
يزعم نظام الذاكرة المعتمد على الذكاء الاصطناعي MemPalace، الذي تشارك في تطويره ميلا جوفوفيتش، أنه حقق درجات كاملة في الاختبارات وانتشر بسرعة، لكن مجتمع المستخدمين كشف عن أن الاختبارات تتضمن شبهة بالغش وتضليل للبيانات. تُظهر التجربة العملية أن النتائج مُبالغ فيها مع وجود عدد كبير من الأخطاء؛ وقد اعترف الفريق بوجود قصور وبدأ بالفعل في العمل على الإصلاح.
ميلا جوفوفيتش تبني «قصر الذاكرة» للذكاء الاصطناعي وتثير اهتماماً واسعاً من الخارج
أمس (4/7)، كان هناك خبر كبير في أوساط مجتمع الذكاء الاصطناعي: النجمات السينمائيات في هوليوود ميلا جوفوفيتش (Milla Jovovich)، المعروفة بأفلام مثل Resident Evil وذا كلّ يوم الجريمة (The Fifth Element)، تعمل مع المطورين Ben Sigman باستخدام Claude Code لتطوير نظام ذاكرة ذكاء اصطناعي مفتوح المصدر «MemPalace».
في لحظة، انتشرت على نطاق واسع مقولة «نجمة هوليوودية عملاقة تتقاطع وتُنجز مشروعاً حاصلاً على درجات كاملة»، وحصل MemPalace حتى الآن على أكثر من 20 ألف نجمة على GitHub، لكن سرعان ما أثار ذلك شكوكاً لدى مجتمع المطورين: هل هناك فعلاً ما يستحق، أم مجرد تسويق؟
لنبدأ بالحافز وراء نشوء MemPalace: تقول الوثائق الرسمية إن الهدف هو معالجة القيود الحالية لأن محتوى محادثات المستخدمين مع الذكاء الاصطناعي، وعمليات اتخاذ القرار، ونقاشات بنية النظام عادةً ما تختفي بعد انتهاء جلسات العمل، ما يؤدي إلى انخفاض كل ما بُذل من جهد لعدة أشهر إلى الصفر.
ولحل هذه المشكلة، يستخدم MemPalace بنية مكانية لتخزين الذاكرة، حيث يتم تصنيف المعلومات بشكل واضح إلى مناطق الأجنحة التابعة للأفراد أو المشاريع، ضمن هياكل بمستويات مختلفة مثل الممرات والغرف والأدراج، مع الاحتفاظ بالنص الأصلي للمحادثة لاسترجاع المعنى لاحقاً.
يعلن فريق التطوير أن MemPalace حقق 100% في معيار تقييم الذاكرة طويلة المدى LongMemEval، كما وصل إلى دقة 96.6% دون استدعاء أي واجهة برمجة تطبيقات خارجية، ويمكن أيضاً تشغيله بالكامل على الجهاز المحلي دون الحاجة إلى الاشتراك في خدمات سحابية، ويأتي مع نظام بلهجة AAAK يُزعم أنه قادر على تحقيق ضغط بلا فقدان بمقدار 30 ضعفاً.
مصدر الصورة: GitHub النجمة السينمائية في هوليوود ميلا جوفوفيتش تبني قصر الذاكرة للذكاء الاصطناعي وتثير اهتماماً واسعاً من الخارج
شركات منافسة ومجتمع يشكون في الأمر معاً، اختبارات وأساليب ترويج فيها أخطاء
لكن إنجاز MemPalace المزعوم في LongMemEval بدرجات كاملة سرعان ما أثار أيضاً شكوكاً لدى المنافسين.
أشار PenfieldLabs، الذي يطوّر أيضاً أنظمة ذاكرة للذكاء الاصطناعي، إلى أن ادعاء MemPalace تحقيق درجات كاملة في مجموعة بيانات LoCoMo أمر مستحيل رياضياً، لأن الإجابات القياسية في مجموعة البيانات نفسها تحتوي أصلاً على 99 خطأ.
