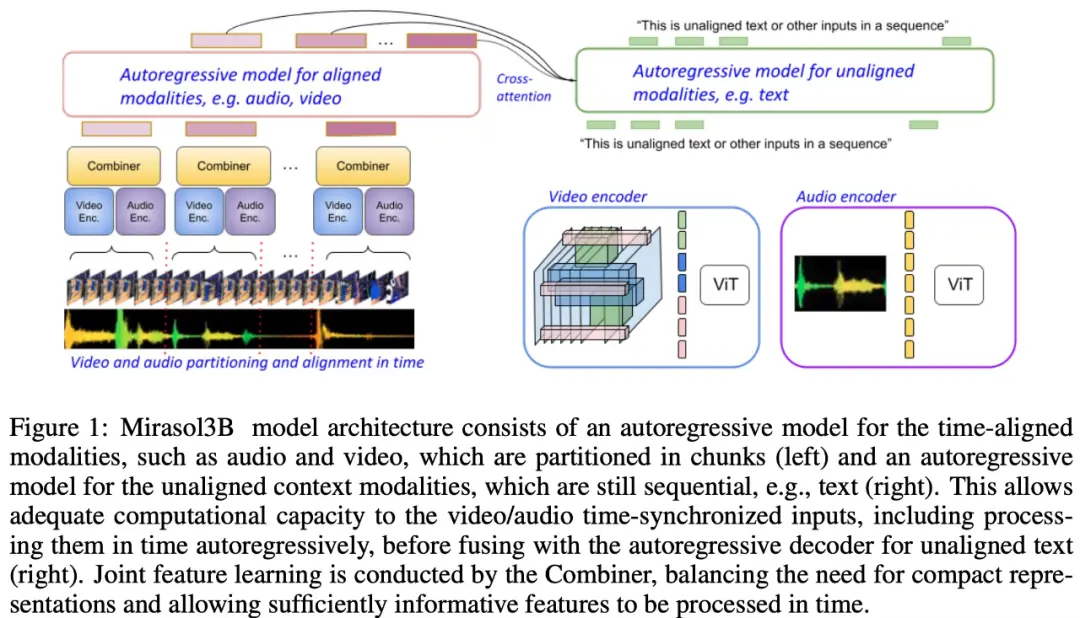
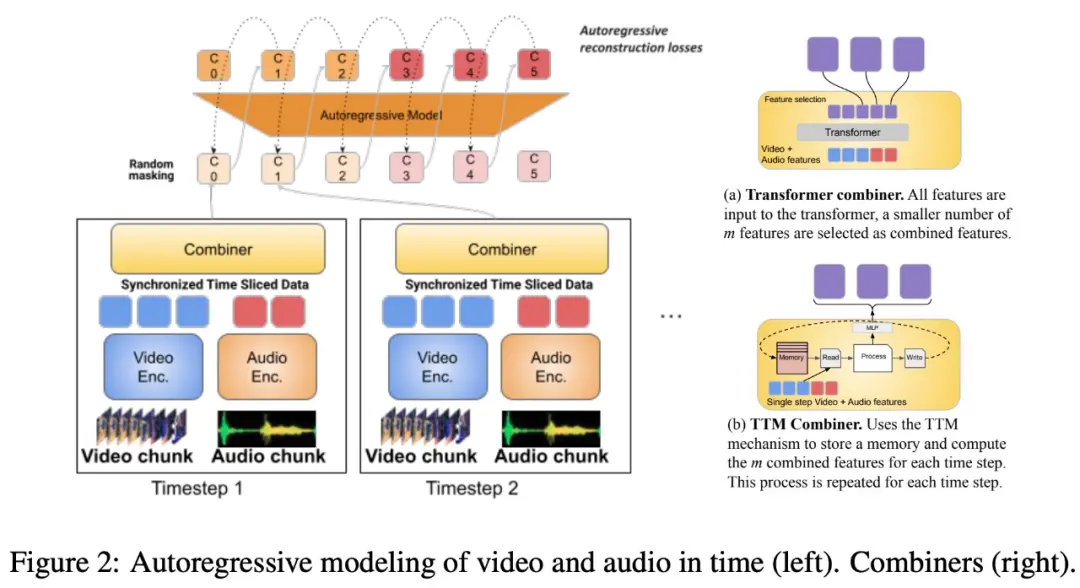 El estudio también propone segmentar la modalidad alineada en el tiempo en períodos de tiempo, en los que se aprenden las representaciones conjuntas audio-video. En concreto, este estudio propone un mecanismo modal de aprendizaje de características conjuntas denominado “Combiner”. “Combinador” fusiona características modales del mismo período de tiempo, lo que da como resultado una representación más compacta.
