ミラ・ジョヴォヴィッチはAIで「満点プロジェクト」を作ったのか?開発者が実測:本当に中身があるのか、それとも誇大な宣伝・煽りなのか?

AI の記憶システム「MemPalace」を、ミラ・ジョヴォヴィッチが開発に参加しているとする同システムは、テストで満点を取って大バズりしたものの、コミュニティからテストが不正(チート)であり、データを誤導している疑いを追及された。実測の結果、効果は誇大で、かつ大量の誤りがあることが判明した。チームは欠陥を認め、現在修復に取り組んでいる。
ミラ・ジョヴォヴィッチがAI記憶の「メモリ宮殿」を構築、注目を集める
昨日(4/7)、AI界隈で大きなニュースがあった。『バイオハザード』や『第5元素』で知られるハリウッド女優のミラ・ジョヴォヴィッチ(Milla Jovovich)が、開発者の Ben Sigman とともに Claude Code を使って「MemPalace」というオープンソースのAI記憶システムを開発した、というものだ。
一気に、「ハリウッドの大スターがクロスオーバーして満点級のプロジェクトを作った」という話が広まり、MemPalace はこれまで GitHub 上で2万以上のスターを獲得している。だが、すぐに開発者コミュニティから疑問が噴出した。本当に中身があるのか、それとも誇大広告なのか?
まず、MemPalace が生まれた動機を説明しよう。公式ドキュメントによれば、現状のAIシステムでは、ユーザーとAIの対話内容、意思決定のプロセス、そしてアーキテクチャの議論が、作業セッションの終了後に消えてしまうことが多い。そのため、数か月の努力が ゼロまで落ちる(歸零)という制約があるという。
この問題を解決するため、MemPalace は空間構造を用いて記憶を保存し、情報を「人物」または「プロジェクト」を表すエリア、そして廊下・部屋・引き出しといった異なる階層の構造へ明確に分類する。さらに、対話の原文を後続の意味検索のために保持する。
開発チームは、MemPalace が長期記憶評価の基準「LongMemEval」で100%の完璧な成績を収め、かつ外部APIを一切呼び出さずに 96.6% の精度を達成していると主張している。また、クラウドサービスのサブスク不要で、完全にローカル端末で動作できるとされ、さらに「30倍のロスレス圧縮」を達成できると謳う AAAK 方言システムを搭載している。
出典:GitHub ミラ・ジョヴォヴィッチ ハリウッドの映画スターがAI記憶のメモリ宮殿を構築、注目を集める
同業者とコミュニティが一斉に疑問視、テスト手法と宣伝に瑕疵
しかし、MemPalace が LongMemEval で満点を取ったという成績は、すぐに同業者から疑いを持たれた。
同じくAIの記憶システムを制作する PenfieldLabs は、MemPalace が LoCoMo データセットで満点を獲得したと主張しているが、数学的にあり得ないと指摘した。なぜなら、このデータセットの標準解答自体に 99 個の誤りが含まれているからだ。
PenfieldLabs の分析では、MemPalace の100%成績は、検索回数を50回に設定したことに由来している。しかし、テストデータセットの対話における最高段階数はわずか32回しかない。つまりシステムは検索段階を直接すり抜け、すべてのデータをAIモデルに読み込ませていることになる。
LongMemEval での100%成績について、開発チームが「開発集中で起きる」3つの特定の問題に対し、専用の修復コードを書いていたことが判明し、テストセット不正(チート)の疑いがある。

出典:Reddit 同業者 PenfieldLabs が指摘:MemPalace は LoCoMo データセットで満点を獲得したと主張しており、数学的にあり得ない
GitHubユーザーの実測:ベンチマークにミスリード要素
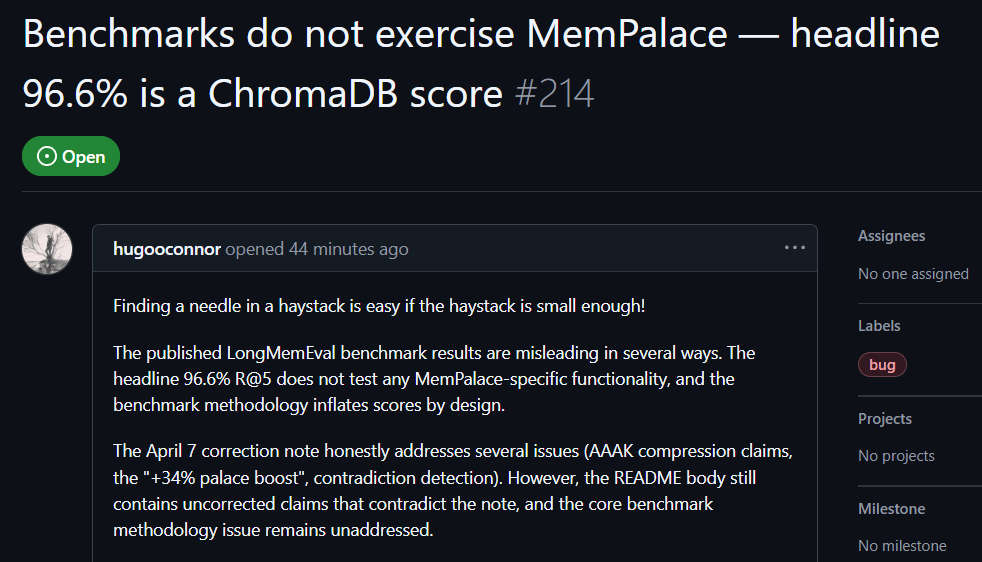
