ミラ・ジョバ・ヴィキはAIで「満点プロジェクト」を作った? 開発者が実測:本当に中身があるのか、それとも誇大な煽りなのか?

ミラ・ジョヴォヴィッチが開発に参加したAIメモリーシステム MemPalace は、テストで満点を取って大バズりしたと主張したものの、コミュニティからテストの不正とデータのミスリードを疑われて排除された。実測では効果が誇大で、多数の誤りが見つかり、チームは不備を認めて修復に取り組んでいる。
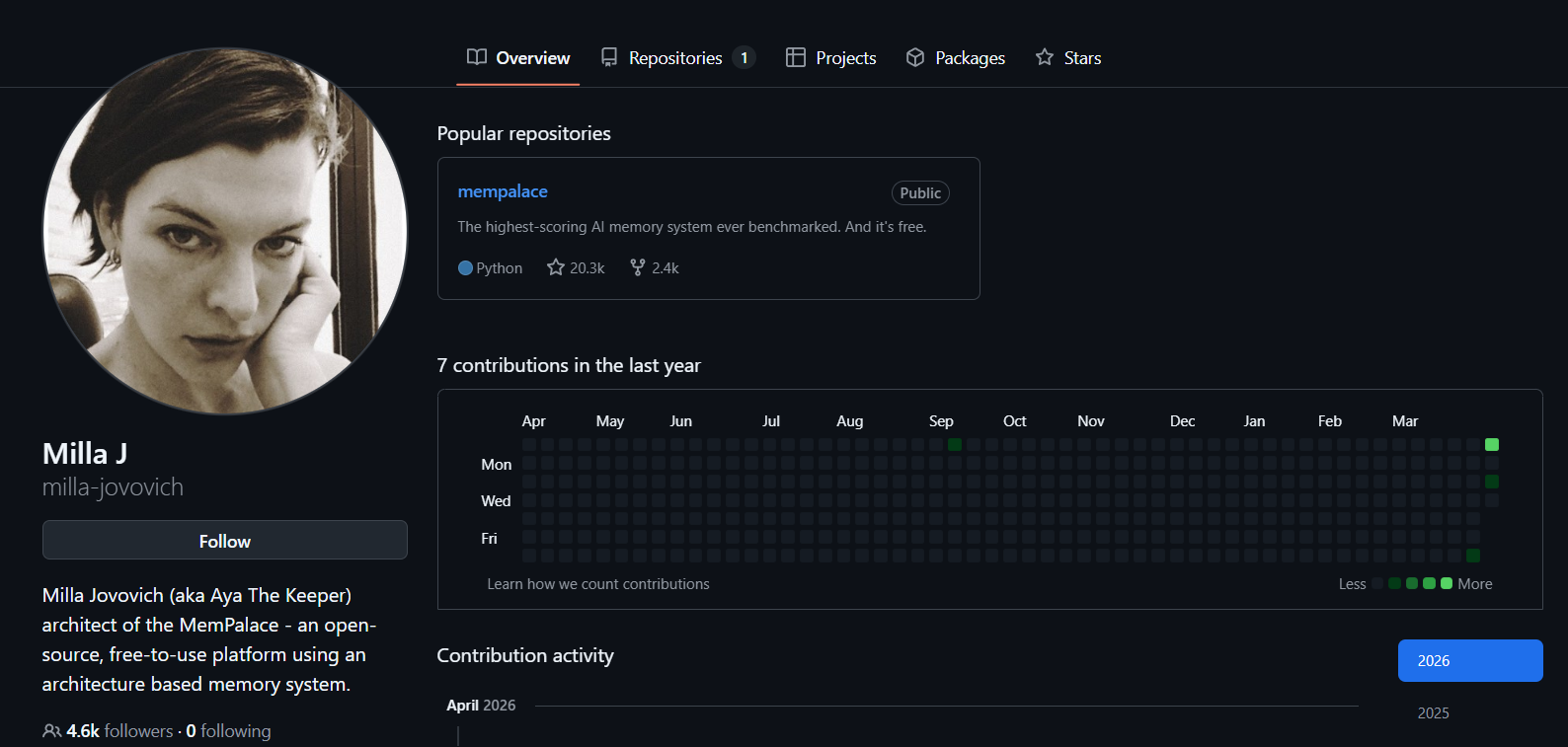
ミラ・ジョヴォヴィッチがAIメモリー宮殿を構築、外部の注目を集める
昨日(4/7)AI界隈に、ハリウッド女優ミラ・ジョヴォヴィッチ(Milla Jovovich)(『バイオハザード』『第5元素』で知られる)が、開発者Ben Sigmanと Claude Code を使って「MemPalace」オープンソースAIメモリーシステムを開発した、という大きなニュースがあった。
一時、「ハリウッドの大スターが異分野に挑戦して満点プロジェクトを作った」という説が広く流れ、MemPalaceは今日までGitHub上で2万を超えるスターを獲得しているが、すぐに開発者コミュニティから疑問が投げかけられた。本当に中身があるのか、それとも煽りなのか?
