Original Title: The Great GPU Shortage – Rental Capacity – Launching our H100 1 Year Rental Price Index
Original Authors: Daniel Nishball、Jordan Nanos、Cheang Kang Wen, and others
Translation/Compilation: Peggy, BlockBeats
Editor’s Note: As AI moves from “a tool” to “workflow infrastructure,” GPU rental prices are entering an accelerated upward range, while supply continues to tighten.
From a near 40% increase in the one-year H100 price, to compute being locked in earlier for the second half of 2026, and to AI labs continuing to lock supply through long-term contracts and renewal mechanisms, the operating logic of the GPU market has clearly changed: prices are no longer determined mainly by hardware costs, but instead are shaped jointly by token consumption, model capability, and production efficiency.
Changes on the demand side are especially critical. New paradigms such as multi-agent systems, native content generation, and AI programming tools are pushing token usage into an exponential growth range. The report’s core judgment is also becoming clearer: the input-output ratio of AI tools has already been validated—returns of 5–10x—so GPU prices are unlikely to effectively constrain demand for a considerable period of time.
The resulting tension is becoming increasingly evident: in the real compute market, supply is broadly scarce and pricing power is shifting upward, while the capital markets remain anchored to expectations of “eventual oversupply and commoditization.” This mismatch between expectation and reality is reshaping the valuation logic in the AI infrastructure track.
As compute becomes a new means of production, its pricing mechanism, supply structure, and capital returns are currently undergoing a deep restructuring.
The following is the original text:
Anthropic’s Claude 4.6 Opus and Claude Code demand has surged significantly. Its annual recurring revenue (ARR) jumped from 9 billion USD at the end of last year to more than 25 billion USD in just a single quarter, nearly tripling. Meanwhile, open-source models represented by GLM and Kimi K2.5 are also driving rapid expansion of application scenarios related to open-source models. Ongoing funding rounds by companies—including Anthropic, OpenAI, and several Neolabs—are also intensifying demand for GPU resources.
This inflection point means demand is rising sharply in a short time, and a GPU purchasing rush has already emerged among ultra-large-scale cloud providers (hyperscalers) and emerging cloud service providers (Neoclouds).
This incremental demand is pushing up prices across the entire supply chain—from DRAM and NAND storage, to fiber-optic cables and data center colocation, and even infrastructure such as gas turbines—nearly all related products and services are seeing price increases.
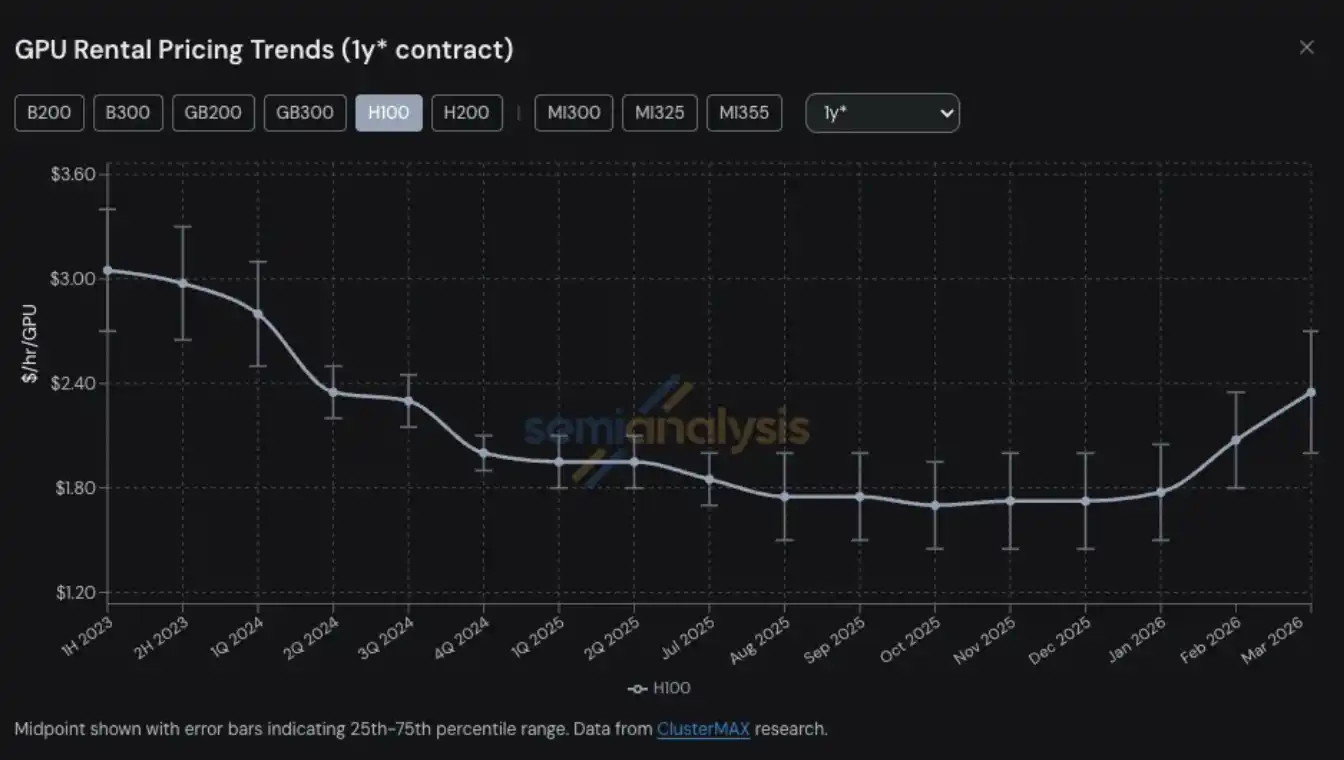
GPU rental prices have become the latest area among many compute-related products and services to experience supply tightness and a price jump. For H100 one-year GPU rental contracts, prices rose from a low point of 1.70 USD per GPU per hour in October 2025 to 2.35 USD in March 2026, an increase of nearly 40%.