El estudio también propone segmentar la modalidad alineada en el tiempo en períodos de tiempo, en los que se aprenden las representaciones conjuntas audio-video. En concreto, este estudio propone un mecanismo modal de aprendizaje de características conjuntas denominado “Combiner”. “Combinador” fusiona características modales del mismo período de tiempo, lo que da como resultado una representación más compacta.
“Combiner” extrae la representación espaciotemporal primaria de la entrada modal original, captura las características dinámicas del vídeo y las combina con las características de audio sincrónico, de modo que el modelo puede recibir entradas multimodales a diferentes velocidades y funciona bien al procesar vídeos más largos.
“Combiner” satisface eficazmente las necesidades de representación modal que es a la vez eficiente e informativa. Puede cubrir completamente los eventos y actividades en el video y otras modalidades que ocurren al mismo tiempo, y se puede usar en modelos autorregresivos posteriores para aprender dependencias a largo plazo.
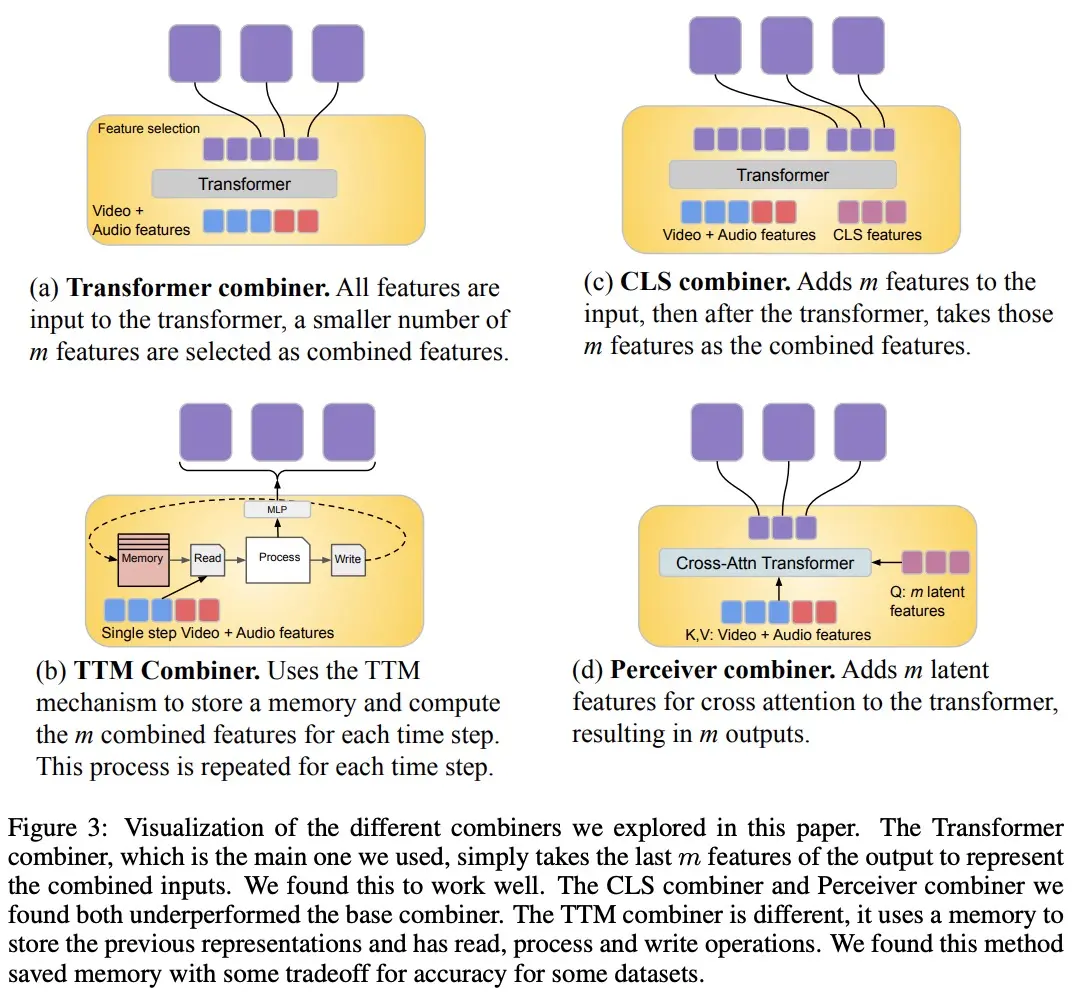 Con el fin de procesar señales de vídeo y audio, y para acomodar entradas de vídeo/audio más largas, se dividen en trozos (aproximadamente sincronizados en el tiempo), que luego se aprenden a sintetizar representaciones audiovisuales a través de “Combinador”. El segundo componente se ocupa de las señales contextuales o desalineadas temporalmente, como la información de texto global, que suele ser continua. También es autorregresivo y utiliza el espacio latente combinado como una entrada de atención cruzada.