GitHub ユーザーの hugooconnor は、実測後に次のようにコメントした。MemPalace が 96.6% の検索精度だと主張しているにもかかわらず、実際には MemPalace が看板にしている「メモリ宮殿」構造をまったく使っていないという。hugooconnor によれば、彼らのテストは単に下層のデータベース「ChromaDB」のデフォルト機能を呼び出しただけで、プロジェクトが強調するエリア、部屋、引き出しといった分類ロジックには一切関与していないとのことだ。
hugooconnor のテストでは、システムが本当にこれらのメモリ宮殿専用の分類ロジックを有効にすると、検索成績はむしろ悪化することが分かった。部屋モードの例では精度が 89.4% まで低下し、さらに AAAK の圧縮技術を有効にすると精度は 84.2% まで下がり、いずれもデフォルトのデータベース性能を下回った。
hugooconnor はテスト方法も批判している。MemPalace のテスト環境は、各問題の検索範囲を意図的に約50の対話ステージにまで縮小し、極めて小さなサンプルデータベースの中から答えを探すのは簡単すぎるという。
検索範囲を現実シナリオの 19,000 以上の対話ステージに広げると、従来のキーワード検索の精度は 30% まで大幅に下がるはずで、MemPalace が現在のテスト方式で実際の検索の難しさを隠していることが示される。
出典:GitHub GitHubユーザーの実測:MemPalace のベンチマークにはミスリード要素
また、開発チームが訂正声明をすでに出し、AAAK 技術が実際には「ロスあり圧縮(有損圧縮)」として検証されており、コミュニティの厳しい批判を踏まえて説明ドキュメントとシステム設計を修正すると約束しているにもかかわらず、プロジェクトの主要な説明ドキュメントには依然として未修正の誇大表現が複数残っている。たとえば「30倍のロスレス圧縮」や「34% の検索向上」などの主張であり、さらに他の競合相手との比較グラフに関しても、出典がまったく示されていない。
MemPalace の元コードには複数の Bug がある
より多くの開発者がテストをダウンロードするにつれて、GitHub 上では MemPalace の元コードに関する大量のバグ報告が現れている。
ユーザーの cktang88 は重大な不備を列挙している。圧縮コマンドが動作せずシステムがクラッシュする、要約の文字数計算ロジックの誤り、部屋を掘り起こす統計データが不正確であること、そしてサーバーが呼び出しのたびにすべての解釈データをメモリに読み込むため、深刻なリソース消費問題が生じていることなどが含まれる。
ほかに指摘されている問題として、システムが開発者の家族メンバー名をデフォルト設定ファイルに強制的に書き込むことや、照会状態で 1 万件のデータを超える場合の表示上限が強制されていることが挙げられる。
これらの問題に対して、オープンソースコミュニティはすでに積極的に修復を始めている。**ユーザー adv3nt3 が複数の修復要求を提出し、掘り起こしの統計データを修正し、デフォルトの家族メンバー名を削除し、知識グラフの初期化時間を遅延させることを含む。**開発チームも後にこれらの誤りを認めており、コミュニティとの協力により段階的にコードの問題を解決していっている。
ミラ・ジョヴォヴィッチのVibe Codingはかっこいい、マーケはかっこよくない
MemPalace というプロジェクトについて、Hacker News のユーザー darkhanakh は次のような結論を下している。MemPalace は OpenClaw っぽい印象を与える。つまり、人為的にベンチマーク結果を操作して完璧に見せ、その後それを何らかの重大なブレークスルーとして包んでマーケティングする、ということだ。
彼は、MemPalace の基盤技術自体は確かに面白い可能性があるが、テスト手法にこのような瑕疵がある状況で、しかも「史上公開最高スコア」を掲げて宣伝しているのはあまり適切ではないと考えている。「とはいえ、ミラ・ジョヴォヴィッチが Vibe Coding をやってる件については、僕はやっぱり結構クールだと思う。」
続きの読み物:
AIがコード作ったらトラブル! コンビニの期限間近アプリ「惜食獵人」がセキュリティ問題で炎上、家のGPSが丸見えに