On-demand GPU rental capacity for essentially all models is almost entirely sold out—users who have already locked in on-demand instances are unwilling to release compute back into the market even after price increases. In early 2026, the difficulty of finding GPU capacity is almost like trying to get tickets for the “last flight”: prices are high and there are virtually no seats. Put more aptly, it’s less like buying a concert ticket and more like “finding a channel to buy medicine.”
At SemiAnalysis, we have long been deeply tracking various trends and key issues across the Neocloud and hyperscale cloud ecosystems, including GPU rental prices. This capability comes from our ongoing research and practice in projects such as ClusterMAX, InferenceX, and AI cloud total cost of ownership (TCO).
At the same time, we also put significant effort into helping all kinds of AI labs connect with Neocloud service providers, find GPU rental resources in the market, and continuously engage in discussions with nearly all participants in the ecosystem about changing trends in GPU rental prices.
Since 2023, we have built and maintained a GPU rental price index system for clients, covering mainstream GPU models (such as H100, H200, B200, B300, GB200, GB300, MI300, MI325, MI355), across different rental tenors—from on-demand, to 1-month short rentals, to long-term contracts of up to 5 years. The index is constructed based on survey data of multiple Neocloud service providers and compute buyers, and is cross-validated through actual transaction data, as well as negotiations and deal outcomes in which we participate to match buyers and sellers.
Today, we are opening the H100 one-year GPU rental price index to the public, hoping to provide the industry with more data and insights. The index is updated monthly, and we will continue to publish the latest trend interpretations and market observations via X and LinkedIn. As for complete pricing data covering different rental-tenor structures and other mainstream GPU models, at present it is only available to institutional users subscribing to our AI cloud TCO model.
This report will focus on the latest trends in the GPU rental market, frontline market observations, and key data, explaining how we understand the overall market structure and offering an initial judgment about where rental prices may head in the future.
GPU rental market enters a “dynamic pricing” phase
Just looking at the H100 one-year rental price curve alone is not enough to fully capture how tight the market is—our real experience in obtaining compute on the ground, as well as feedback from market participants, reflects an even more severe situation.
Current demand comes from multiple highly heterogeneous use cases, with virtually no “one-size-fits-all solution.” For example, on the inference side, large-scale mixture-of-experts (MoE) models are better suited to run on the latest large-scale systems such as GB300 NVL72; on the training side, H100 still has an advantage in cost-effectiveness, so even relatively “older-generation” GPUs maintain high demand.
Customers are even competing to pay AWS p6-b200 spot instance prices of $14 per GPU per hour; some leading Neocloud service providers no longer sell single nodes; some H100 renewal prices are, surprisingly, exactly the same as when contracts were signed two or three years ago; and some H100 contracts have already been renewed all the way to 2028, with a lease term of up to 4 years. Right now, getting an H100 or H200 cluster with even just 8 nodes (64 GPUs) is not easy—among the providers we contacted, half are already completely sold out, while most providers reply that there are simply no Hopper-architecture GPUs that will expire in the near term and be released.
We even heard that some compute lessees are starting to dismantle the clusters they leased and sublease them again—almost like splitting an apartment for short-term rentals during the Monaco Grand Prix. Whether the so-called “Neocloud second landlords” will emerge next is probably no longer just a joke.
Blackwell supply is also extremely tight. We understand that, due to strong demand for open-weight models and continued explosive growth in inference demand, the deployment delivery cycle for the latest Blackwell clusters has now been extended to June through July. Moreover, most of these clusters that are about to go live have already been locked in. In fact, from the perspective of the entire market, essentially all the capacity scheduled to be added between August and September 2026 has already been reserved.
GPU rental prices: making a comeback
But why has the market ended up at this point? Just six months ago, most market observers still doubted the “terminal value” of GPUs and generally believed that GPU rental prices would inevitably keep declining over time. At the time, if a Neocloud or hyperscale cloud provider used a 6-year depreciation cycle in its financial model to handle GPU compute assets, it would even have drawn criticism from financial analysts. Before discussing future trends, let’s quickly review how things evolved to this point.
Before the second half of 2025, the mainstream expectation across the ecosystem was that with Blackwell’s massive deployments and its significantly lower unit compute cost, Hopper (i.e., H100 and H200) rental prices would clearly fall. But the reality was the opposite. By the second half of 2025, H100 demand had not weakened—in many scenarios it strengthened further. The rapid adoption of open-weight models and the sustained acceleration of inference demand were the earliest signals of this wave of seemingly endless compute demand.