بعد تحليل PenfieldLabs، اكتشف أن إنجاز MemPalace بنسبة 100% نتج عن ضبط عدد عمليات الاسترجاع على 50 مرة، بينما لا يتجاوز أعلى عدد مراحل الحوار في مجموعة بيانات الاختبار 32 مرة؛ وهذا يعني أن النظام يتجاوز مرحلة الاسترجاع مباشرةً، ويُسلم كل البيانات إلى نموذج الذكاء الاصطناعي للقراءة.
وبخصوص إنجاز 100% في LongMemEval، وُجد أن فريق التطوير ركّز على 3 مشكلات محددة ظهرت في التطوير، وأنه كتب رموز إصلاح مخصصة لها، ما يثير شبهة إجراء غش موجّه للاختبار.

مصدر الصورة: Reddit أشار PenfieldLabs المنافسون إلى أن ادعاء MemPalace بتحقيق درجات كاملة في مجموعة بيانات LoCoMo أمر مستحيل رياضياً
اختبار عملي من مستخدمي GitHub: أن معيار الاختبار يحتوي على عناصر تضلل
علّق مستخدم GitHub hugooconnor بعد تجربة عملية، قائلاً إن MemPalace يزعم أن دقة الاسترجاع تبلغ 96.6%، لكن في الواقع لم يتم استخدام بنية «قصر الذاكرة» المزعومة من MemPalace إطلاقاً. ويقول hugooconnor إن اختباراتهم كانت مجرد استدعاء الوظيفة الافتراضية لقاعدة البيانات الأساسية ChromaDB، دون أي علاقة بمنطق التصنيف الخاص بالمناطق الجناحية أو الغرف أو الأدراج الذي يركز عليه المشروع.
بعد إجراء الاختبار، وجد hugooconnor أنه عندما يتم تفعيل منطق التصنيف الخاص بقصر الذاكرة فعلاً، تتراجع نتائج الاسترجاع. فعلى سبيل المثال، تنخفض الدقة إلى 89.4% في وضع الغرفة، وبعد تفعيل تقنية ضغط AAAK تنخفض الدقة أكثر إلى 84.2%، وكلاهما أقل من أداء قاعدة البيانات الافتراضية.
كما انتقد hugooconnor طريقة الاختبار: بيئة الاختبار في MemPalace ضاقت نطاق الاسترجاع لكل سؤال إلى نحو 50 مرحلة حوار، ما يجعل العثور على الإجابة في مجموعة عينات صغيرة جداً أمراً سهلاً للغاية.
وعند توسيع النطاق إلى أكثر من 19,000 مرحلة حوار في سيناريوهات واقعية، تنخفض دقة البحث بالكلمات المفتاحية التقليدية إلى 30% فقط، ما يُظهر أن أسلوب اختبار MemPalace الحالي يخفي المشكلة الحقيقية لصعوبة البحث.
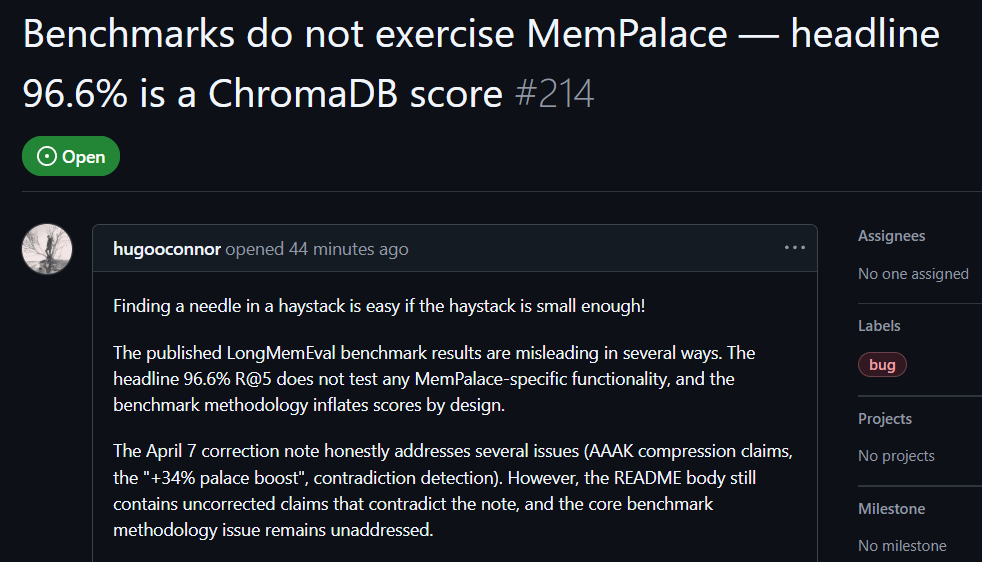
مصدر الصورة: GitHub اختبر مستخدمو GitHub عملياً، ووجد أن معيار اختبار MemPalace فيه عناصر مضللة
وفي الوقت نفسه، رغم أن فريق التطوير نشر بيان تصحيح واعترف بأن تقنية AAAK تم التحقق منها كضغط مع فقدان، وتعهد بتعديل الوثائق وتصميم النظام وفقاً للانتقادات الشديدة من المجتمع؛ فإن وثيقة الوصف الرئيسية للمشروع ما زالت تحتفظ بعدة ادعاءات مُبالغ فيها غير مُصححة، تشمل الادعاء بضغط بلا فقدان بمقدار 30 ضعفاً وتحسين الاسترجاع بنسبة 34%، كما أن مخططات المقارنة مع المنافسين الآخرين تفتقر تماماً إلى ذكر مصادر.