Con el fin de procesar señales de vídeo y audio, y para acomodar entradas de vídeo/audio más largas, se dividen en trozos (aproximadamente sincronizados en el tiempo), que luego se aprenden a sintetizar representaciones audiovisuales a través de “Combinador”. El segundo componente se ocupa de las señales contextuales o desalineadas temporalmente, como la información de texto global, que suele ser continua. También es autorregresivo y utiliza el espacio latente combinado como una entrada de atención cruzada.
El componente de aprendizaje Video + Audio tiene parámetros 3B, mientras que el componente sin audio es 2.9B. La mayoría de los semiparámetros se utilizan para el modelo autorregresivo de audio + vídeo. Mirasol3B normalmente maneja videos a 128 fotogramas, pero también puede manejar videos más largos (por ejemplo, 512 fotogramas).
Debido al diseño de la partición y la arquitectura del modelo “Combinador”, agregar más fotogramas o aumentar el tamaño y el número de bloques solo aumentará ligeramente los parámetros, lo que resuelve el problema de que los videos más largos requieren más parámetros y mayor memoria.
Experimentos y resultados
El estudio probó y evaluó Mirasol3B en el punto de referencia estándar de VideoQA, el punto de referencia de VideoQA de video de formato largo y el punto de referencia de audio + video.
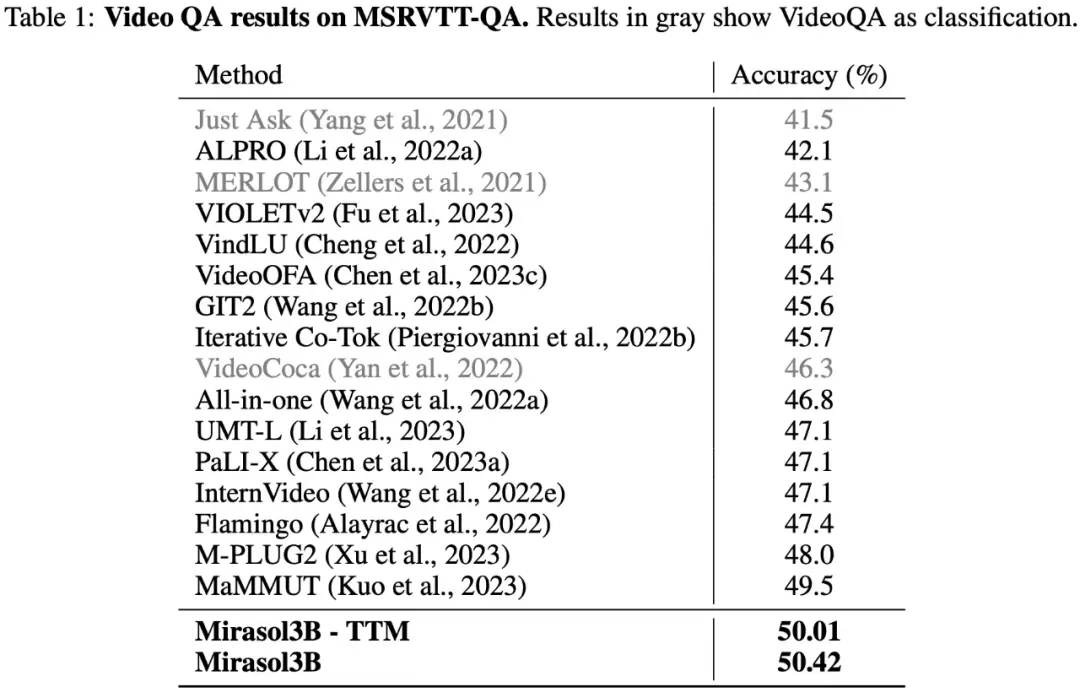
Como se muestra en la Tabla 1 a continuación, los resultados de las pruebas en el conjunto de datos de VideoQA MSRVTTQA muestran que Mirasol3B supera el modelo SOTA actual, así como modelos más grandes como PaLI-X y Flamingo.