By January 2026, the compute market hit its next inflection point: after several quarters of rapid increases, DRAM and NAND storage prices entered a stage of almost “parabolic” acceleration. According to our storage models, in Q1 2026, the year-over-year contract price increases for LPDDR5 and DDR5 were approaching roughly 4x and 5x, respectively.
To address the margin risk caused by the sharp rise in component costs, OEMs started raising the prices of AI servers—and the magnitude of these price increases was clearly greater than the increases in underlying component costs themselves. This made cluster capital expenditure decisions even more complex: higher server procurement costs compressed expected project returns, forcing some operators to slow down deployment schedules, or even abandon new projects altogether. As a result, some incremental supply that might have been deployed was delayed or shelved, further exacerbating tight conditions in the rental market.
Amid this procurement chaos triggered by “AI server pricing going out of control,” GPU rental demand grew significantly faster—most of the remaining compute in the market was fully consumed in January and February. By March, whether for H100, H200, or B200, it was almost impossible to find available capacity across any rental term. By late January, the one-year rental price had already exceeded 2 USD per GPU per hour, and in the second half of February it rose another 15%–20% compared with late January. It is expected to rise another 15%–20% quarter-over-quarter by late March.
One of the key drivers of demand at the beginning of this year comes from native media generation. Applications like Seedance and Nano Banana are driving users to generate and iterate images and videos at scale, significantly increasing token throughput. But even more crucial—and more visible—comes from the rise of multi-agent workloads: these systems execute multi-step processes, iterate continuously in high-concurrency environments, and drive token consumption and compute demand to grow in an “exponential” manner.
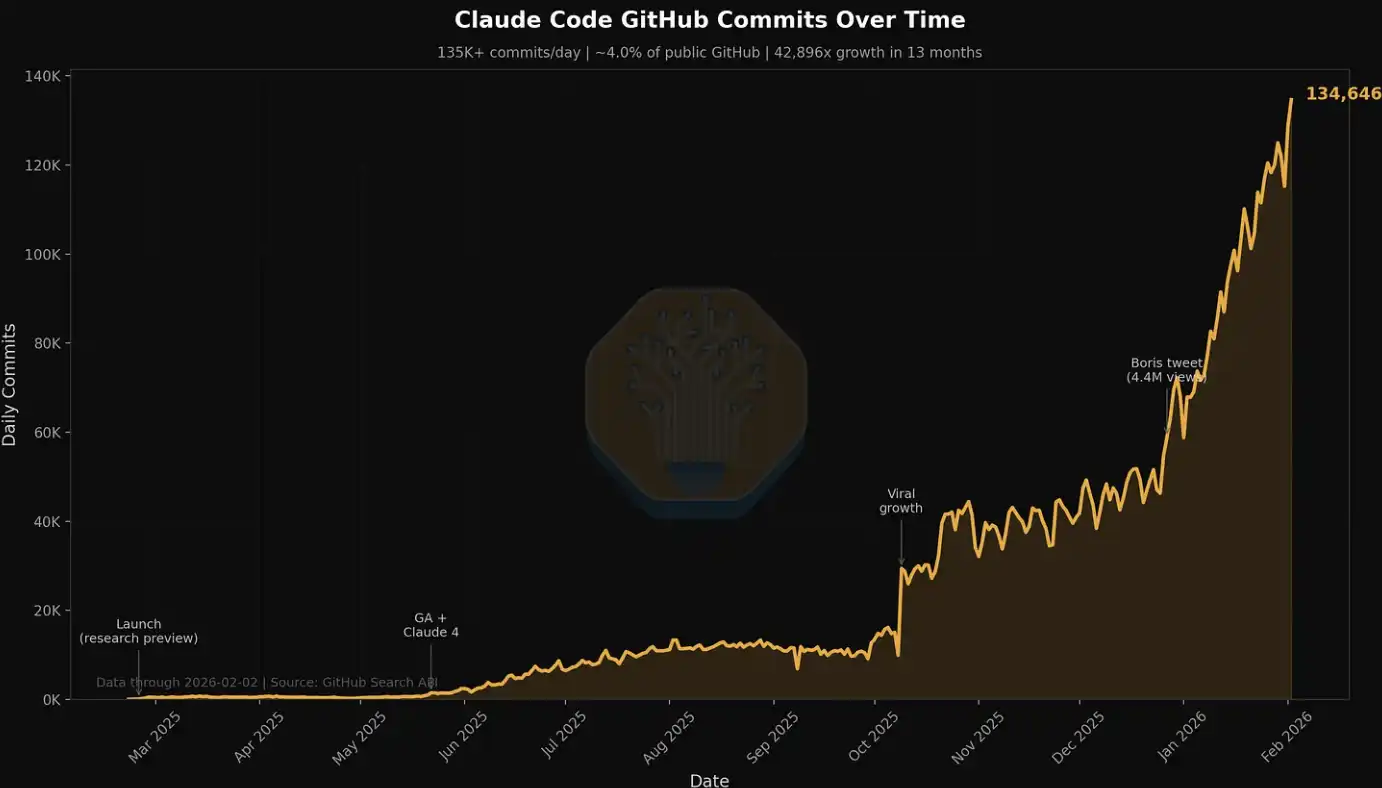
This trend is especially evident in related data for Claude Code, which we have mentioned in multiple previous articles. For example, at SemiAnalysis, in just the past 7 days, the company consumed several billion tokens internally, with an average cost of about 5 USD per million tokens. But the time saved, workflow expansion, and capability improvements far exceed the cost itself. Today, SemiAnalysis has embedded an entire suite of AI tools into multiple workflows. It is no longer limited to simple search and summarization; it extends to dashboards, automated scraping, large-scale data processing, and even agent-based financial modeling.