まず、MemPalaceが生まれた動機について説明しよう。公式ドキュメントによれば、現在のAIシステムは、ユーザーとAIの会話内容、意思決定のプロセス、そしてアーキテクチャの議論が、作業セッションの終了後に消えてしまい、その結果、数か月の努力が無駄になるという制約があるからだ。
この問題を解決するため、MemPalaceは空間アーキテクチャを採用して記憶を保存し、情報を、人物やプロジェクトを代表する翼区、そして廊下、部屋、引き出しなどの異なるレベルの構造に明確に分類することで、後続の意味論的検索に備えて会話の原文を保持する。
開発チームは、MemPalaceが長期記憶評価ベンチマーク LongMemEval において100%の完璧な成績を収め、さらに外部APIを一切呼び出さずに96.6%の正確率に到達したと主張しており、完全にローカルで動作でき、クラウドサービスのサブスクリプションも不要で、さらに30倍のロスレス圧縮が可能だとするAAAKの方言システムを搭載しているという。
画像出典:GitHub ミラ・ジョヴォヴィッチがAIメモリー宮殿を構築、外部の注目を集める
同業とコミュニティが一斉に疑問視、テスト手法と宣伝に瑕疵
しかし、LongMemEvalで満点を取ったというMemPalaceの成績は、すぐに同業からの疑念を招いた。
同じくAIメモリーシステムを制作している PenfieldLabs は、MemPalaceが LoCoMo データセットで満点を獲得したと主張しているが、数学的に起こり得ないと指摘する。同データセットの正解自体に99件の誤りが含まれているためだ。
PenfieldLabs の分析によれば、MemPalaceの100%の成績は、検索回数を50回に設定したことによるものだが、テストデータセットの会話が到達する最大段階はわずか32回に過ぎない。つまりシステムは検索段階を直接すり抜け、すべてのデータをAIモデルに読み込ませている。
LongMemEvalでの100%成績については、開発チームが開発集中で出てきた3つの特定の問題に対して専用の修復コードを書いており、テストセットの不正(チート)の疑いがあることが判明した。

画像出典:Reddit 同業PenfieldLabsは、MemPalaceがLoCoMoデータセットで満点を獲得したと主張しているが、数学的に起こり得ないと指摘している
GitHubユーザーの実測、ベンチマークにはミスリード要素がある
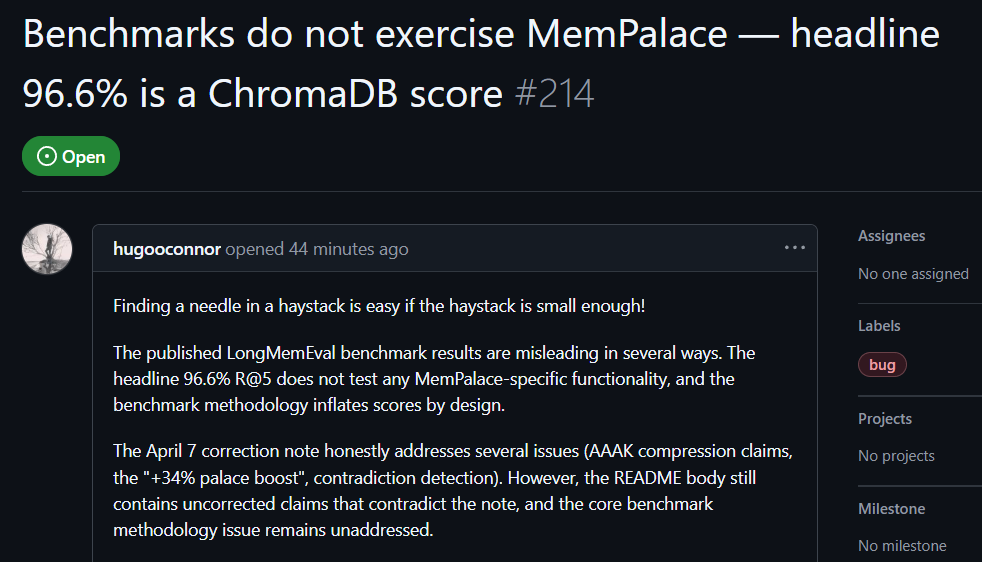
GitHubユーザー hugooconnor は実測したうえでコメントし、MemPalace が最大96.6%の検索精度を主張しているが、実際には MemPalace が売りにするメモリー宮殿のアーキテクチャはまったく使われていないとした。hugooconnor によれば、彼らのテストは単に基盤のデータベース ChromaDB のデフォルト機能を呼び出しただけで、プロジェクトが強調する翼区、部屋、引き出しなどの分類ロジックにはまったく関わっていないという。
hugooconnor はテスト後、システムが本当にこれらのメモリー宮殿専用の分類ロジックを有効にすると、検索成績がむしろ低下することを見つけた。部屋モードの例では精度が89.4%まで下がり、AAAK圧縮技術を有効にすると精度はさらに84.2%まで下がり、どちらもデフォルトのデータベースのパフォーマンスを下回った。
