
AI-система запоминания MemPalace, разработанная при участии Миллы Йовович и Вики, заявила, что тест прошёл на 100% и стала вирусной, но сообщество тут же обвинило её в потенциальной читерской технике тестирования и в искажении данных. Практическая проверка показала, что достигнутые результаты преувеличены и присутствует большое количество ошибок. Команда признала недостатки и уже приступила к их исправлению.
Милла Йовович создала AI-память в виде дворца памяти, что привлекло внимание извне
Вчера (4/7) в сообществе AI было громкое событие: голливудская актриса Мила Йовович (Milla Jovovich), известная по «Обители зла» и «Пятому элементу», вместе с разработчиком Беном Сигманом (Ben Sigman) с помощью Claude Code разработала «MemPalace» — open-source систему AI для запоминания.
В течение короткого времени широко распространилась версия «голливудская звезда из другой сферы сделала проект на максимальные баллы». До сих пор MemPalace на GitHub набрала более 20k звёзд, но вскоре разработчики начали сомневаться: есть ли там что-то действительно стоящее или это просто раскрутка?
Сначала расскажем о мотивации появления MemPalace. В официальной документации сказано, что система пытается решить проблему: содержимое диалога пользователей с AI, процесс принятия решений и обсуждение архитектуры обычно исчезают после завершения рабочей сессии, из-за чего несколько месяцев труда обнуляются.
Чтобы решить эту проблему, MemPalace использует пространственную архитектуру для хранения воспоминаний: информацию чётко распределяют по «крыльям» для представляющих людей или проектов, а также по различным уровням структуры — коридорам, комнатам и ящикам — сохраняя исходный текст диалогов для последующего семантического поиска.
Разработчики утверждают, что MemPalace получила идеальные 100% в долговременном оценочном бенчмарке LongMemEval, и достигла 96.6% точности без вызова каких-либо внешних API, причём её можно полностью запускать локально, без подписки на облачные сервисы, и она оснащена диалектной системой AAAK, которая, как утверждается, обеспечивает 30-кратное без потерь сжатие.
Источник изображения: GitHub Голливудская звезда Мила Йовович создала AI-дворец памяти, что привлекло внимание извне
Коллеги и сообщество разом поставили под вопрос, тестирование и рекламные материалы содержат изъяны
Однако результаты MemPalace, якобы набравшей 100% в LongMemEval, быстро вызвали сомнения у коллег.
PenfieldLabs — компания, также создающая системы AI для памяти — указала, что заявление MemPalace о получении максимума на датасете LoCoMo математически невозможно, поскольку стандартные ответы этого датасета сами по себе содержат 99 ошибок.
Анализ PenfieldLabs показал, что 100% результата MemPalace получены за счёт установки количества проверок (retrieval) равным 50, но максимальная глубина этапов в диалогах тестового датасета составляет всего 32 раза. Это означает, что система напрямую обходит этап retrieval и передаёт все данные AI-модели для чтения.
Что касается 100% результата в LongMemEval, выяснилось, что разработчики целились в 3 конкретные проблемы, где чаще всего ошибались в ходе разработки, и написали для них специализированный исправляющий код — что вызывает подозрение, что тестирование на самом деле было подстроено под чит (cheating) на тестовом наборе.

Источник изображения: Reddit Коллега PenfieldLabs указывает, что MemPalace заявила о максимуме на датасете LoCoMo, что математически невозможно
Практическая проверка на GitHub: в бенчмарке есть элементы, вводящие в заблуждение
Пользователь GitHub hugooconnor после практической проверки написал комментарий: MemPalace заявляет о точности retrieval до 96.6%, но на деле она вообще не использует заявленную архитектуру «дворца памяти» MemPalace. hugooconnor утверждает, что их тест просто вызывает стандартную функцию базовой базы данных ChromaDB, без какого-либо участия логики классификации, на которой акцентирует внимание проект — ни «крыльев», ни логики по «комнатам» или «ящикам».
После тестирования hugooconnor выяснил, что когда система действительно включает предназначенную именно для этих «дворцов памяти» логику классификации, результаты retrieval ухудшаются. Например, в режиме «комната» точность падает до 89.4%, а при включении технологии сжатия AAAK точность ещё ниже — до 84.2%; оба значения ниже, чем производительность базовой базы данных по умолчанию.
Также hugooconnor раскритиковал метод тестирования: тестовая среда MemPalace намеренно сужает диапазон retrieval для каждого вопроса примерно до 50 диалоговых этапов, и находить ответы в крайне небольшой коллекции образцов оказывается слишком легко.
Если расширить диапазон до более чем 19,000 диалоговых этапов в реальном сценарии, точность традиционного поиска по ключевым словам падает до 30%, что показывает: текущий способ тестирования MemPalace скрывает реальную сложность поиска.