We also track this explosive demand growth using metrics such as Claude Commits Daily. Based on current trends, we expect that by the end of 2026, Claude Code will account for more than 20% of all code submissions. In other words, in the time you might not have noticed, AI has already started “consuming” the entire software development process. For institutional customers that want to obtain this dataset, contact our API team. A small preview: this submission volume is already clearly higher than where we started when we first published.
Within our circle, almost everyone is a heavy user of Claude Code. But we also understand that this circle is deeply immersed in AI and semiconductors—essentially just “a small group at the very front line.”
For many Fortune 500 companies—and the broader public—Claude Code and the “agent world” are still somewhat novel fringe topics, occasionally appearing in Facebook feeds or NPR podcasts. They have barely realized that a wave of productivity driven by agents, along with structural shocks, is approaching.

As more participants from the real economy gradually come to understand the astonishing investment returns from using AI tools and join this “compute wave,” token consumption will continue to rise in step-like increments. The debate about AI input-output ratios has, in fact, already been settled: the value created by using AI tools often reaches a magnitude of more than one order relative to their costs. Against this backdrop, the continuous rightward shift of the token demand curve is forming a strong force that (at the current stage) is relatively inelastic, pushing GPU rental prices upward continuously.
Put simply: if the return on investment from using AI tools can reach 5–10x, then GPU rental prices still have substantial upside, and only then could they truly suppress demand. We also do not rule out that further increases in rental prices will continue to transmit upward, pushing up the costs of servers and core components.
SemiAnalysis releases the H100 one-year rental price index
Today, we are making SemiAnalysis’s H100 one-year rental contract price index available for free to the public, aiming to improve industry awareness and transparency around GPU rental price trends.
The index is built based on monthly survey data from more than 100 market participants, including Neocloud service providers, compute buyers, and sellers, to determine the representative range of GPU rental prices (the 25th to 75th percentiles). At the same time, we cross-validate with actual transaction data, and by matching buyers and sellers within our own network, we directly participate in some transactions to further calibrate the price levels.
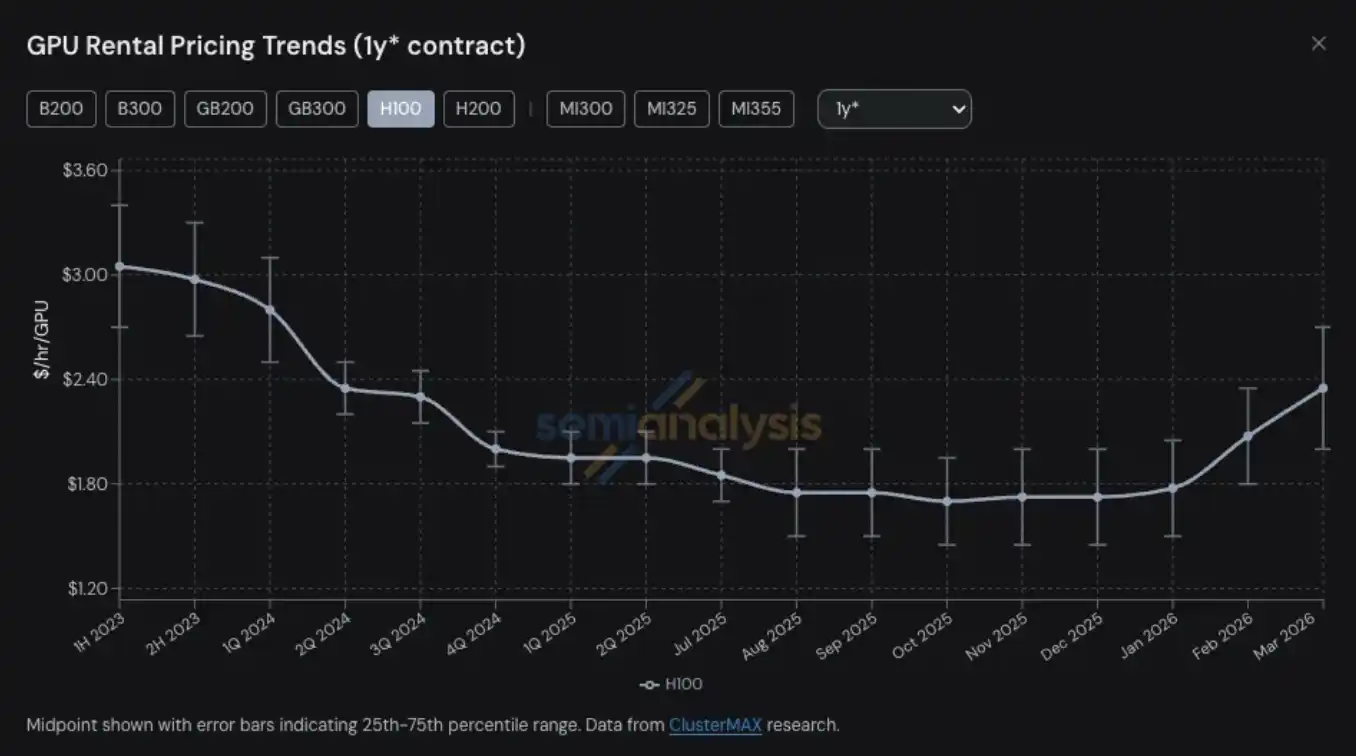
Since 2023, we have continued to track GPU contract prices for H100, H200, B200, B300, GB200, and GB300 across rental tenors ranging from 3 months to 5 years, and we also include relevant data for the AMD series (MI300, MI325, MI355).
