
ИИ-система для памяти MemPalace, разработанная при участии Миллы Йовович, заявляет о результатах «на отлично» и быстро стала популярной, однако сообщество разоблачило её: тесты якобы связаны с читингом и вводят в заблуждение данными. Практическая проверка показала, что эффект преувеличен и есть множество ошибок; команда признала недочёты и уже работает над исправлениями.
Милла Йовович создала ИИ-дворец памяти для AI, привлекая внимание извне
Вчера (4/7) в кругу AI была крупная новость: голливудская звезда Милла Йовович (Milla Jovovich), известная по «Обители зла» и «Пятому элементу», вместе с разработчиком Беном Сигманом (Ben Sigman), используя Claude Code, создала «MemPalace» — открытую AI-систему памяти.
На некоторое время распространилось утверждение, что «голливудская суперзвезда из другой сферы сделала проект на максимум», и до сих пор MemPalace на GitHub набрала более 20k звезд, но очень быстро разработческое сообщество начало сомневаться: есть ли там действительно что-то стоящее или это просто хайп?
Для начала разберём мотивацию появления MemPalace: в официальной документации сказано, что она создана, чтобы решить проблему, когда в текущих AI-системах контент диалога пользователя с AI, процессы принятия решений и обсуждение архитектуры обычно исчезают после завершения рабочей сессии, из-за чего несколько месяцев труда падают до нуля.
Чтобы решить эту проблему, MemPalace использует пространственную архитектуру для хранения памяти: информацию чётко группируют по «крыльям» для представленных сотрудников или проектов, а также по разным уровням структуры, таким как коридоры, комнаты и ящики; при этом сохраняют исходный текст диалога для последующего семантического поиска.
Разработчики заявляют, что MemPalace в эталоне долгосрочной памяти LongMemEval получила 100% идеального результата, а также достигла 96,6% точности без вызова любых внешних API, причём полностью может работать локально, не требуя подписки на облачные сервисы, и оснащена заявленной AAAK-диалектной системой, которая якобы позволяет добиться 30-кратного без потерь сжатия.
Источник изображения: GitHub Голливудская звезда Милла Йовович создала AI-дворец памяти, привлекая внимание извне
Коллеги и сообщество одновременно подвергли сомнению, тестирование и продвижение имеют изъяны
Однако заявленная MemPalace «идеальная» оценка в LongMemEval очень быстро вызвала сомнения у коллег.
PenfieldLabs, также создающая AI-системы памяти, указала, что MemPalace якобы получила максимум на наборе данных LoCoMo — и это математически невозможно, потому что стандартные ответы в самом этом наборе данных уже включают 99 ошибок.
После анализа PenfieldLabs выяснила: 100% результата MemPalace получены из-за того, что число извлечений (retrieval) установили равным 50, но наивысший уровень количества диалоговых этапов в тестовом датасете — всего 32. Это означает, что система напрямую обходит стадию извлечения и передаёт все данные AI-модели для чтения.
В отношении 100% результата в LongMemEval обнаружилось, что разработчики ориентировались на 3 конкретные проблемные вопросы, в которых чаще всего ошибались при фокусе на разработку, и написали специальный код исправления — что создаёт подозрение в читинге по тестовому набору.

Источник изображения: Reddit Коллега PenfieldLabs указывает, что MemPalace якобы получила максимум на наборе данных LoCoMo — и это математически невозможно
Практическая проверка на GitHub: есть элементы, вводящие в заблуждение
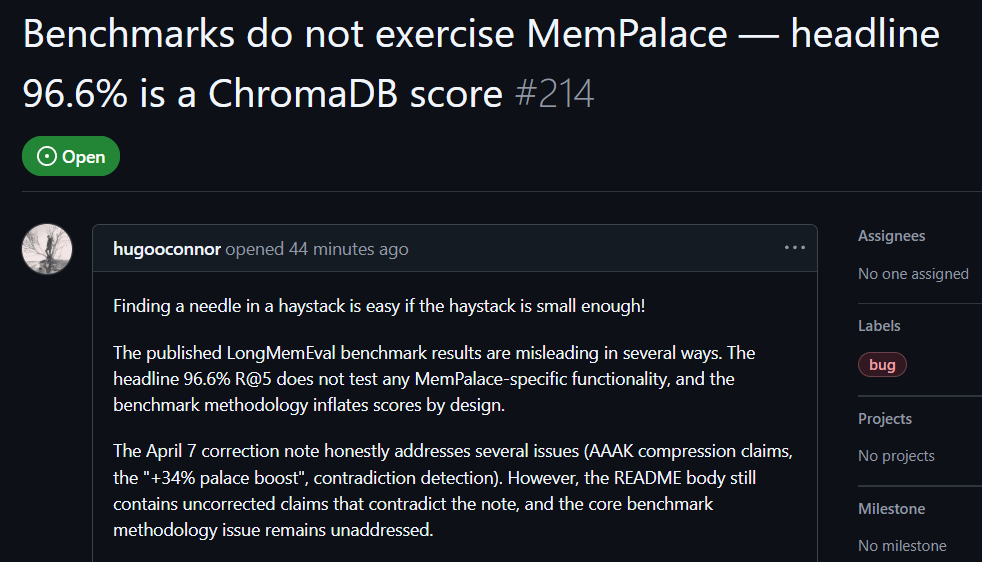
Пользователь GitHub hugooconnor после практической проверки прокомментировал: MemPalace заявляет о точности извлечения до 96,6%, но на деле вообще не использовала архитектуру «дворца памяти», которую продвигает. hugooconnor утверждает, что их тест лишь вызывал настройки по умолчанию базового хранилища данных ChromaDB и совершенно не включал логики категоризации, о которой говорится в проекте, включая «крылья», комнаты или ящики.
