
Le système de mémoire IA MemPalace, développé par Milla Jovovich, affirme avoir obtenu un score parfait lors de ses tests et est devenu viral, mais la communauté l’a rapidement accusé de tricher et de tromper les données. Des tests en conditions réelles ont révélé des performances exagérées et de nombreuses erreurs ; l’équipe a reconnu les lacunes et travaille à les corriger.
Milla Jovovich crée un palais de la mémoire pour l’IA, suscitant l’attention du public
Hier (4/7), il y a eu une grande nouvelle dans le milieu de l’IA : l’actrice hollywoodienne Milla·Jovovich, connue pour Resident Evil et Le Cinquième Élément, a développé « MemPalace », un système open source de mémoire IA, avec le développeur Ben Sigman, en s’aidant de Claude Code.
Pendant un moment, l’idée selon laquelle « une star hollywoodienne se lance dans un projet au score parfait » s’est largement répandue ; jusqu’à présent, MemPalace compte plus de 20k étoiles sur GitHub, mais cela a rapidement déclenché des doutes de la part de la communauté des développeurs : il y a-t-il vraiment du fond ou s’agit-il de promotion ?
Commençons par expliquer la motivation de la naissance de MemPalace : d’après la documentation officielle, l’objectif est de résoudre la limite actuelle des systèmes IA, où le contenu des conversations avec l’IA, les processus de décision et les discussions sur l’architecture disparaissent généralement une fois la session de travail terminée, entraînant une perte de plusieurs mois de travail acharné, chute à zéro.
Pour résoudre ce problème, MemPalace utilise une architecture spatiale pour stocker la mémoire, en classant clairement les informations dans des ailes représentant les personnes ou les projets, ainsi que dans des structures de différents niveaux comme les couloirs, les pièces et les tiroirs, tout en conservant le texte original de la conversation pour une recherche sémantique ultérieure.
L’équipe de développement affirme que MemPalace obtient un score parfait de 100 % dans le barème d’évaluation de la mémoire à long terme LongMemEval, et qu’elle atteint un taux de précision de 96,6 % sans appeler n’importe quelle API externe ; de plus, le système peut fonctionner entièrement en local, sans avoir besoin de s’abonner à des services cloud, et intègre un système de dialecte AAAK annoncé comme pouvant atteindre 30 fois de compression sans perte.
Source de l’image : GitHub La star hollywoodienne Milla Jovovich crée un palais de la mémoire pour l’IA, suscitant l’attention du public
Les pairs et la communauté mettent aussi en doute l’ensemble, la méthode de test et la promotion entachées
Cependant, le résultat de MemPalace à 100 % dans LongMemEval a vite suscité des doutes de la part des pairs.
PenfieldLabs, une entreprise qui produit aussi des systèmes de mémoire pour l’IA, indique que l’affirmation de MemPalace selon laquelle elle obtient un score parfait dans le jeu de données LoCoMo est mathématiquement impossible, car les réponses standards de ce jeu de données contiennent elles-mêmes 99 erreurs.
L’analyse de PenfieldLabs montre que le score de 100 % de MemPalace provient du fait que le nombre de récupérations est fixé à 50, mais que le nombre maximal d’étapes de dialogue dans le jeu de données de test est seulement de 32 ; cela signifie que le système contourne directement l’étape de récupération et confie toutes les données au modèle IA pour lecture.
Concernant le score de 100 % à LongMemEval, l’équipe de développement a été identifiée comme ayant ciblé 3 problèmes spécifiques où s’est concentrée l’erreur, en écrivant un code de correction dédié, ce qui fait suspecter une triche sur l’ensemble de test.

Source de l’image : Reddit Des pairs PenfieldLabs indiquent que, selon MemPalace, un score parfait est obtenu dans le jeu de données LoCoMo ; c’est mathématiquement impossible
Tests en conditions réelles par des utilisateurs GitHub : composants de la référence trompeurs
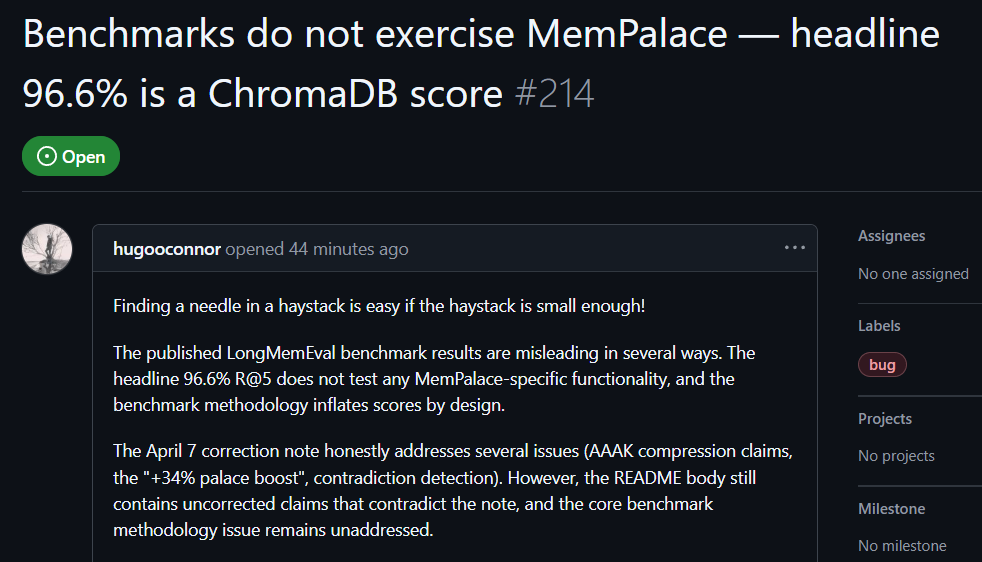
L’utilisateur GitHub hugooconnor a commenté après des tests en conditions réelles : lorsque MemPalace annonce jusqu’à 96,6 % de précision de récupération, en réalité, l’architecture de palais de la mémoire mise en avant par MemPalace n’est totalement pas utilisée. hugooconnor affirme que leurs tests se contentent d’appeler la fonctionnalité par défaut de la base de données sous-jacente ChromaDB, sans aucunement recourir aux logiques de classification mises en avant par le projet, comme celles des ailes, des pièces ou des tiroirs.