Compared with existing GPU indices in the market, SemiAnalysis’s H100 one-year contract price index has several key differences:
First, many GPU rental indices are based on spot/on-demand quotes or published listing prices, but in reality, the vast majority of GPU rental transactions are completed through long-term contracts, typically with terms of more than 6 months. These prices are often formed through bilateral negotiations and do not appear in any public database. Most large Neocloud service providers prefer signing leases of at least 1 year, with 2–3 years being ideal; if a 5-year large-volume package sales agreement can be reached, that would be even better. SemiAnalysis’s H100 one-year rental index focuses on this “contract market”—the portion of the market where actual transaction volumes are most concentrated. By clearly pointing to a specific tenor, the index is also easier for users to understand the market range it covers, and to compare against their own observations.
Second, disclosed prices do not represent actual transaction prices. Prices published by hyperscalers and Neocloud providers are more like references for trend direction rather than actual trading levels. These prices often lag behind changes in the contract market; typically, they are adjusted only after compute demand has already shifted. Especially in the on-demand market, prices are often set at a relatively fixed level, while actual supply-demand changes are reflected through utilization rates or resource occupancy—typically adjusted only when necessary. The article later elaborates further on this market mechanism.
Third, although there are many indices on the market that can handle large-scale quote, price, and transaction data and have advantages in trend analysis, our approach places greater emphasis on direct interaction with market participants. Behind every quote and every transaction there is a specific context and decision logic. We want, while presenting quantitative data, to also supplement these qualitative insights and frontline observations, thereby recreating the true structure of the GPU rental market more comprehensively.
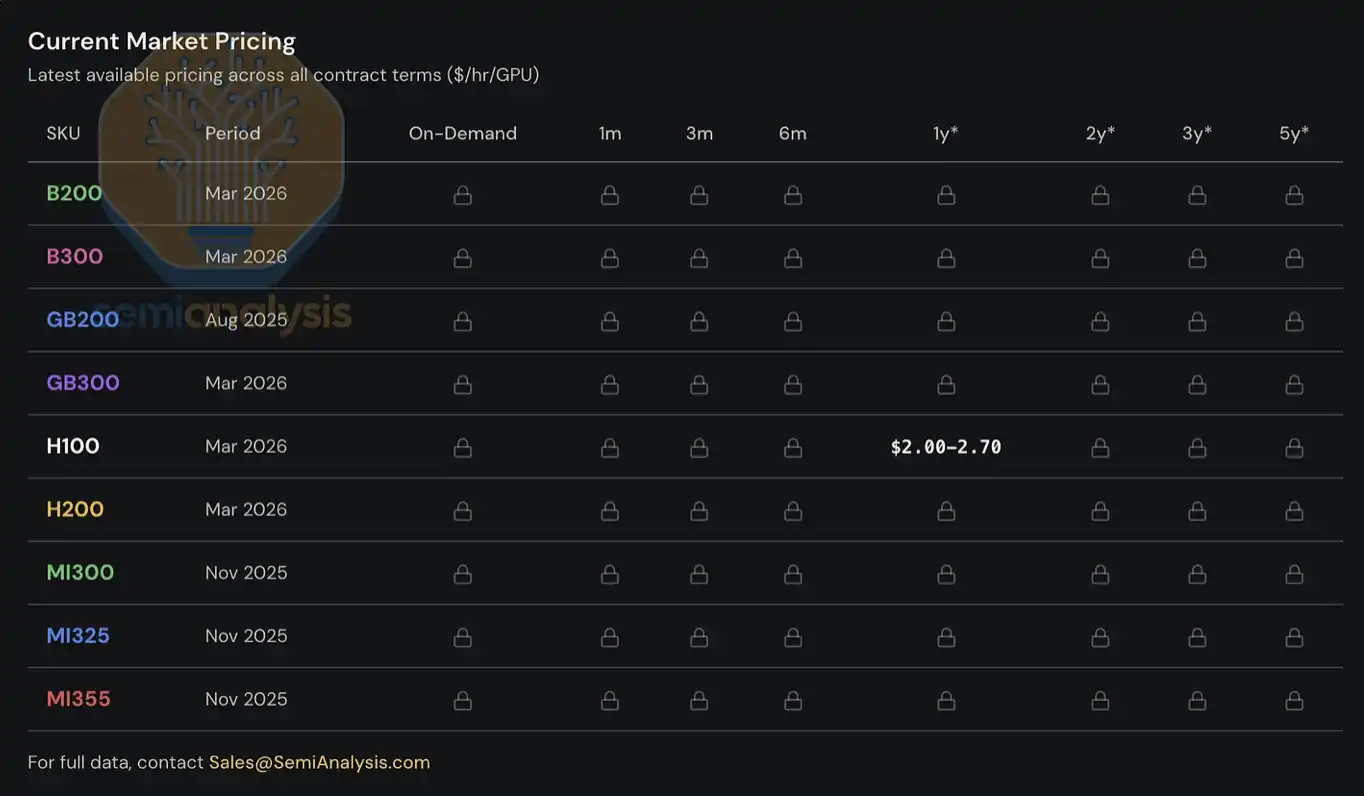
For institutional subscribers, we also provide complete tenor-structure data covering almost all mainstream GPU rental markets.