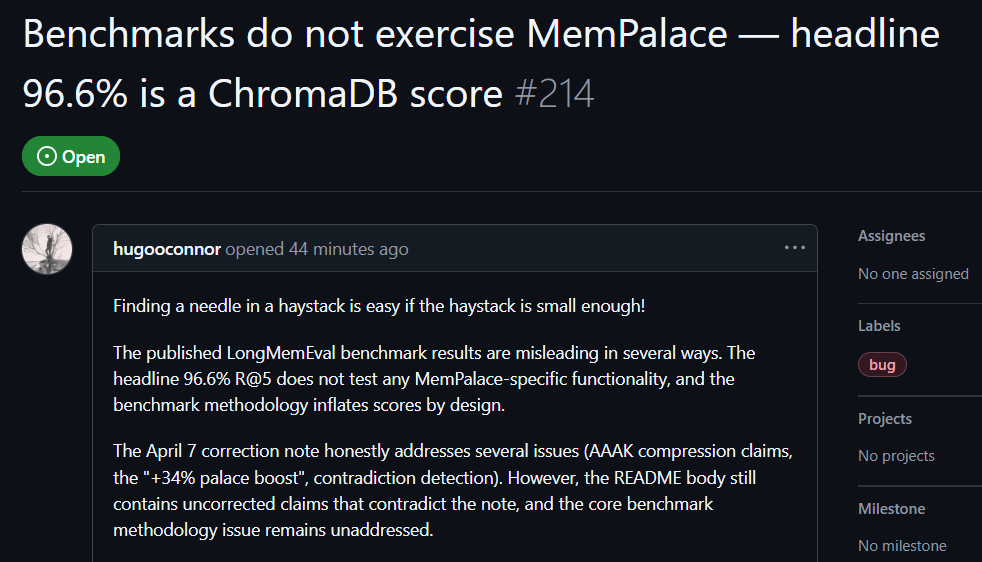
Источник изображения: GitHub Практическая проверка на GitHub пользователя: в бенчмарке MemPalace есть элементы, вводящие в заблуждение
При этом, хотя команда разработчиков уже выпустила заявление об исправлении и признала, что технология AAAK действительно подтверждена как сжатие с потерями, и пообещала скорректировать документацию и дизайн системы в соответствии с жёсткой критикой со стороны сообщества. Но основная описательная документация проекта по-прежнему сохраняет множество неподправленных преувеличений: включая заявления о 30-кратном сжатии без потерь и 34% росте retrieval, а также сравнительные графики с другими конкурентами без каких-либо источников и пояснений.
Исходный код MemPalace сталкивается с множеством багов
По мере того как всё больше разработчиков загружают тесты, на платформе GitHub появляются многочисленные отчёты об ошибках (Bug) в исходном коде MemPalace.
Пользователь cktang88 перечислил несколько серьёзных недостатков: включая невозможность работы команд сжатия, из-за чего система падает; ошибку в логике подсчёта числа слов в аннотациях; неточность статистики по «выкопанным» комнатам, а также то, что сервер при каждом вызове загружает в память все интерпретируемые данные, создавая серьёзную проблему с расходом ресурсов.
Другие указанные проблемы включают, что система жёстко записывает имена членов семьи разработчика в файл настроек по умолчанию, а также наличие принудительного верхнего лимита отображения при запросе статуса — 10k записей.
Для решения этих проблем открытое сообщество уже начало активно исправлять. Пользователь adv3nt3 отправил несколькозапросов на исправления, включая корректировку статистики «выкопанного», удаление заданных по умолчанию имён членов семьи и отложенную инициализацию времени построения knowledge graph. Впоследствии команда разработчиков также признала эти ошибки и сейчас, совместно с сообществом, постепенно решает проблемы с кодом.
Vibe Coding от Миллы Йовович — круто, а маркетинг — не очень
Что касается проекта MemPalace, пользователь Hacker News darkhanakh пришёл к следующему выводу: у MemPalace возникает ощущение OpenClaw — то есть искусственно подгоняют результаты бенчмарков, чтобы они выглядели безупречно, а затем упаковывают это в подачу какого-то крупного прорыва для маркетинга.
Он считает, что базовые технологии MemPalace, возможно, действительно интересны, но при таком подходе к тестированию с подобными изъянами и при этом ещё продвигают идею «самого высокого открытого результата в истории», это выглядит не слишком корректно. «Однако, знаете, раз уж Мила Йовович играет в Vibe Coding — я всё равно думаю, что это довольно круто».
Дальнейшее чтение:
AI написал код с ошибкой! Проблема с безопасностью в приложении «Утилизатор просрочки» (app «惜食獵人») с товарами с прилавка и сроком годности, GPS в доме полностью «обнажён»