واجهت شفرة MemPalace الأصلية العديد من الأخطاء
مع قيام المزيد والمزيد من المطورين بتنزيل الاختبارات، ظهرت على منصة GitHub تقارير عديدة عن أخطاء في شفرة MemPalace الأصلية.
قام المستخدم cktang88 بإدراج عدة عيوب خطيرة، تشمل أن أوامر الضغط لا يمكن تشغيلها ما يؤدي إلى تعطل النظام، وأخطاء في منطق احتساب عدد الكلمات في الملخص، وعدم دقة البيانات الإحصائية في استخراج الغرف، إضافة إلى أن الخادم يقوم عند كل استدعاء بتحميل جميع بيانات التفسير إلى الذاكرة، مما يسبب مشكلة استهلاك موارد حادة.
تشمل المشكلات الأخرى المذكورة أيضاً أن النظام يقوم بكتابة أسماء أفراد عائلة المطور بشكل إجباري في ملف الإعدادات الافتراضي، وكذلك وجود حد أقصى إجباري للعرض عند الاستعلام عن الحالة لعدد 10k سجل.
وبخصوص هذه المشكلات، بدأ مجتمع المصادر المفتوحة بالفعل في عملية إصلاح نشطة. قدم المستخدم adv3nt3 عدةطلباتإصلاح، تتضمن تصحيح بيانات الإحصاء الخاصة بالاستخراج، وإزالة أسماء أفراد العائلة الافتراضية، وتأجيل زمن تهيئة المخطط المعرفي (knowledge graph). كما اعترف فريق التطوير لاحقاً بهذه الأخطاء، وهو يعمل حالياً مع التعاون المجتمعي على حل مشكلات الكود تدريجياً.
برمجة Vibe لميلا جوفوفيتش رائعة، لكن أسلوب التسويق غير رائع
بالنسبة إلى مشروع MemPalace، توصل أحد مستخدمي Hacker News darkhanakh إلى استنتاج: يمنح MemPalace إحساساً يشبه OpenClaw؛ أي أنه يتم التلاعب بالنتائج المعيارية (benchmark) بشكل مصطنع لتبدو مثالية تماماً، ثم يتم تغليفها والتسويق لها على أنها إنجاز اختراق كبير.
يرى أن التقنية الأساسية في MemPalace ربما تكون مثيرة للاهتمام بالفعل، لكن في ظل وجود عيوب في طريقة الاختبار من هذا النوع، ثم الترويج أيضاً بفكرة «أعلى نتيجة علنية على الإطلاق»، فهذا غير مناسب إلى حد بعيد، «لكن، بصراحة، أعتقد أن الأمر ممتع جداً أيضاً بما أن ميلا جوفوفيتش تلعب Vibe Coding.»
قراءة إضافية:
AI يكتب الكود وتحدث فضيحة! تطبيق «صياد نِعمة» لمنتجات القِسْمَة في السوبرماركت «تُسبب مشكلة أمن معلومات»، وGPS في المنزل يجري على المكشوف
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