Along with the release of the H100 one-year contract price index, we are also launching the SemiAnalysis Tokenomics Dashboard for institutional Tokenomics model subscribers, to track and understand the frontier landscape of AI models. This dashboard supports users to customize comparisons across multiple dimensions such as code, inference, math, and agent evaluations—compare API pricing among different models and service providers, and review key data disclosed by major AI labs, including token usage, revenue, valuation, and customer scale, among other metrics.
Current structure of the GPU rental market
Before the second half of 2025, the pricing environment in the GPU rental market was relatively more competitive. At that time, operators had more abundant GPU inventory, while end demand was only just starting to accelerate. As a result, competition among Neocloud service providers was intense: they commonly sought to win customers with more attractive pricing. Their core goal was to improve utilization and fully “squeeze” the value of existing compute assets as much as possible before the next round of GPU iteration cycles arrived.
But since then, the market landscape has flipped 180 degrees. Today, Neoclouds and hyperscalers have fully seized the initiative—they can demand higher upfront payments, better pricing, and longer contract terms, and even choose the start and end timing of contracts themselves to match their inventory and capacity planning. At the same time, time is also on the supply side: they can advance deployments according to their own schedule, and gradually filter the most high-quality customer mix under an environment of continuously rising prices.
Structurally, the GPU rental market can be roughly divided into three major segments, with each segment corresponding to different types of customer demand:
Short-term rentals: on-demand, spot, and contracts of 3 months or less
Mid-term contracts: contracts of 3 months to more than 3 years
Long-term offtake: 4–5 year contracts, with 5 years being the most common
Short-term rentals: on-demand, spot, and contracts of 3 months or less
Short-term rentals are at the very front of the overall rental-tenor structure, and in many cases correspond to “leftover capacity.” However, some service providers (such as Runpod and Lambda) focus on offering sizable, flexible on-demand or spot compute.
It’s important to note that the pricing mechanism in the on-demand market differs significantly from other contract markets. Typically, service providers set a relatively fixed price level for on-demand resources and adjust it only in very few cases. In other words, prices in the short-term market are not driven directly by real-time supply and demand; rather, they reflect market tightness mainly through changes in resource utilization.
Service providers usually adjust prices once based on resource utilization. When utilization is low, they reduce prices to stimulate demand; when utilization approaches full capacity, they raise prices, because even at higher price levels, demand can still remain high.