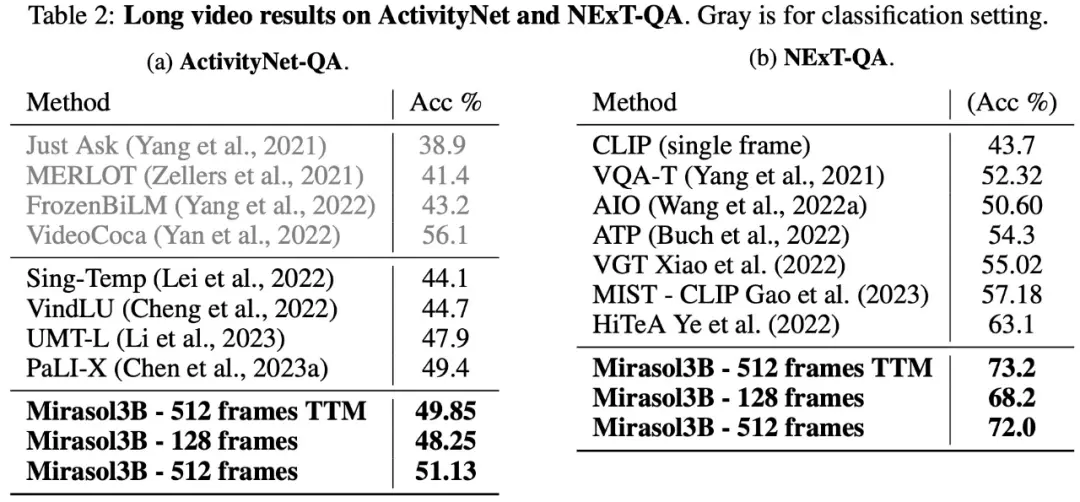
 En cuanto a las preguntas y respuestas en vídeo de larga duración, Mirasol3B se probó y evaluó en los conjuntos de datos de ActivityNet-QA, NExTQA, y los resultados se muestran en la Tabla 2 a continuación:
En cuanto a las preguntas y respuestas en vídeo de larga duración, Mirasol3B se probó y evaluó en los conjuntos de datos de ActivityNet-QA, NExTQA, y los resultados se muestran en la Tabla 2 a continuación:
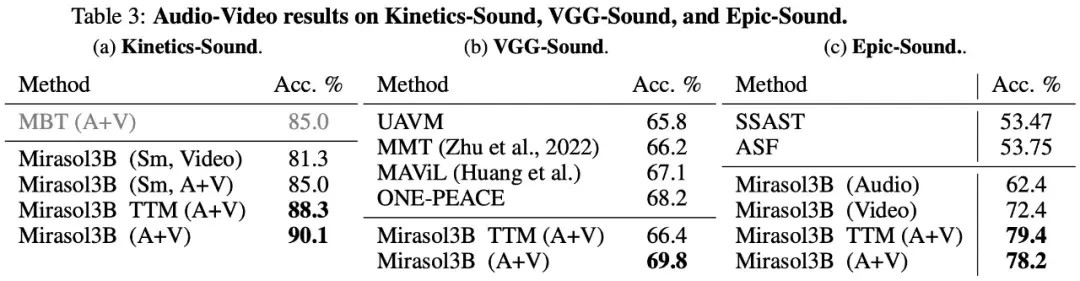
 Por último, el estudio optó por utilizar KineticsSound, VGG-Sound y Epic-Sound para los puntos de referencia de audio a vídeo con evaluaciones generativas abiertas, como se muestra en la Tabla 3 a continuación:
Por último, el estudio optó por utilizar KineticsSound, VGG-Sound y Epic-Sound para los puntos de referencia de audio a vídeo con evaluaciones generativas abiertas, como se muestra en la Tabla 3 a continuación:
 Los lectores interesados pueden leer el artículo original para obtener más información sobre la investigación.
Los lectores interesados pueden leer el artículo original para obtener más información sobre la investigación.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.