hugooconnor はまたテスト手法も批判している。MemPalaceのテスト環境は、各問題の検索範囲を意図的に約50の会話段階に縮小し、極めて小さいサンプルのデータベース内で答えを探すのはあまりにも簡単だという。
検索範囲を実際の状況にある19,000以上の会話段階まで広げると、従来のキーワード検索の精度は 30% まで急落する。これは、MemPalace の現在のテスト方法が、実際の検索の難題を隠していることを示している。
画像出典:GitHub GitHubユーザーの実測、MemPalaceのベンチマークにはミスリード要素がある
また、開発チームはすでに訂正声明を出し、AAAK技術が実際にはロスあり圧縮であることを認め、さらにコミュニティの厳しい批判に基づいて、ドキュメントとシステム設計を修正すると約束している一方で、プロジェクトの主要な説明ドキュメントには依然として複数の未修正の誇大表現が残っている。これには、30倍のロスレス圧縮と34%の検索向上をうたうことが含まれ、さらに他の競合相手との比較図表も出典がまったく示されていない。
MemPalaceの元コードには複数のBugがある
より多くの開発者がテストのためにダウンロードするにつれ、現在GitHub上にはMemPalaceの元コードに関する大量のBug報告が出ている。
ユーザー cktang88 は多くの重大な欠陥を挙げており、圧縮コマンドが動作せずシステムがクラッシュする、要約の文字数計算ロジックの誤り、部屋掘削の統計データが不正確であること、そしてサーバーが毎回の呼び出しで全ての解釈データをメモリに読み込むため、深刻なリソース消費の問題が生じることなどが含まれる。
他にも指摘されている問題として、システムが開発者の家族メンバー名をデフォルト設定ファイルに強制的に書き込むこと、そして問い合わせステータス時に1万件のデータを表示する強制上限が存在することがある。
これらの問題に対し、オープンソース・コミュニティは積極的に修復を始めている。**ユーザー adv3nt3 が複数の修復リクエストを提出しており、掘削統計データの修正、デフォルトの家族メンバー名の削除、知識グラフの初期化時間の遅延などが含まれている。**開発チームも後続でこれらの誤りを認めており、コミュニティ協力のもとでコードの問題を段階的に解決しているところだ。
ミラ・ジョヴォヴィッチのVibe Codingはかっこいい、マーケティングはかっこよくない
MemPalaceというプロジェクトについて、Hacker Newsのユーザー darkhanakh が次のような結論を下した。MemPalaceはOpenClawのような印象を与える。つまり、人為的にベンチマーク結果を操作して完璧に見せ、その後それを何らかの重大なブレイクスルーとして包み込みマーケティングする、ということだ。
彼は、MemPalaceの基盤技術は確かに興味深い可能性があるが、テスト方法にこの種の欠陥がある状態で、「史上公開最高点」を打ち出して宣伝するのはあまりにも不適切だと考えている。「とはいえ、ミラ・ジョヴォヴィッチがVibe Codingをやってるって件、それでも僕はかなりクールだと思う。」
関連記事:
AIがプログラム作成でトラブル!コンビニの期限切れ商品アプリ「惜食獵人」で資産セキュリティ問題、家のGPSが丸見えに