This also explains why, from a time-series perspective, the on-demand prices published by Neoclouds often stay unchanged for a relatively long period and then suddenly jump up or down in a “stepwise” manner. For the on-demand market, what truly reflects demand changes at high frequency is not price, but resource utilization.
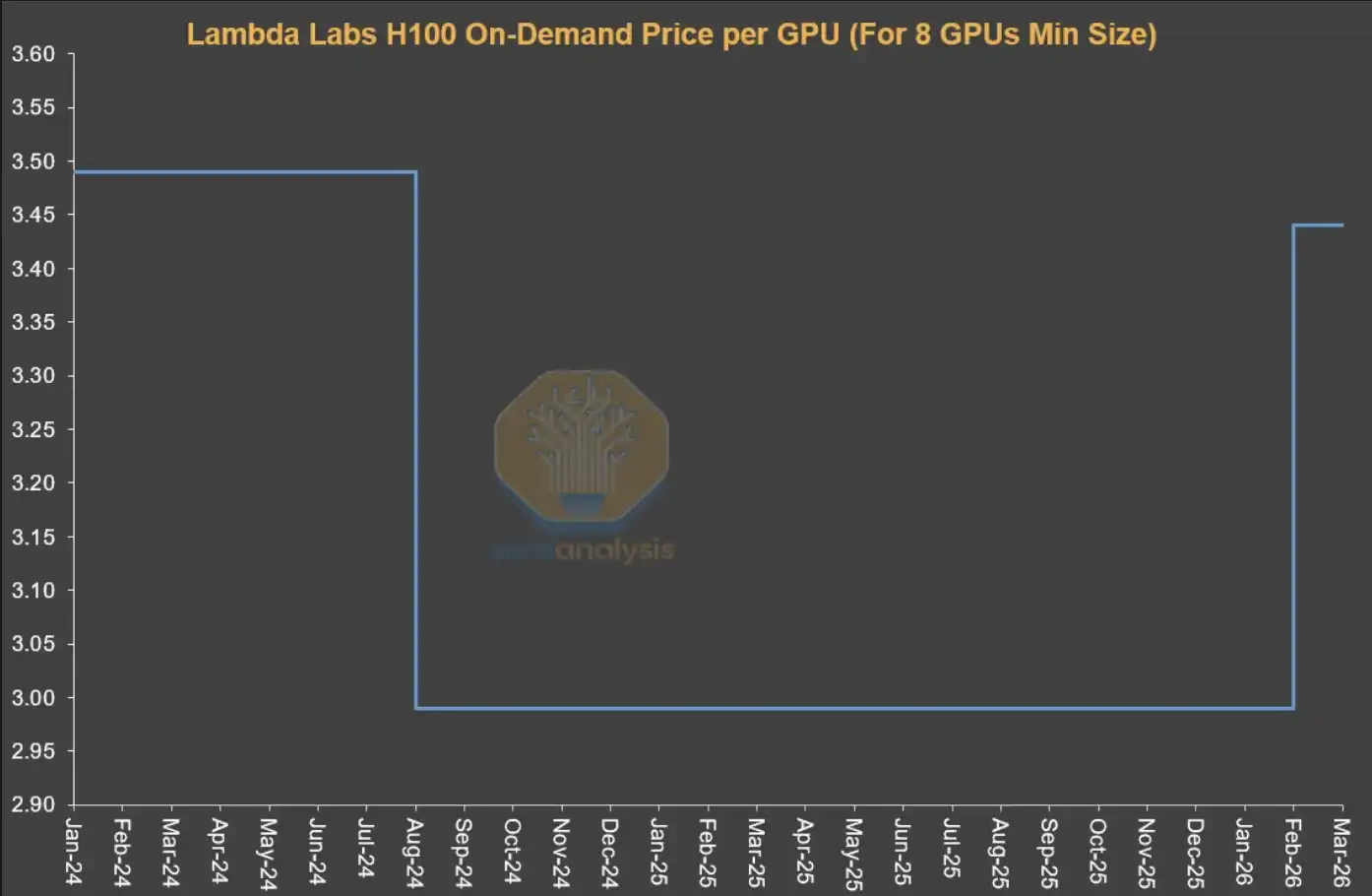
Source: Lambda Labs, SemiAnalysis
Mid-Term Contracts
Economically speaking, what’s more important is the “contract market,” because the value of the majority of GPU rental transactions occurs in this segment. Within it, one-year contracts are particularly important: they reflect not only marginal demand from non-AI-lab customers, but also overflow demand from large customers, making them the most sensitive indicator for judging how tight the market is.
AI natives and mid-sized to small AI labs are mainly active in the 1–3 year range. However, a clear recent trend is that these institutions are also beginning to try to lock in compute resources with longer contracts—many have extended to 4 years or more, and some are even willing to pay more than 20% in upfront payments, which is uncommon among contracts longer than 4 years in the past.
Long-Term Offtakes
In the longer 4–5 year market, the dominant players are large AI labs, which lock in large-scale compute resources early. These transactions typically correspond to clusters at the 50MW, 100MW, or even larger scale—roughly equivalent to about 24k to 48k GB300 NVL72 GPUs. Overall, these long-term offtake agreements already occupy a substantial share of the Neocloud GPU rental market.
AI labs favor these contracts because they allow them to lock in large-scale compute in one go to meet rapidly growing end demand. At the same time, these institutions typically deeply participate in cluster design, including key areas such as storage, networking, and CPU configuration. These transactions are often delivered in the form of bare metal, because AI labs have enough engineering capability to customize the technology stack at a lower level, achieving the best TCO (total cost of ownership) and performance.
For Neocloud service providers, these deals are also attractive. On one hand, they can concentrate sales resources on a small number of large orders rather than dealing with a large number of small customers while generating the same revenue. On the other hand, long-term contracts also make it easier for them to raise debt financing on better terms—by matching the financing tenor with the contract tenor, they can effectively reduce tenor mismatch and price volatility risk, and in most cases lock in project internal rates of return (IRR) of “teens of percentage points.”
In addition, hyperscalers often play a “backstop” role in these arrangements: as direct purchasers, they buy compute from Neocloud and then resell it to AI labs. This structure is win-win for all parties. Neocloud can obtain better financing terms based on the AAA-rated offtaker; while hyperscalers do not need to expand their own balance sheet assets—by providing credit backing, they receive part of the project returns.
The table below lists some of the large offtake agreements we are tracking. We will conduct in-depth analysis on these deals to infer their implied GPU hourly price ($/hr/GPU), as well as key profitability metrics such as project IRR and EBIT profit margins.