Après test, hugooconnor constate qu’au moment où le système active réellement ces logiques de classification spécifiques au palais de la mémoire, les résultats de récupération diminuent au contraire. Par exemple, en mode pièces, la précision chute à 89,4 % ; et une fois la technologie de compression AAAK activée, la précision baisse encore à 84,2 % ; dans les deux cas, c’est inférieur aux performances de la base de données par défaut.
hugooconnor a aussi critiqué la méthode de test : l’environnement de test de MemPalace réduit volontairement la plage de récupération de chaque question à environ 50 étapes de dialogue, ce qui rend la recherche de la réponse dans un tout petit échantillon beaucoup trop facile.
Si l’on élargit la plage à plus de 19 000 étapes de dialogue correspondant à des scénarios réels, la précision de la recherche par mots-clés classique chute à 30 %, ce qui montre que la méthode de test actuelle de MemPalace masque la véritable difficulté du problème de recherche.
Source de l’image : GitHub Tests en conditions réelles par un utilisateur GitHub : composants de la référence trompeurs pour MemPalace
En même temps, bien que l’équipe de développement ait publié une déclaration de correction, en admettant que la technologie AAAK a bien été validée comme une compression avec pertes, et en promettant d’ajuster la documentation et la conception du système en fonction des critiques sévères de la communauté, la documentation principale du projet conserve malgré tout plusieurs affirmations exagérées non corrigées, notamment l’annonce d’une compression 30 fois sans pertes et d’une amélioration de 34 % de la récupération, et les diagrammes comparatifs avec d’autres concurrents manquent également totalement de sources et d’origines.
Le code source de MemPalace fait face à plusieurs bugs
À mesure que de plus en plus de développeurs téléchargent les tests, de nombreux signalements de bugs concernant le code source de MemPalace apparaissent sur la plateforme GitHub.
L’utilisateur cktang88 liste plusieurs défauts graves, dont des instructions de compression qui ne fonctionnent pas et provoquent un crash du système, une erreur dans la logique de calcul du nombre de mots des résumés, des données statistiques inexactes pour l’extraction des pièces, ainsi qu’un problème où, à chaque appel, le serveur charge l’ensemble des données d’interprétation en mémoire, entraînant une consommation de ressources très importante.
Parmi les autres problèmes signalés, on trouve aussi le fait que le système inscrit de force les noms des membres de la famille des développeurs dans le fichier de configuration par défaut, ainsi qu’une limite d’affichage forcée maximale de 10k entrées lors des requêtes d’état.
Pour résoudre ces problèmes, la communauté open source a commencé à les corriger activement. L’utilisateur adv3nt3 soumet plusieursdemandes de correction, notamment en corrigeant les données statistiques de l’extraction, en supprimant les noms des membres de la famille par défaut, et en repoussant le moment d’initialisation du graphe de connaissances. L’équipe de développement reconnaît aussi ces erreurs par la suite et travaille, grâce à la collaboration avec la communauté, à résoudre progressivement les problèmes du code.
Le Vibe Coding de Milla Jovovich, c’est cool ; la manière de faire du marketing, moins
Concernant ce projet MemPalace, un internaute de Hacker News, darkhanakh, tire une conclusion : MemPalace donne une sensation de déjà-vu d’OpenClaw, c’est-à-dire qu’on manipule artificiellement les résultats des tests de référence (benchmark) pour qu’ils paraissent parfaits, puis on les emballer pour les commercialiser comme une sorte de percée majeure.
Il pense que la technologie sous-jacente de MemPalace est peut-être effectivement intéressante, mais dans la mesure où la méthode de test comporte ce genre de défauts, et qu’en plus on met en avant la « meilleure note la plus élevée jamais rendue publique » pour faire de la publicité, ce n’est vraiment pas très approprié. « Mais bon, le fait que Milla Jovovich s’amuse avec le Vibe Coding, je trouve quand même que c’est plutôt cool. »
Lecture complémentaire :
AI écrit du code en ratant ! L’appli « chasseurs de pertes » des produits à date courte en supermarché révèle un problème de cybersécurité, le GPS à la maison diffuse toute la nudité