После теста hugooconnor обнаружил, что когда в системе действительно включают эксклюзивную логику категоризации «дворца памяти», результат извлечения, напротив, ухудшается. Например, в режиме «комната» точность падает до 89,4%, а после включения AAAK-технологии сжатия точность ещё ниже — до 84,2%; оба значения ниже, чем у работы по умолчанию базовой БД.
hugooconnor также раскритиковал методику тестирования: среда MemPalace намеренно сужает область извлечения для каждого вопроса примерно до 50 диалоговых этапов; искать ответы в слишком маленькой тестовой базе слишком просто.
Если расширить охват до более чем 19 000 диалоговых этапов в реальных сценариях, точность традиционного поиска по ключевым словам падает до 30%, что показывает: текущий формат тестирования MemPalace маскирует реальную сложность поиска.
Источник изображения: GitHub Практическая проверка пользователя GitHub: в базовом тестировании MemPalace есть элементы, вводящие в заблуждение
При этом, хотя команда разработчиков уже опубликовала исправляющее заявление и признала, что AAAK-технология действительно верифицирована как сжатие с потерями, и пообещала скорректировать документацию и дизайн системы в соответствии со строгой критикой со стороны сообщества, основное поясняющее описание проекта по-прежнему сохраняет множество несокорректированных преувеличений: включая заявления о 30-кратном «без потерь» сжатии и 34% прироста извлечения, а также сравнительные графики с другими конкурентами вообще без указания источников.
Исходный код MemPalace столкнулся с несколькими Bug
По мере того как всё больше разработчиков скачивают тесты, на платформе GitHub появляется множество сообщений о Bug в исходном коде MemPalace.
Пользователь cktang88 перечислил несколько серьёзных недостатков: включая то, что сжатые команды не работают и приводят к падению системы, ошибку в логике расчёта количества слов в резюме, неточность статистики при «копании комнат», а также то, что сервер при каждом вызове загружает в память все интерпретационные данные, из-за чего возникают серьёзные проблемы с потреблением ресурсов.
Среди других указанных проблем также отмечается, что система жёстко записывает имена членов семьи разработчика в файл настроек по умолчанию, а при проверке статуса существует принудительный верхний предел отображения для 10k записей данных.
В ответ на эти проблемы открытое сообщество уже начало активно исправлять. Пользователь adv3nt3 подал несколькозапросовна исправления, включая корректировку статистики «копания», удаление заданного по умолчанию имени члена семьи и отложенный старт инициализации знаний-графа.** Команда разработчиков позже также признала эти ошибки и постепенно решает проблемы с кодом в рамках совместной работы с сообществом.
Vibe Coding с Миллой Йовович — классно, а вот маркетинг — не очень
По поводу проекта MemPalace пользователь Hacker News darkhanakh сделал вывод: MemPalace создаёт ощущение, как будто это OpenClaw, то есть искусственно манипулируют результатами бенчмарка, чтобы они выглядели безупречно, а затем упаковывают всё это как некий большой прорыв и продают как маркетинговую историю.
Он считает, что базовая технология MemPalace, возможно, действительно интересна, но при таких изъямах в методике тестирования ещё и продвигать это под видом «самой высокой публичной оценки в истории» — явно неудачно, «но, знаете, Милла Йовович играет в Vibe Coding — думаю, это всё равно довольно круто».
Дальнейшее чтение:
AI написал код и вышел косяк! Приложение «Охотник за сроками годности» в супермаркете с проблемой безопасности, GPS в доме работает без одежды (передаёт приватные данные)