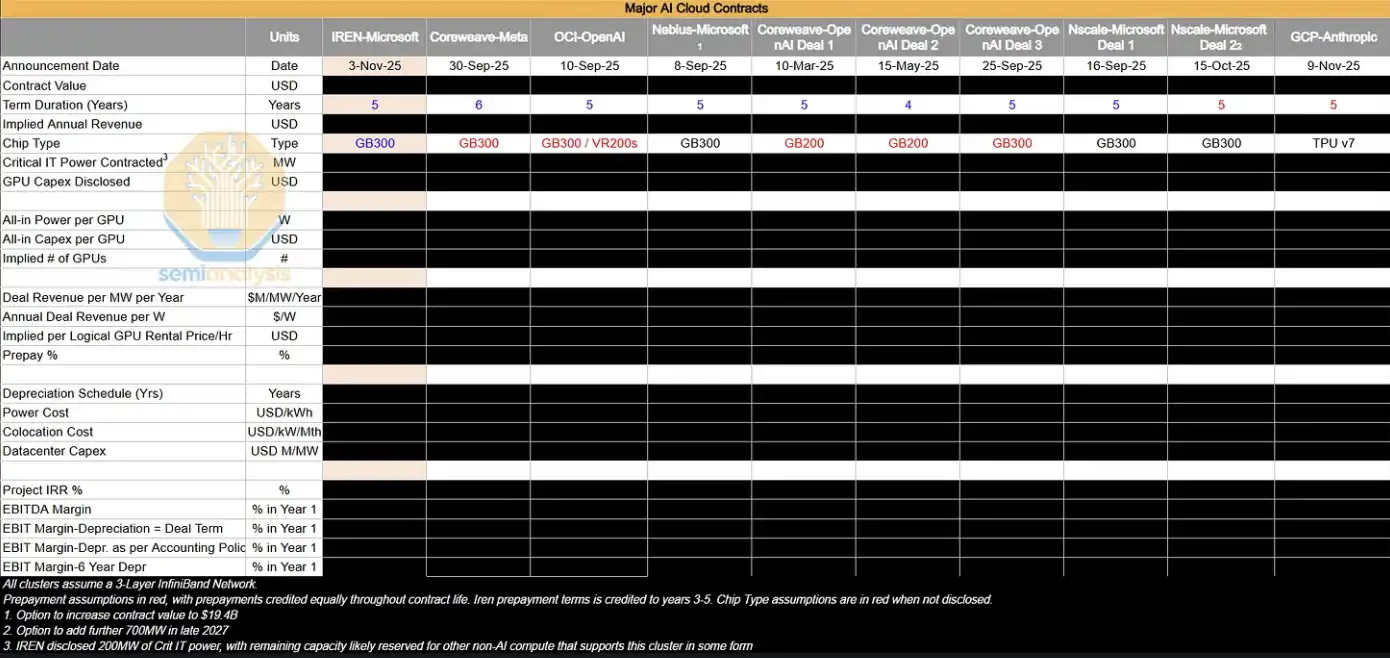
In the current market environment, most of the large AI clusters that are expanding are, in practice, “consumed internally” by AI labs. However, these institutions still enter the contract market within 4 years to add supplemental compute, and by renewing existing H100 and H200 clusters, they indirectly prevent supply from flowing back into that market. As GB200 and GB300 hyperscale clusters gradually come online, how supply-demand dynamics in the 1–3 year contract market evolve will become an important variable worth closely watching next.
Where The Puck is Going
What draws the most attention right now is the stark divergence between underlying reality and market sentiment. Even though signals like tight supply and rising prices—signals that should benefit Neocloud (margin expansion, longer asset utilization lifespan)—are very clear, the public market is becoming increasingly pessimistic about companies such as CoreWeave, Nebius, and Iris Energy, and their stock prices are still at low levels relative to the past 6–12 months range.
The market is still dominated by the narrative of “eventual supply oversupply and compute commoditization,” and the changes described above have not truly alleviated investors’ concerns about GPUs’ long-term value. But based on frontline conditions, ongoing supply tightness and strengthened pricing power mean that essentially all compute is in a state of being “absorbed” by demand—despite performance differences, in this extreme scarcity environment, it remains a buyers’ market where demand exceeds supply.
Three key observation points for the future
To judge whether GPU rental prices will continue to stay high, you can focus on three variables:
-
Expansion pace of GB300 clusters (2026)
The key is the relative speed between added compute and token demand—whether supply eases tightness or demand continues to outpace supply. This will directly influence whether AI labs keep participating in the within-4-years market and the price trajectory in that segment.
-
Whether the semiconductor shortage further worsens
Including TSMC N3 process capacity, HBM, DRAM, NAND, and other critical links—any fluctuations at the manufacturing execution level could further tighten supply.
-
Growth speed of AI lab revenue (ARR) and token consumption
The expansion of AI commercialization and usage scale will determine the strength of end demand, which is also the core variable driving compute demand.
Prices move only upward, and returns rise accordingly
Overall, a relatively clear conclusion is that the probability of GPU rental prices continuing to rise is higher than the probability of them falling.
This process has obvious self-reinforcing characteristics: when Neocloud observes tight supply and rising prices, it locks in more hardware in advance, further compressing market supply and pushing prices higher. This is similar to the GPU shortage cycle of 2023–2024—at the time, tight supply drove OEMs to achieve significant margin expansion and also caused server prices to rise sharply (although with higher market maturity this round, the process may not fully repeat).
Meanwhile, the renewed upswing in GPU rental prices is also improving Neocloud’s capital returns (ROIC):
On one hand, it increases the profit margins of deployed assets
On the other hand, it extends the economic utilization cycle of GPUs, allowing capital to generate cash flow for a longer period
Who are the biggest beneficiaries right now?
The most direct beneficiaries currently are compute providers with the following characteristics:
· Primarily short-cycle contracts (can quickly reprice)
· A large inventory of H100 equipment
· New capacity coming online in the near term
Neoclouds with a short-rental structure can release old contracts faster and sign new ones at higher prices, enabling rapid margin expansion. Meanwhile, hyperscalers and Neoclouds that have already locked in next-generation compute (multi-year contracts) will also benefit in the next cycle.
So the question is: will this time really be “different”?
[Original Link]
Click to learn about hiring at Lydong BlockBeats
Welcome to join Lydong BlockBeats’s official community:
Telegram subscription group: https://t.me/theblockbeats
Telegram discussion group: https://t.me/BlockBeats_App
Twitter official account: https://twitter.com/BlockBeatsAsia
